We’re happy to announce the release of Cerbero Suite 6.1 and Cerbero Engine 3.1!
This release contains many improvements to our PDF support.
New JBIG2 Library
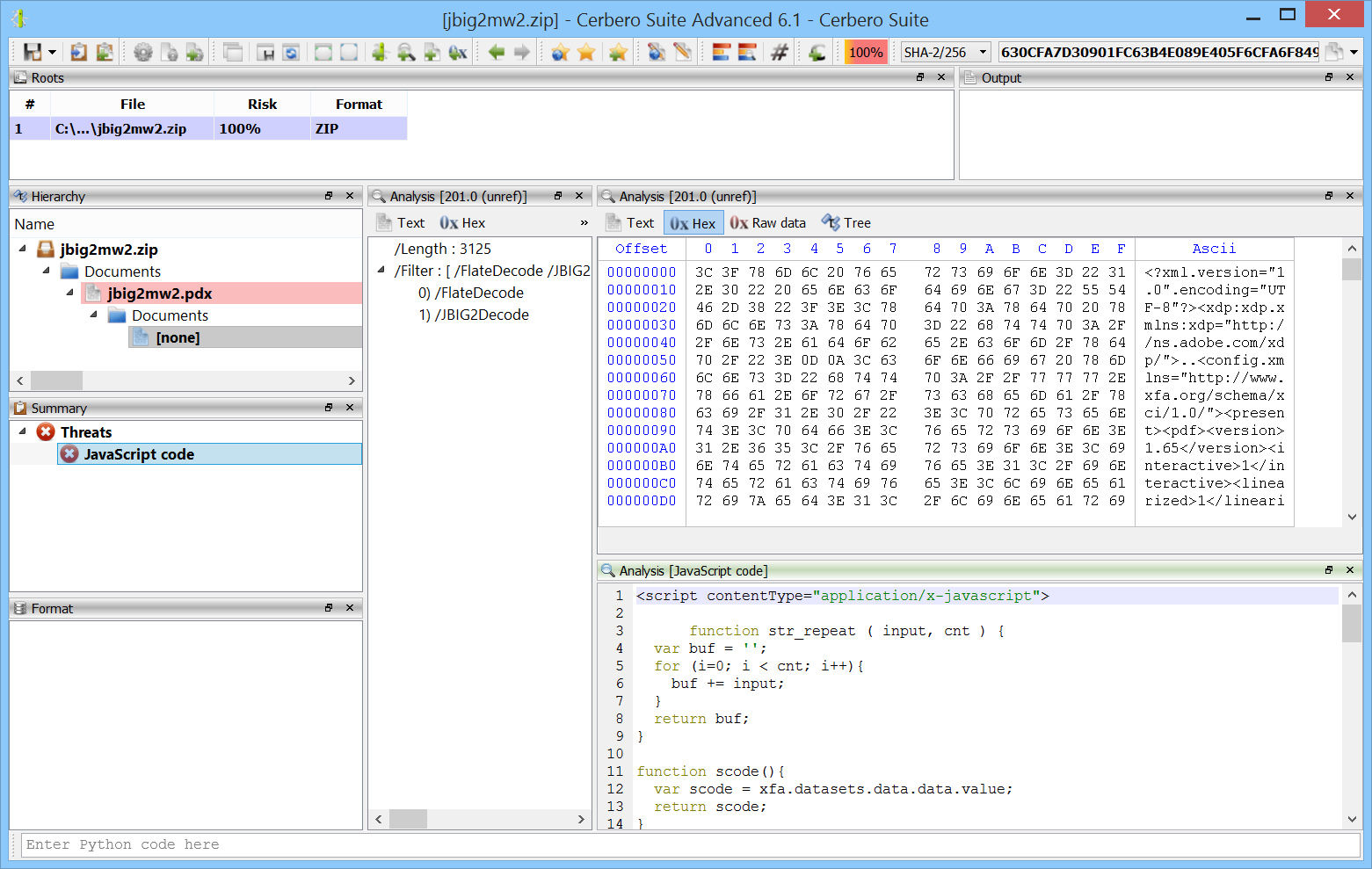
Our PDF support has been featuring the capability to decode JBIG2 streams for many years.
JBIG2 is an imperative file format which has been demonstrated can be Turing complete. In fact, one of the most sophisticated exploits has been created exploiting a JBIG2 library in iOS. The exploit mentioned in the article creates over 70,000 segments to create a small virtual machine in logical operations defined by JBIG2.
In a recent release we made our already hardened JBIG2 decoding support even more secure by relegating it to a different process and constraining it to a time threshold.
This release features a completely rewritten JBIG2 library. Not only is it faster than the previous one, but it also has constraints on allocation and processing time by default. Therefore, now the library is being run again in the same process and it’s even faster than before.
For the customers of our engine: it is still possible to use the old JBIG2 library:
pdf.SetJBIG2LibraryVersion(1)
By default version 2 (the new library) is used.
JPEG & JPEG2000 Decoders
We added support for /DCTDecode and /JPXDecode filters in PDFs. These two filters represent JPEG and JPEG2000 respectively. What it means is that we convert images compressed in JPEG to raw data when decoding streams.
The reason for this is that it is possible to encode a JavaScript script using a grayscale JPEG image. It has been done as a proof of concept by Dénes Olivér Óvári and we’ll detail this in the next release of our e-zine.
We want to thank Dénes for his research and for providing us with his proof of concept!
For the customers of our engine: in case you are not interested in supporting these filters, we have introduced a mechanism to individually disable filters:
pdf.EnableFilter(PDFObject.FilterType_DCTDecode, False) pdf.EnableFilter(PDFObject.FilterType_JPXDecode, False)
PDF SDK Catalog Support
We introduced SDK support for parsing the pages in a PDF:
objtable = obj.GetObjectTable()
# computes the catalog tree
cat = obj.ComputeCatalogTree(objtable)
# flattens the tree into a list
pages = obj.FlattenCatalogTree(cat)
page_count = pages.size()
print("Number of pages:", page_count)
for i in range(page_count):
print(" Page:", i + 1, "- Object:", obj.ObjectToString(objtable, pages.at(i)))
Sample output:
Number of pages: 12
Page: 1 - Object: 5.0
Page: 2 - Object: 71.0
Page: 3 - Object: 100.0
Page: 4 - Object: 113.0
Page: 5 - Object: 132.0
Page: 6 - Object: 154.0
Page: 7 - Object: 172.0
Page: 8 - Object: 210.0
Page: 9 - Object: 236.0
Page: 10 - Object: 277.0
Page: 11 - Object: 286.0
Page: 12 - Object: 320.0
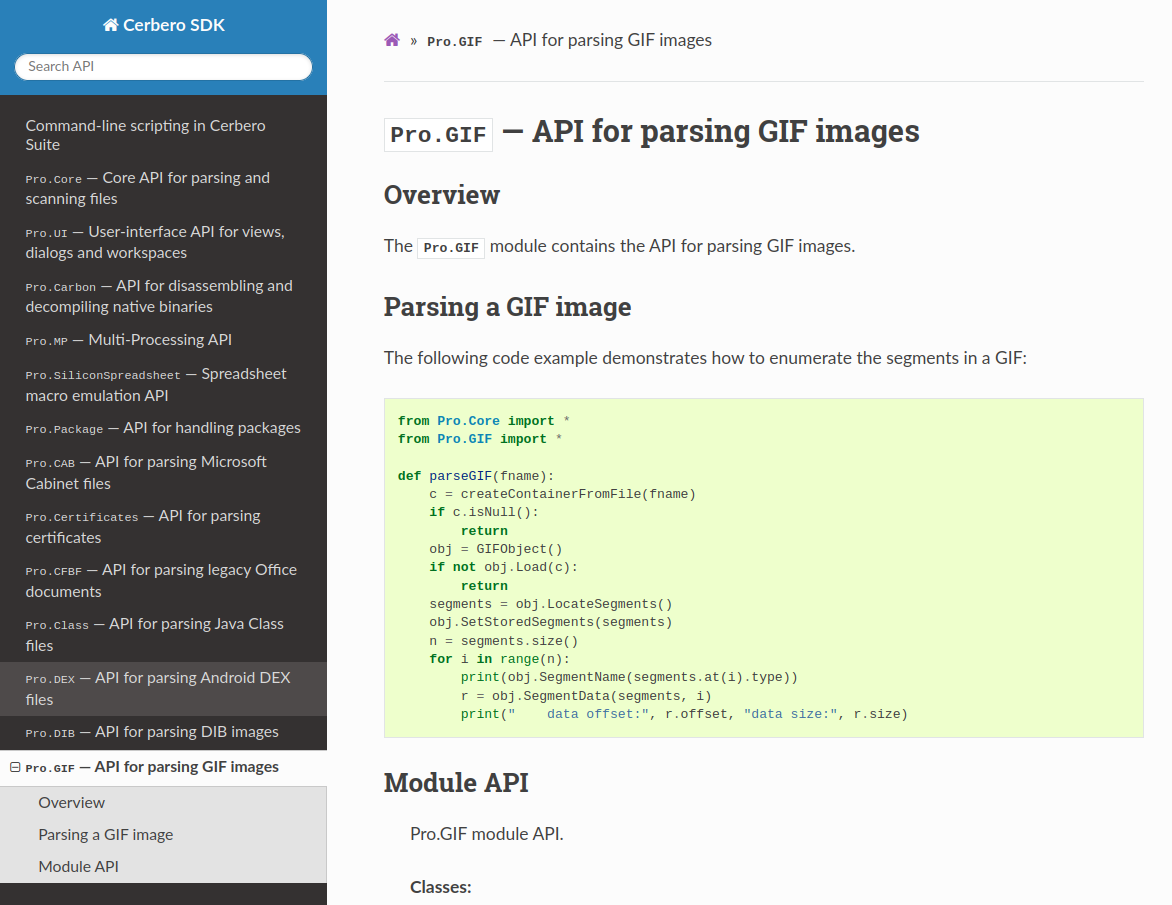
DIB & GIF Modules Documentation
We have documented the API for parsing DIB and GIF images.
{kind=link}
Fast Timer
We have introduced a fast timer in our SDK called NTTimer. This timer is considerably faster than the timing mechanism provided by NTTime.
The way to use it is the same:
t = NTTimer()
t.start()
print("elapsed ms:", t.elapsed())
Zip Parsing Bug
We have fixed a potential infinite loop when parsing incorrect NTFS attributes in Zip archives.
We want to thank CJCCPS for having reported the issue!