Cerbero Suite 8.6 and Cerbero Engine 5.6 are out with several improvements and fixes.
The highlight: a new caching system that makes memory analysis even faster than it was before!
Cerbero Suite 8.6 and Cerbero Engine 5.6 are out with several improvements and fixes.
The highlight: a new caching system that makes memory analysis even faster than it was before!
Cerbero Suite 8.5 and Cerbero Engine 5.5 are out! Most improvements are under the hood or related to the SDK.
One small but useful addition worth mentioning is the ability to configure a global font for the entire application.
We’re happy to announce the release of Cerbero Suite 8.4 and Cerbero Engine 5.4. This might be a minor version, but we’ve added some important features that have been on our list for a while.
This has been a long time coming—most tables in Cerbero Suite can now be sorted. If a plugin uses the default table control, sorting works automatically without any extra effort.
We released Cerbero Suite 8.3 and Cerbero Engine 5.3! While we have introduced many small improvements and expanded our SDK, most of the work for this release is “under the hood.” Shortly, we will release many new packages that benefit from the improvements we have added.
We’re excited to release Cerbero Suite 8.2 and Cerbero Engine 5.2!
This release includes many improvements, with the most significant being the introduction of the Memory Analysis package. We encourage you to read the blog post about it for more details. Additionally, it’s worth mentioning that the Windows crash dump format has been moved to an optional package and is no longer included with the main binary.
We’re excited to release Cerbero Suite 8.1 and Cerbero Engine 5.1!
The main highlight of this release is that we have finally completed the documentation of the SDK. However, there are also some other news which we’ll be discussing in this post.
We have completed the documentation of the SDK, including built-in file formats, installable packages, and external modules.
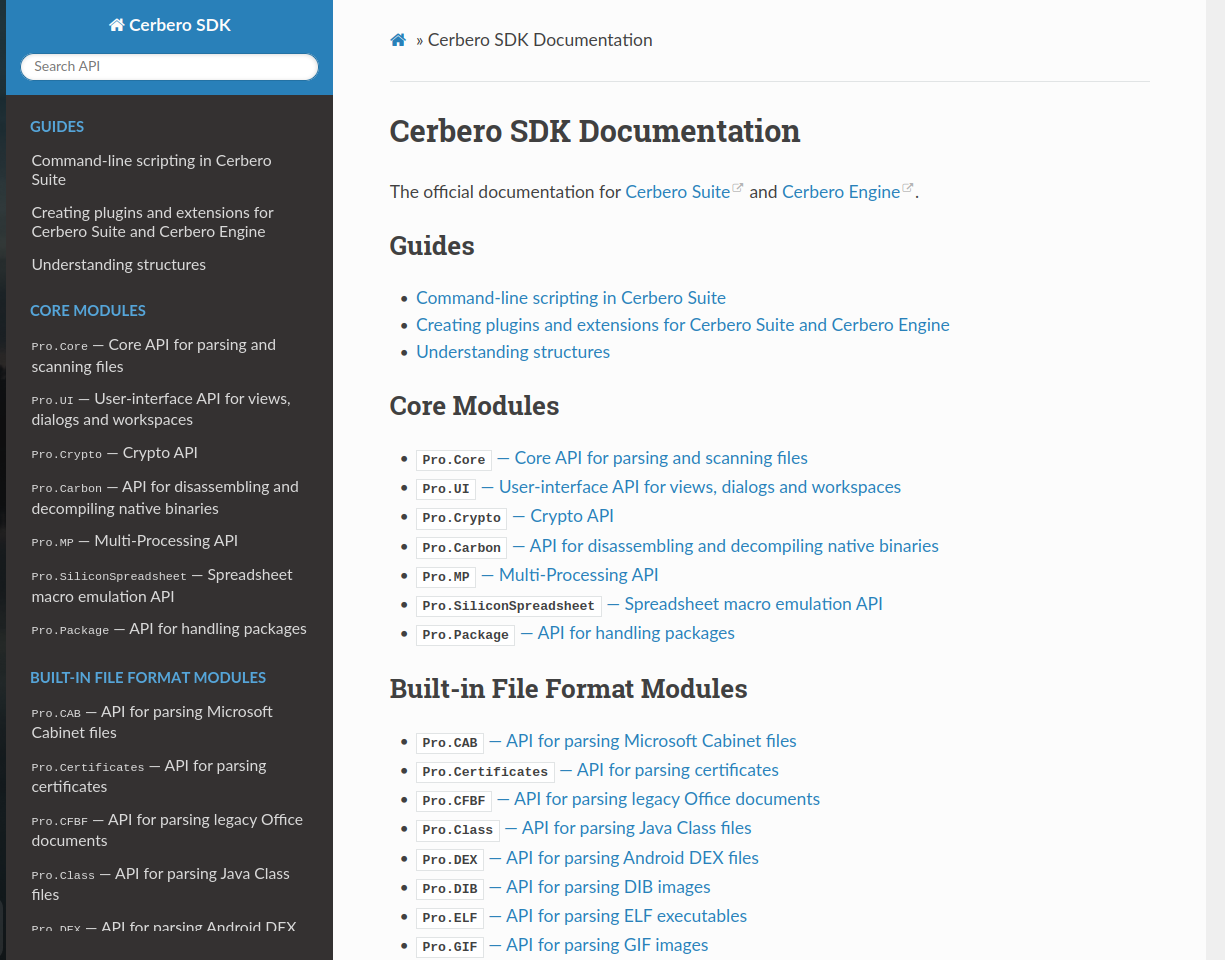
This means that the entire SDK is now available for auto-completion in the Python editor. Every time you install a package that is exposed to the SDK, auto-completion becomes available for that package as well.
The SDK of Cerbero Suite and Cerbero Engine is unparalleled in scope and depth, offering a vast array of functionalities for developers. With the documentation, you can easily explore all the capabilities the SDK has to offer. Whether you’re writing plugins to automate tasks, analyzing complex file formats, or creating new tools, the SDK provides the necessary tools and resources.
The integrated Python editor in Cerbero Suite further enhances your development experience by providing features like syntax highlighting, hints and code completion. To get started, simply navigate to the SDK documentation website, where you’ll find extensive guides, API references, and examples. The documentation is organized to help both beginners and advanced users quickly find the information they need.
We are excited to announce the release of Cerbero Suite 8 and Cerbero Engine 5! All our customers with a valid license can now upgrade directly within the application.
In this major release, we’ve revamped the start page to enhance accessibility to the various logic providers and introduced customizable panels. Now, you can select your preferred tools and position them prominently for quick access upon launching Cerbero Suite.
We’re excited to release Cerbero Suite 7.8 and Cerbero Engine 4.8!
This new release includes improvements and bug fixes. However, the main news of this update is the release of the InnoSetup Format and IFPS Format packages.
We’re excited to release Cerbero Suite 7.7 and Cerbero Engine 4.7!
This new release includes many improvements and bug fixes. However, the main news of this update is the release of the File Miner package.
We’re excited to release Cerbero Suite 7.6 and Cerbero Engine 4.6!
This new release includes various improvements and bug fixes. However, the primary focus of this update has been laying the groundwork for several major package releases that are coming very soon.