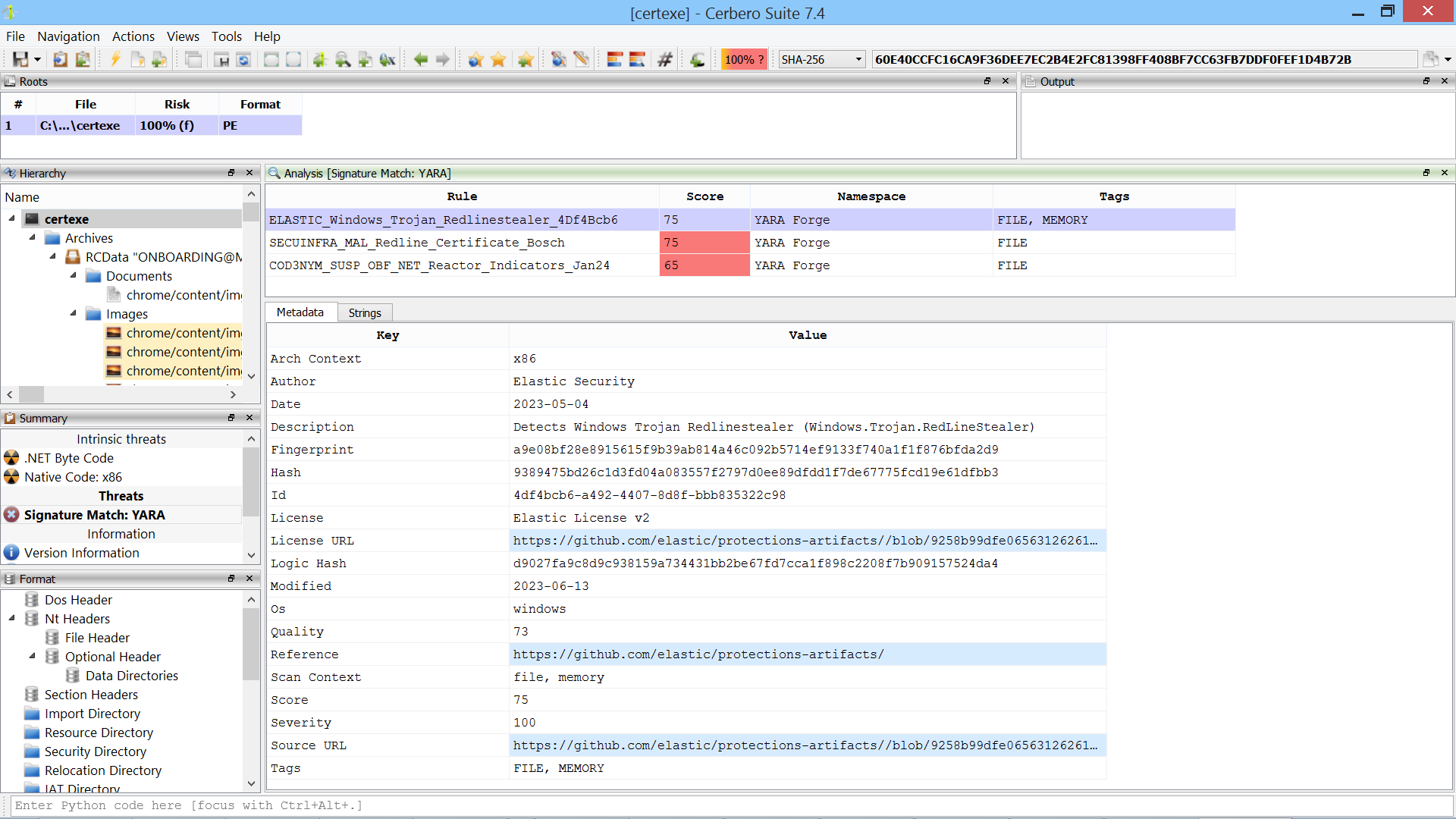
🚀 Big News! We’re thrilled to announce the launch of Cerbero Suite 7 and Cerbero Engine 4. In this post we’ll dive into the arsenal of enhanced features, refined interfaces, and cutting-edge capabilities designed to provide unparalleled insights into the most enigmatic malware threats.

🔍 What’s New in 7.0?
- Unified Editions: We have simplified our offering by unifying the editions of Cerbero Suite, thereby removing the distinction between the Standard and Advanced editions.
- Simplified Renewal Process: From the inception of version 7’s life-cycle, every license purchased will be valid for 1 year, irrespective of the purchase date, and will encompass updates to any major new versions within that year-long period.
- New Features: A fast text view with syntax highlighting, optimized for previewing large files, and a new interface to display file system structures are just two of the features we’ve added.
- Redesigned UI: Navigate through a more intuitive, responsive, and streamlined user interface, enhancing your analytical workflows.
- Python Workspace: Use our improved Python Workspace to edit your scripts with the help of auto-completion.
- Cerbero Store: A refined interface to navigate and install packages.
🛡️ Stay Up-To-Date Against Threats
Through the packages offered on Cerbero Store, we remain committed to delivering the fastest updates to counter the latest threats.
📰 Cerbero Journal Reader
Beginning with this release of Cerbero Suite, our customers will enjoy a 3-month early access to Cerbero Journal, our company’s e-zine.
💵 Launch Promotion
Secure your copy within the first 14 days and enjoy an exclusive launch discount!
Continue reading “Cerbero Suite 7 Release”