Developing Carbon, I haven’t had the time to play much with it myself. 🙂 One of the most essential features in a disassembler is the capability to let the users write scripts and modify the disassembly itself. Carbon has a rich SDK and this is a little tutorial to introduce a bit how it works.
Before trying out any of the scripts in this tutorial, make sure to update to the newest 3.0.2 version, as we just fixed a few bugs related to the Carbon Python SDK.
So let’s start!
I wrote a small program with some encrypted strings.
#include <stdio.h>
unsigned char s1[13] = { 0x84, 0xA9, 0xA0, 0xA0, 0xA3, 0xE0, 0xEC, 0xBB, 0xA3, 0xBE, 0xA0, 0xA8, 0xED };
unsigned char s2[17] = { 0x98, 0xA4, 0xA5, 0xBF, 0xEC, 0xA5, 0xBF, 0xEC, 0x9F, 0x9C, 0x8D, 0x9E, 0x98, 0x8D, 0xED, 0xED, 0xED };
unsigned char s3[11] = { 0x82, 0xA3, 0xE0, 0xEC, 0xBE, 0xA9, 0xAD, 0xA0, 0xA0, 0xB5, 0xE2 };
char *decrypt(unsigned char *s, size_t n)
{
for (size_t i = 0; i < n; i++)
s[i] ^= 0xCC;
return (char *) s;
}
#define DS(s) decrypt(s, sizeof (s))
int main()
{
puts(DS(s1));
puts(DS(s2));
puts(DS(s3));
return 0;
}
The decryption function is super-simple, but that’s not important for our purposes.
I disassembled the debug version of the program, because I didn’t want release optimizations like the decrypt function getting inlined. Not that it matters much, but in a real-world scenario a longer decryption function wouldn’t get inlined.
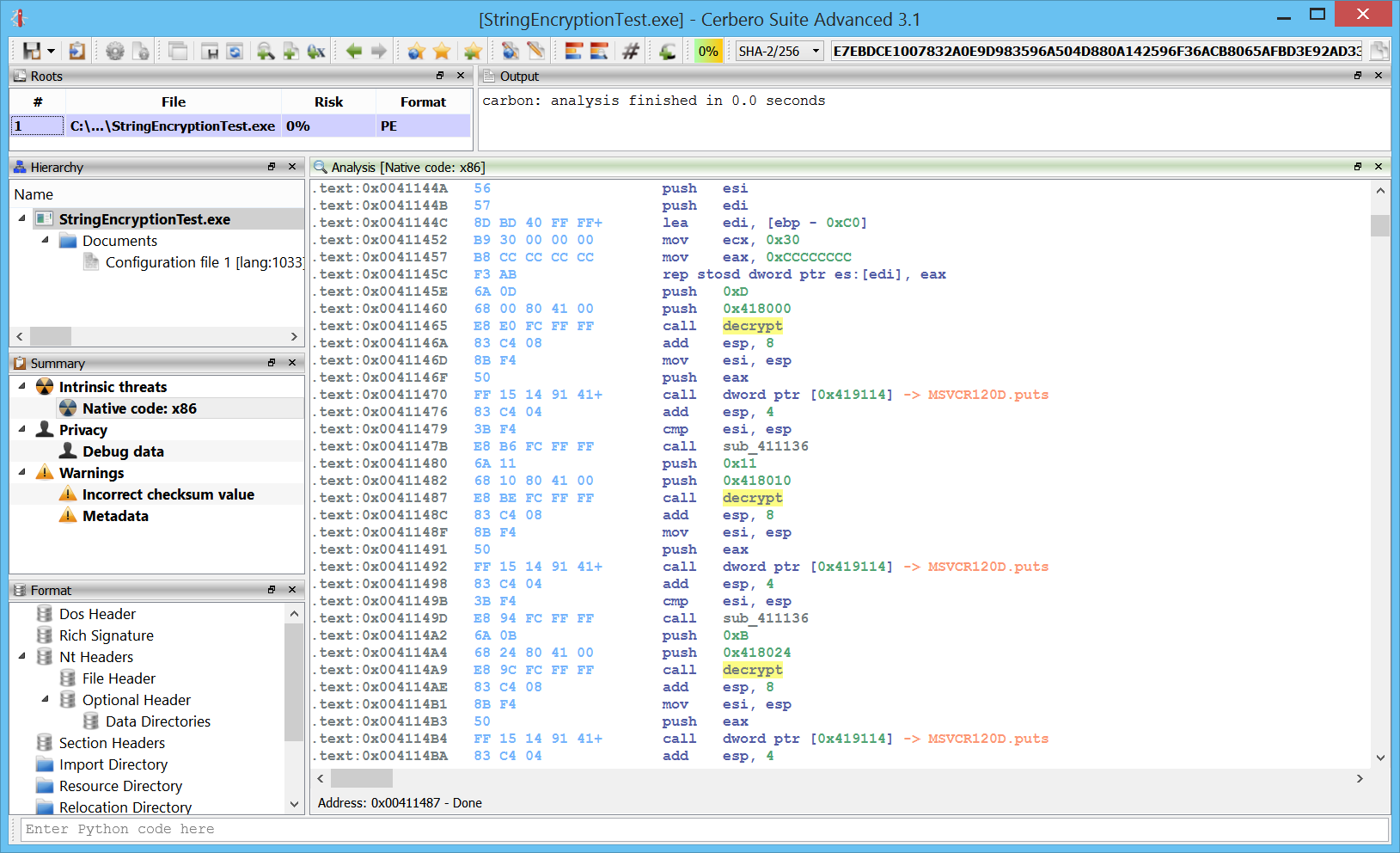
By going to the decrypt function, we end up to a jmp which points to the actual function code.
.text:0x0041114A decrypt proc start .text:0x0041114A ; CODE XREF: 0x00411465 .text:0x0041114A ; CODE XREF: 0x00411487 .text:0x0041114A ; CODE XREF: 0x004114A9 .text:0x0041114A E9 71 02 00 00 jmp sub_4113C0
At this point, the SDK offers us many possible approaches to find all occurrences of encrypted strings. We could, for instance, enumerate all disassembled instructions. But that’s not very fast. A better approach is to get all xrefs to the decrypt function and then proceed from there.
First we get the current view.
v = proContext().getCurrentView() ca = v.getCarbon() db = ca.getDB()
Then we get all xrefs to the decrypt function.
xrefs = db.getXRefs(0x0041114A, True)
We enumerate all xrefs and we extract address and length of each string.
it = xrefs.iterator()
while it.hasNext():
xref = it.next()
# retrieve address and length of the string
buf = ca.read(xref.origin - 6, 6)
slen = buf[0]
saddr = struct.unpack_from("<I", buf, 2)[0]
We decrypt the string.
s = ca.read(saddr, slen)
s = bytes([c ^ 0xCC for c in s]).decode("utf-8")
At this point we can add a comment to each push of the string address with the decrypted string.
comment = caComment() comment.address = xref.origin - 5 comment.text = s db.setComment(comment)
As final touch, we tell the view to update, in order to show us the changes we made to the underlying database.
v.update()
Here’s the complete script which we can execute via Ctrl+Alt+R (we have to make sure that we are executing the script while the focus is on the disassembly view, otherwise it won’t work).
from Pro.UI import proContext
from Pro.Carbon import caComment
import struct
def decrypt_strings():
v = proContext().getCurrentView()
ca = v.getCarbon()
db = ca.getDB()
# get all xrefs to the decryption function
xrefs = db.getXRefs(0x0041114A, True)
it = xrefs.iterator()
while it.hasNext():
xref = it.next()
# retrieve address and length of the string
buf = ca.read(xref.origin - 6, 6)
slen = buf[0]
saddr = struct.unpack_from("<I", buf, 2)[0]
# decrypt string
s = ca.read(saddr, slen)
s = bytes([c ^ 0xCC for c in s]).decode("utf-8")
# comment
comment = caComment()
comment.address = xref.origin - 5
comment.text = s
db.setComment(comment)
# update the view
v.update()
decrypt_strings()
It will result in the decrypted strings shown as comments.
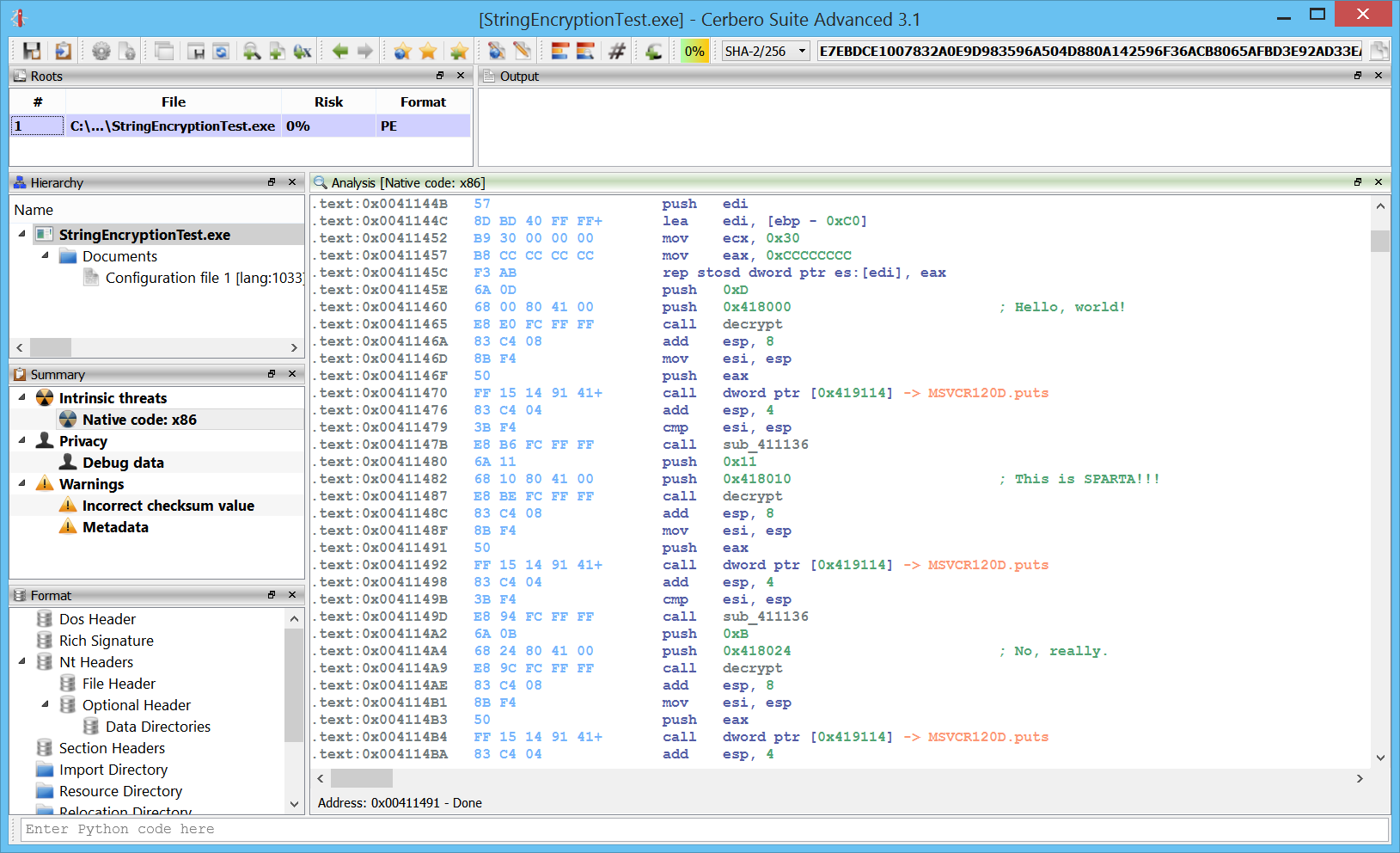
This could be the end of the tutorial. However, in the upcoming 3.1 version I just added the capability to overwrite bytes in the disassembly. This feature is both available from the context menu (Edit bytes) under the shortcut “E” or from the SDK via the Carbon write method.
What it does is to patch bytes in the database only: the original file won’t be touched!
So let’s modify the last part of the script above:
# decrypt string
s = ca.read(saddr, slen)
s = bytes([c ^ 0xCC for c in s])
# overwrite in disasm
ca.write(saddr, s)
Please notice that I removed the “.decode(“utf-8″)” part of the script, as now I’m passing a bytes object to the write method.
This is the result.
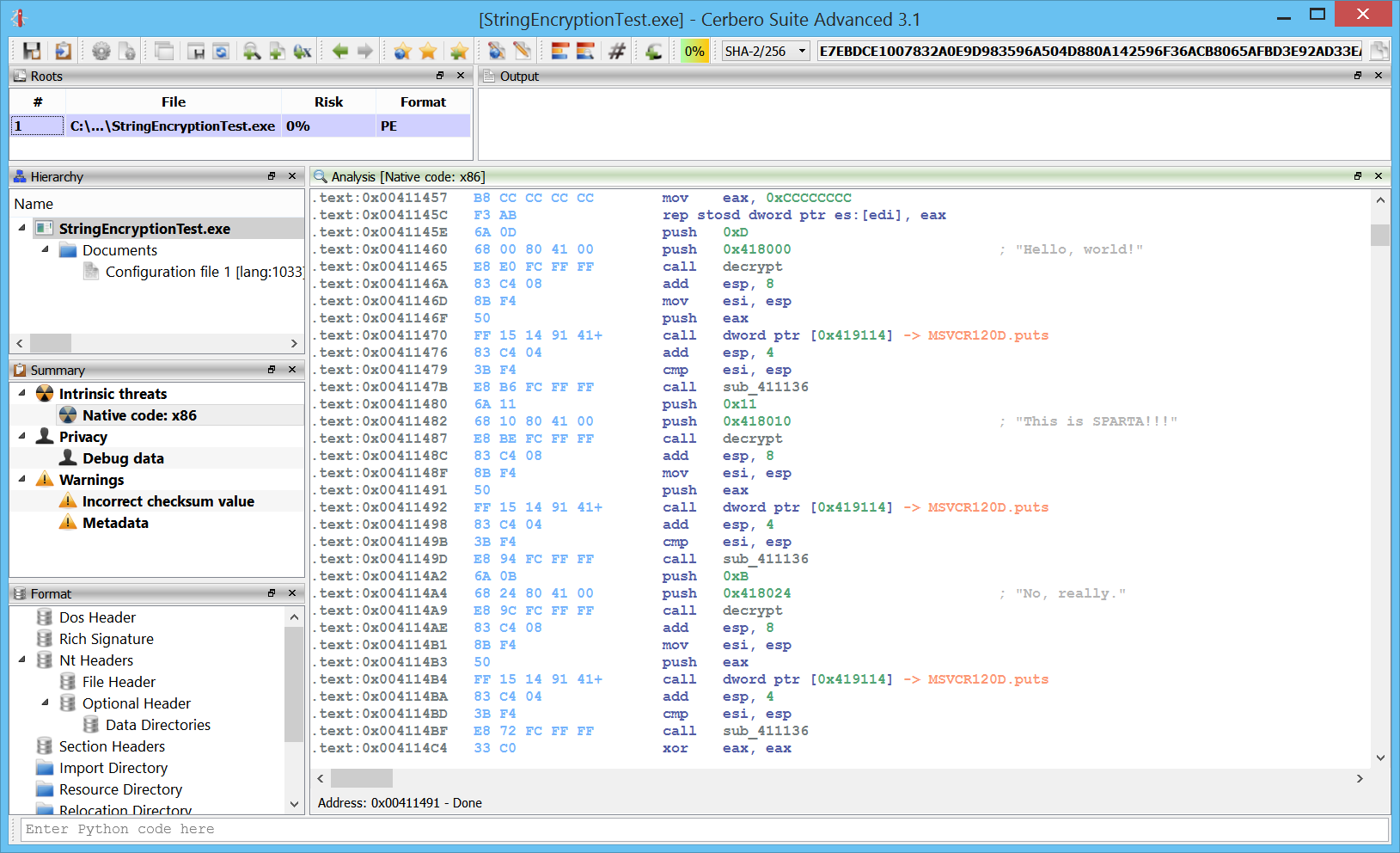
.text:0x0041145E push 0xD .text:0x00411460 push 0x418000 ; "Hello, world!" .text:0x00411465 call decrypt .text:0x0041146A add esp, 8 .text:0x0041146D mov esi, esp .text:0x0041146F push eax .text:0x00411470 call dword ptr [0x419114] -> MSVCR120D.puts .text:0x00411476 add esp, 4 .text:0x00411479 cmp esi, esp .text:0x0041147B call sub_411136 .text:0x00411480 push 0x11 .text:0x00411482 push 0x418010 ; "This is SPARTA!!!" .text:0x00411487 call decrypt .text:0x0041148C add esp, 8 .text:0x0041148F mov esi, esp .text:0x00411491 push eax .text:0x00411492 call dword ptr [0x419114] -> MSVCR120D.puts .text:0x00411498 add esp, 4 .text:0x0041149B cmp esi, esp .text:0x0041149D call sub_411136 .text:0x004114A2 push 0xB .text:0x004114A4 push 0x418024 ; "No, really." .text:0x004114A9 call decrypt .text:0x004114AE add esp, 8 .text:0x004114B1 mov esi, esp .text:0x004114B3 push eax .text:0x004114B4 call dword ptr [0x419114] -> MSVCR120D.puts
I didn’t add any comment: the strings are now detected automatically by the disassembler and shown as comments.
Perhaps for this particular task it’s better to use the first approach, instead of changing bytes in the database, but the capability to overwrite bytes becomes important when dealing with self-modifying code or other tasks.
I hope you enjoyed this first tutorial. 🙂
Happy hacking!