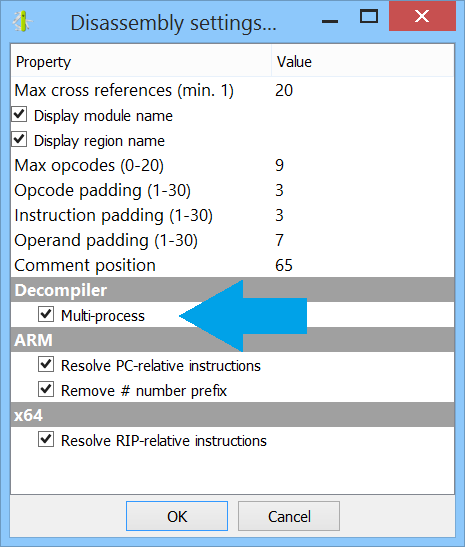
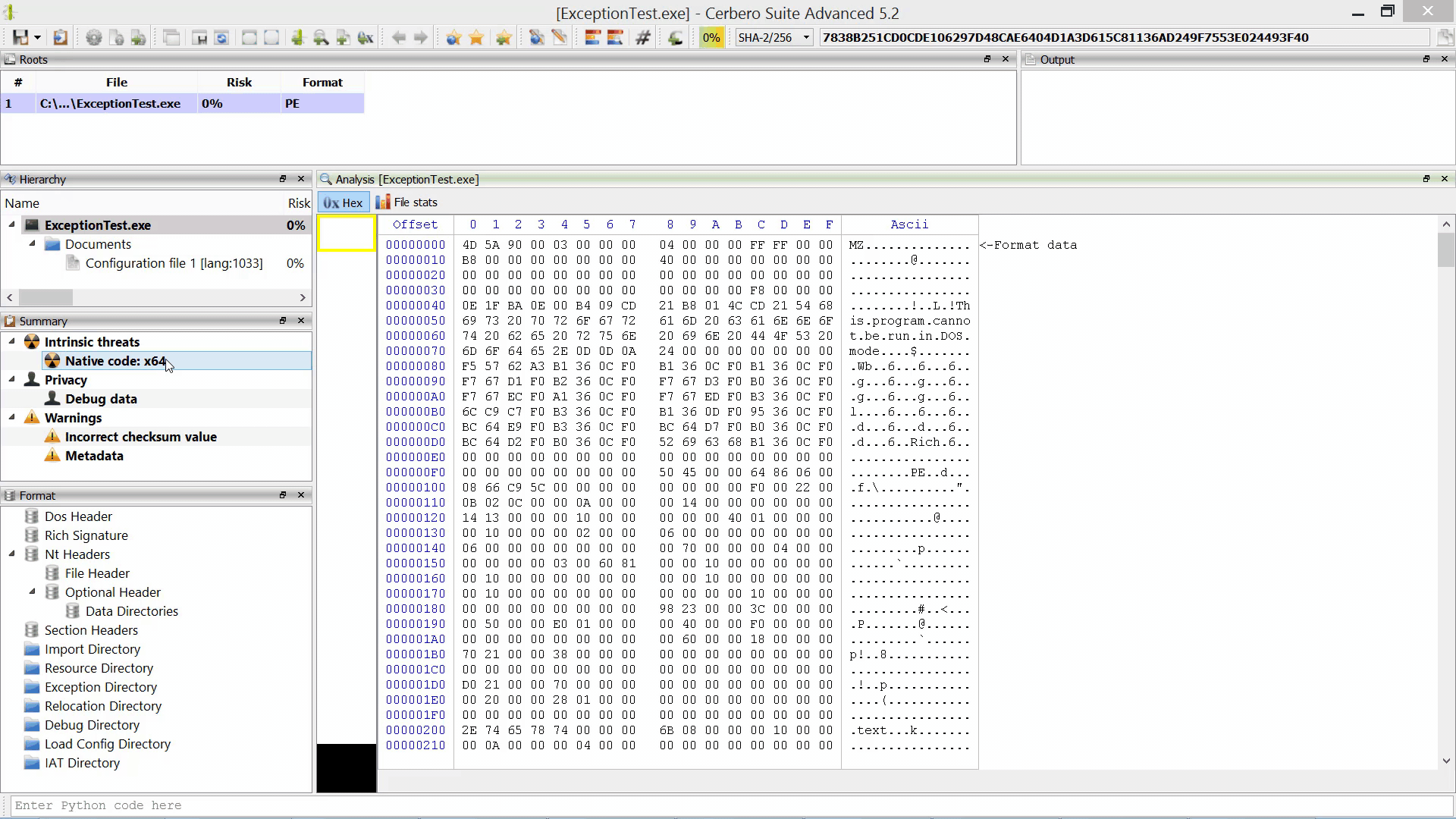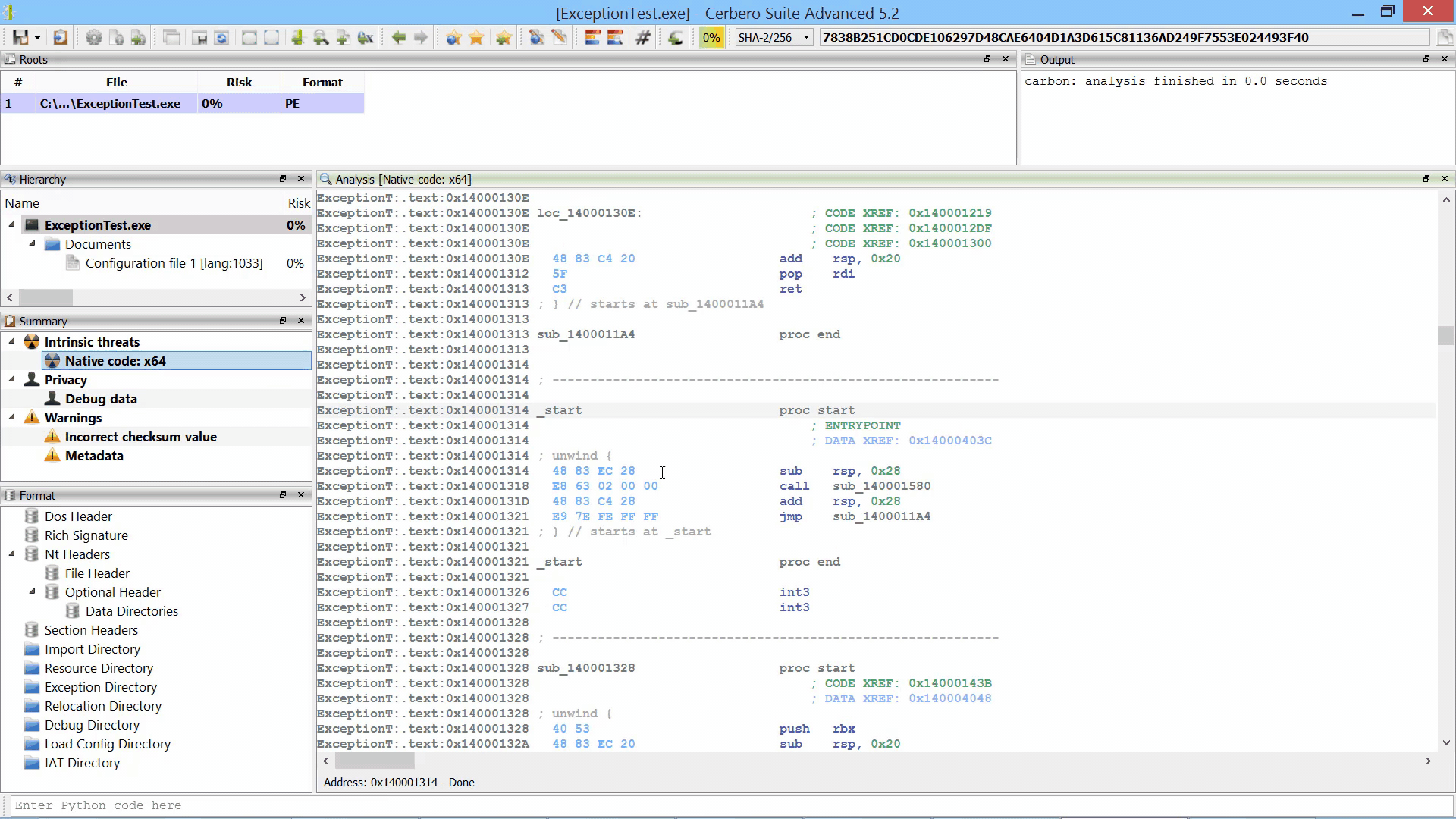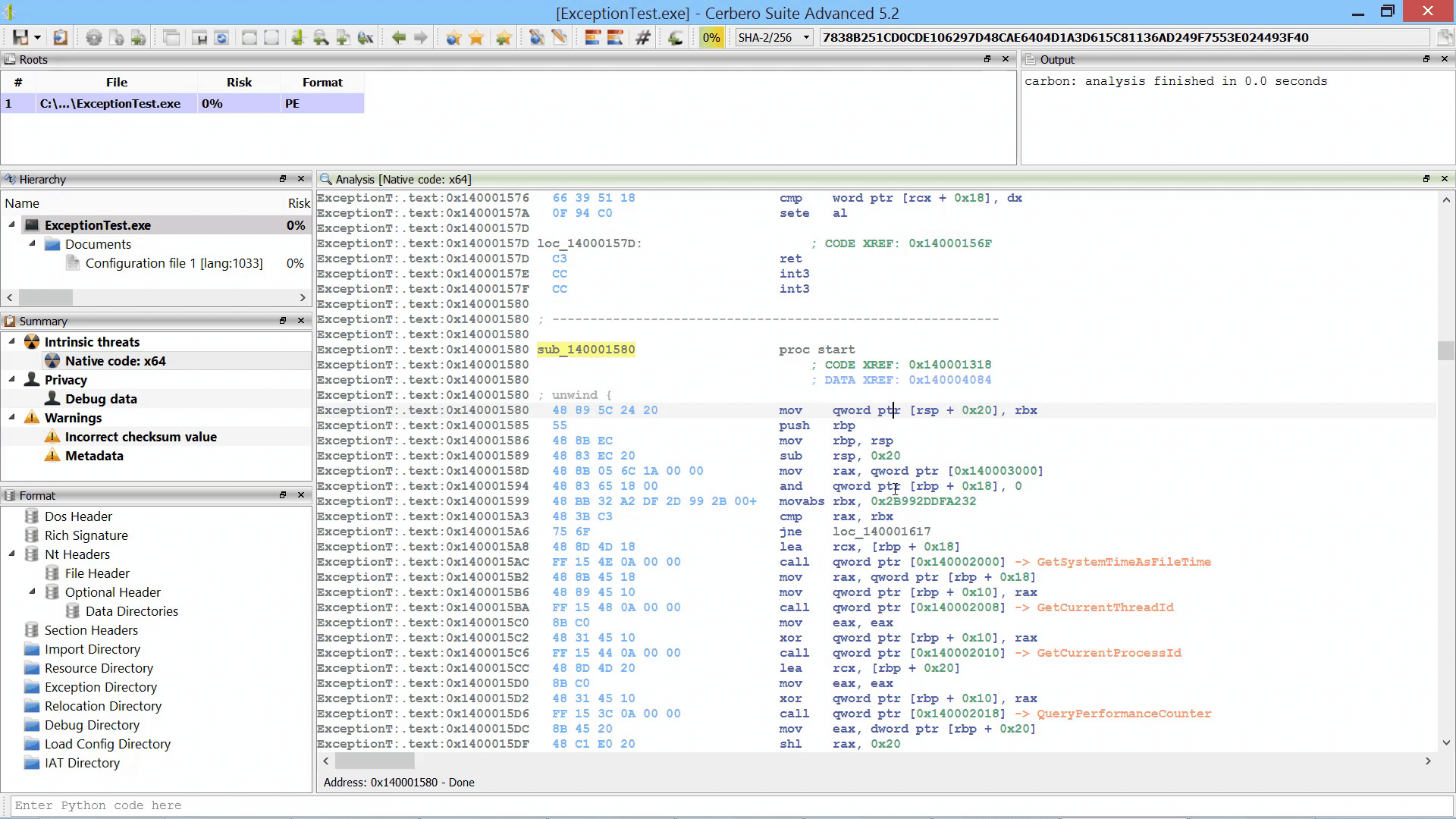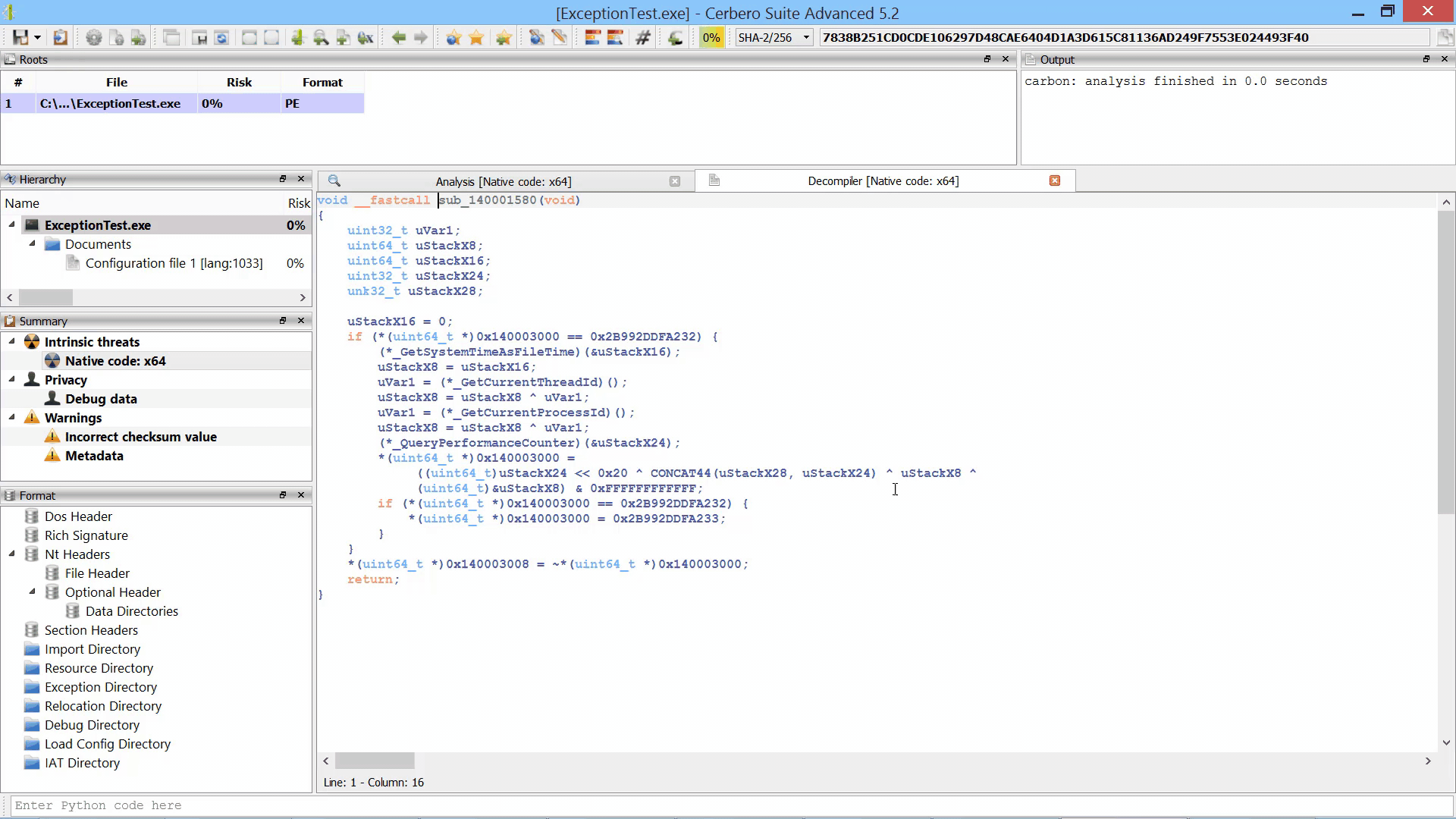
In the upcoming Cerbero Suite 5.2 we used our new multi-processing technology (part 1, part 2) to parallelize the Sleigh decompiler by running it in a different process. This guarantees complete stability in case Sleigh encounters an issue and makes every decompiling operation safe to cancel.
We didn’t notice slow-downs by running the decompiler in a different process, in fact it’s still blazingly fast.
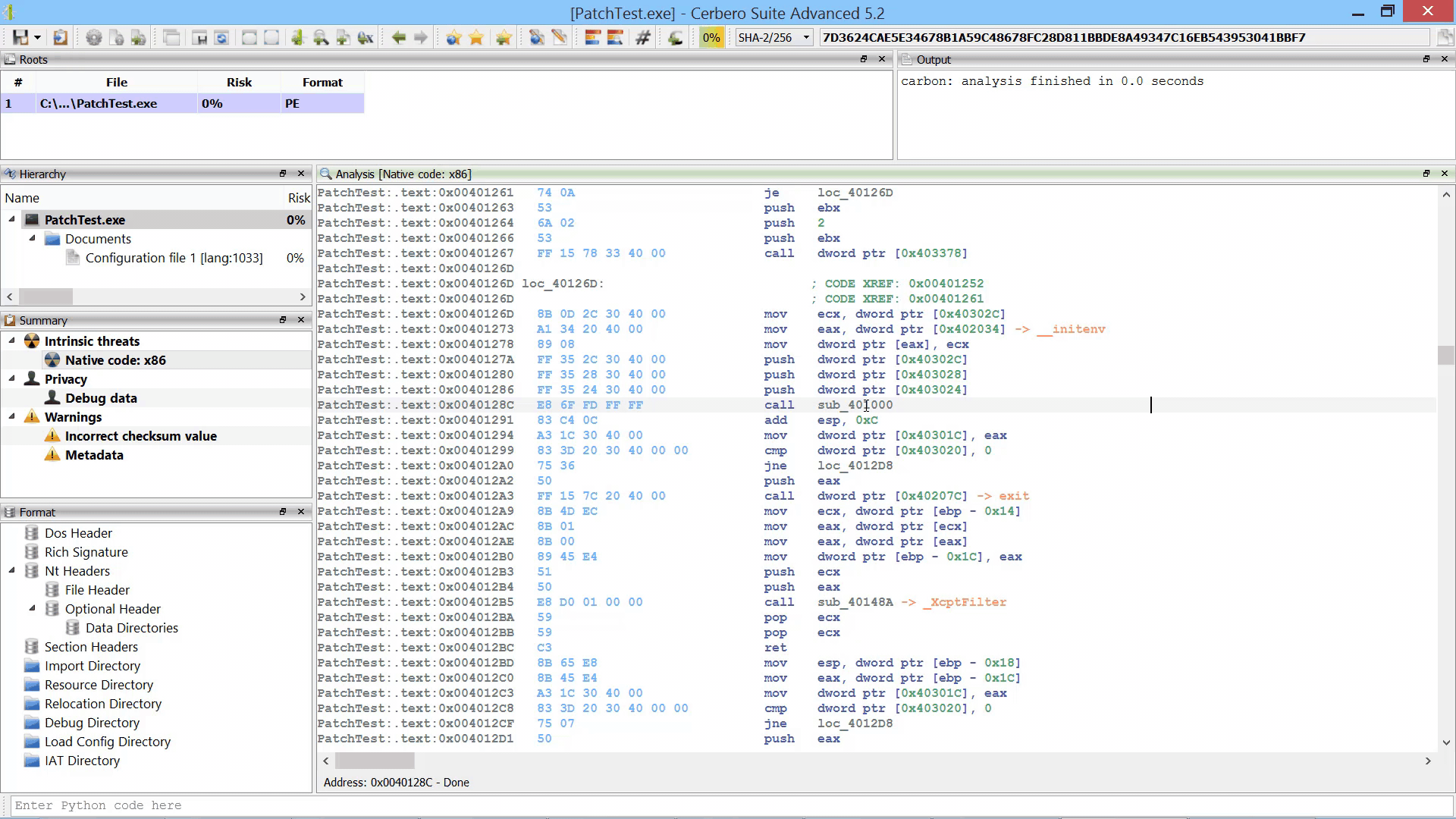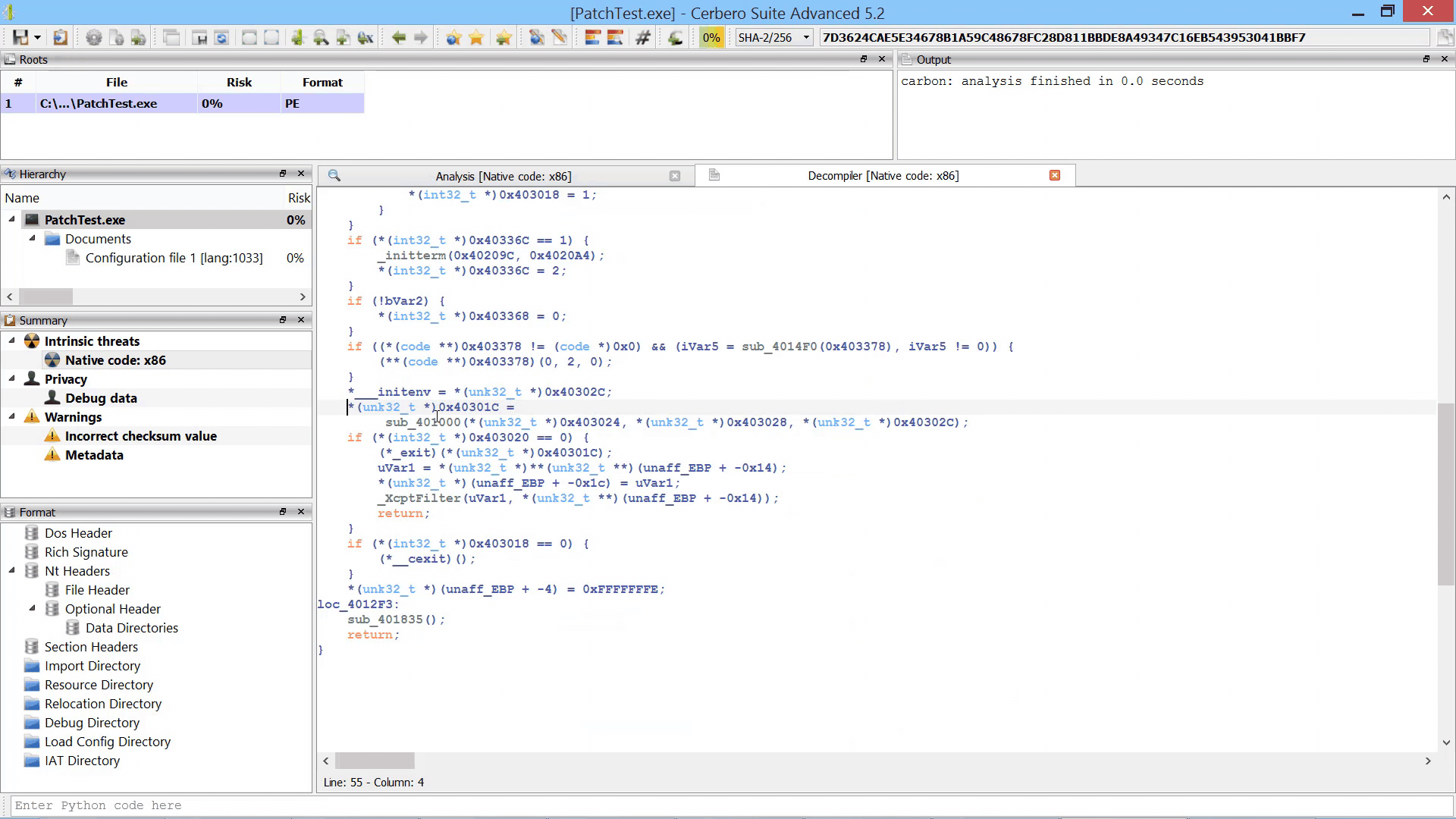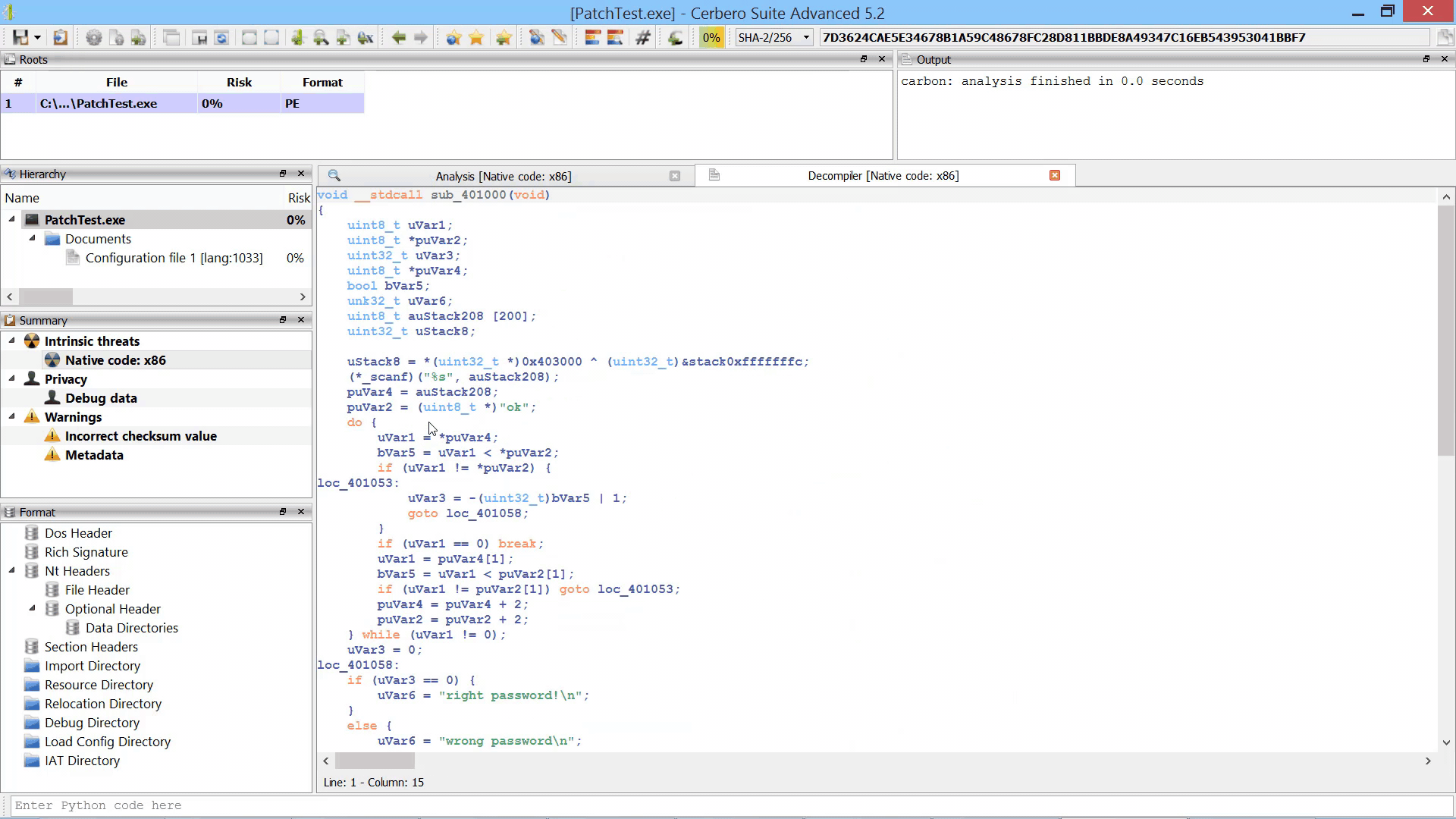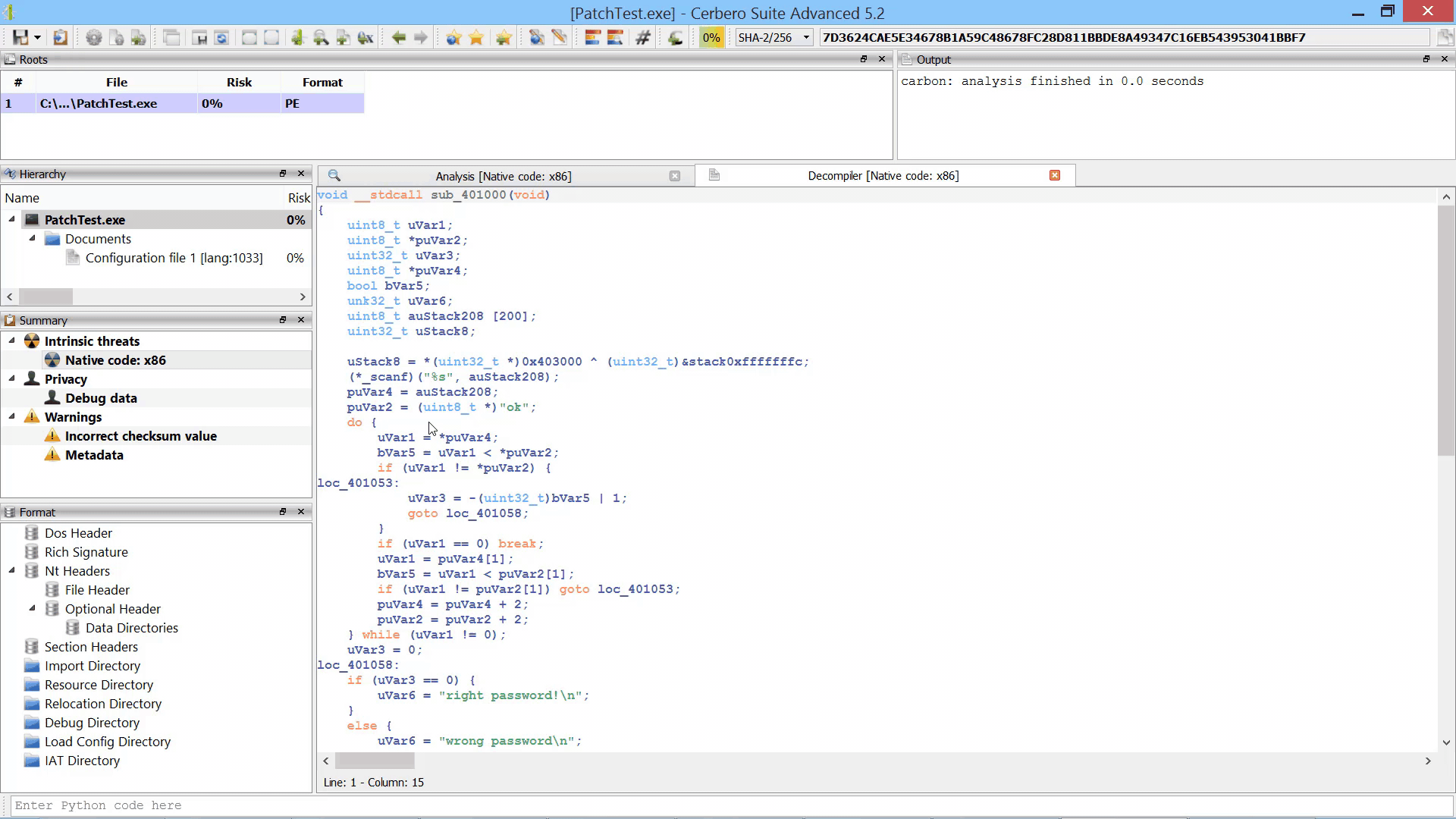
By parallelizing the decompiler we were also able to initialize it during the loading of the file / database. Thus, when the decompiler is invoked for the first time there is no initial delay.
Although the decompiler doesn’t take much time to load, the preloading makes it extra-snappy.
It is also possible to choose to run the decompiler in the same process as before from the Carbon settings.