Here summarized are the main news of this release of Cerbero Suite 5.6 and Cerbero Engine 2.6.
MalwareBazaar Intelligence Package
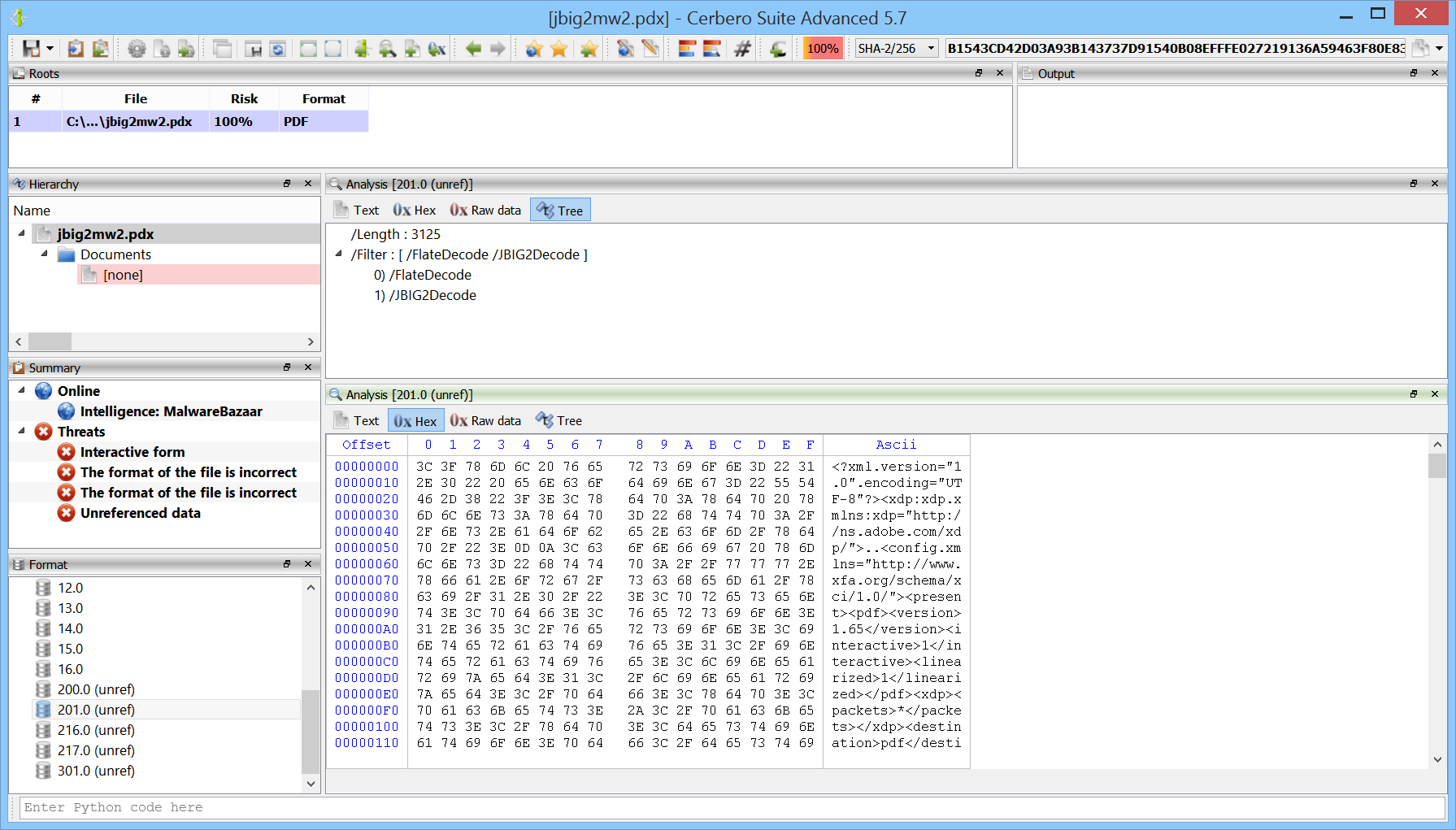
We created the MalwareBazaar Intelligence package. This package lets you access intelligence from MalwareBazaar directly from the file report.
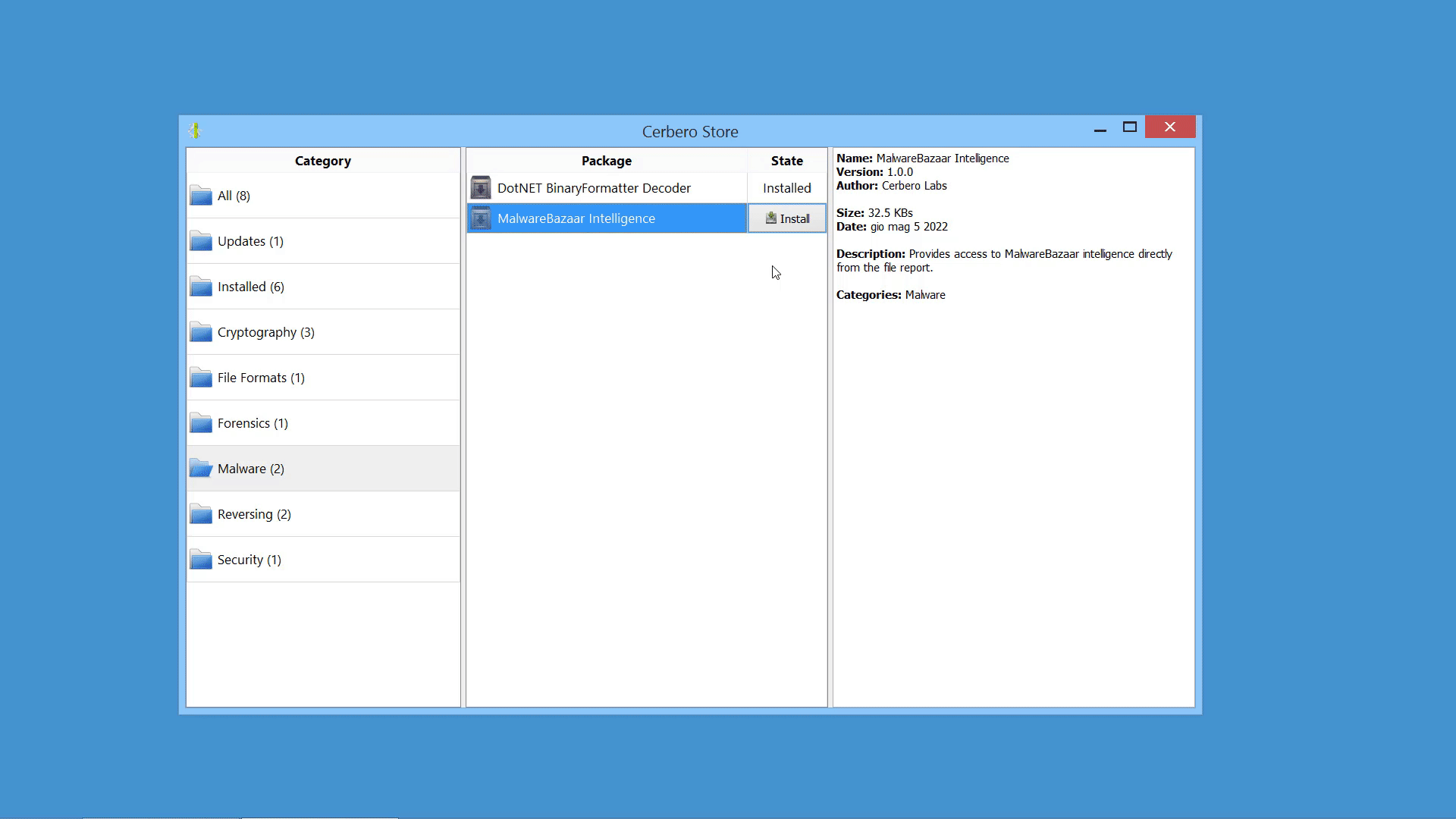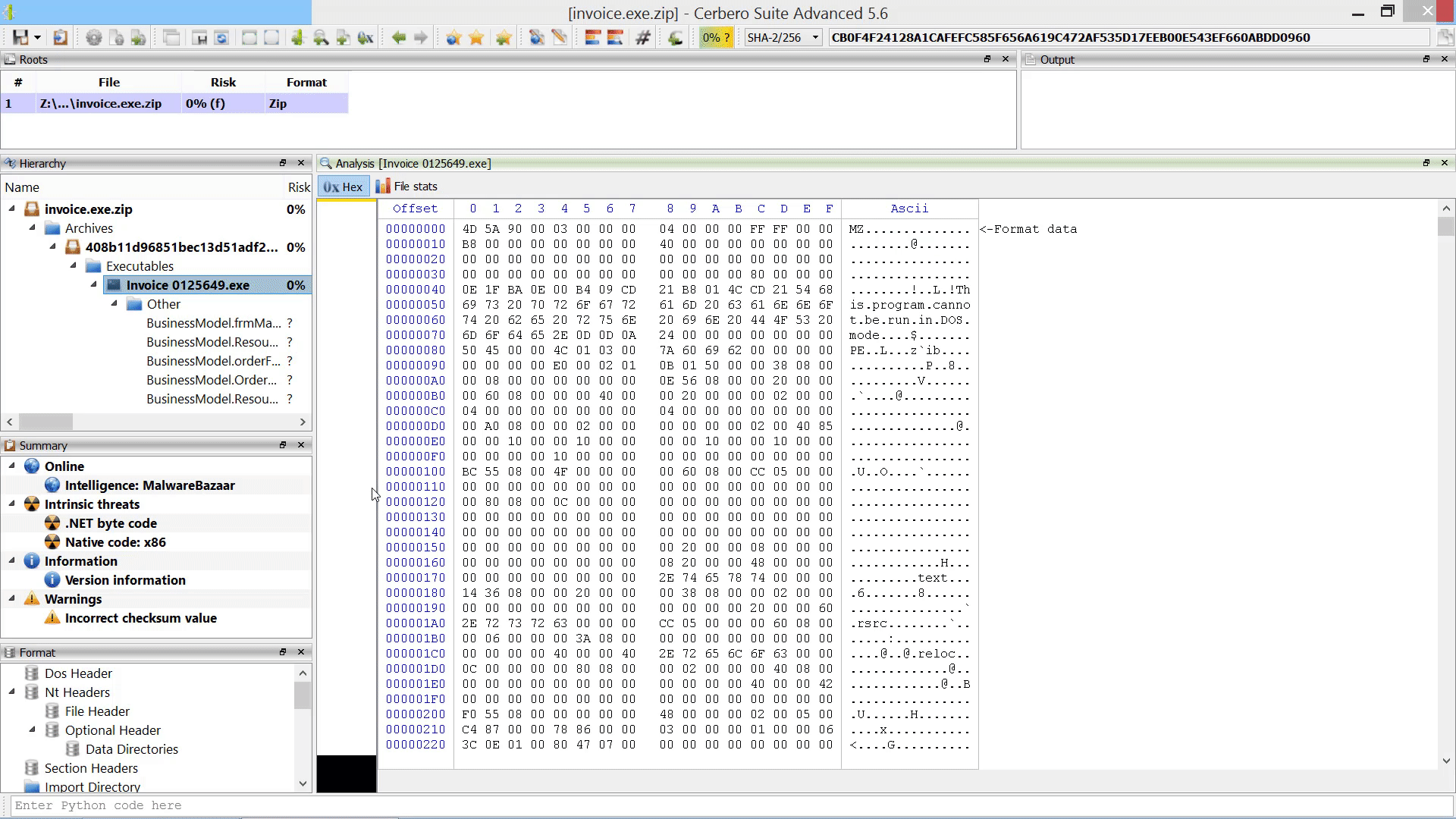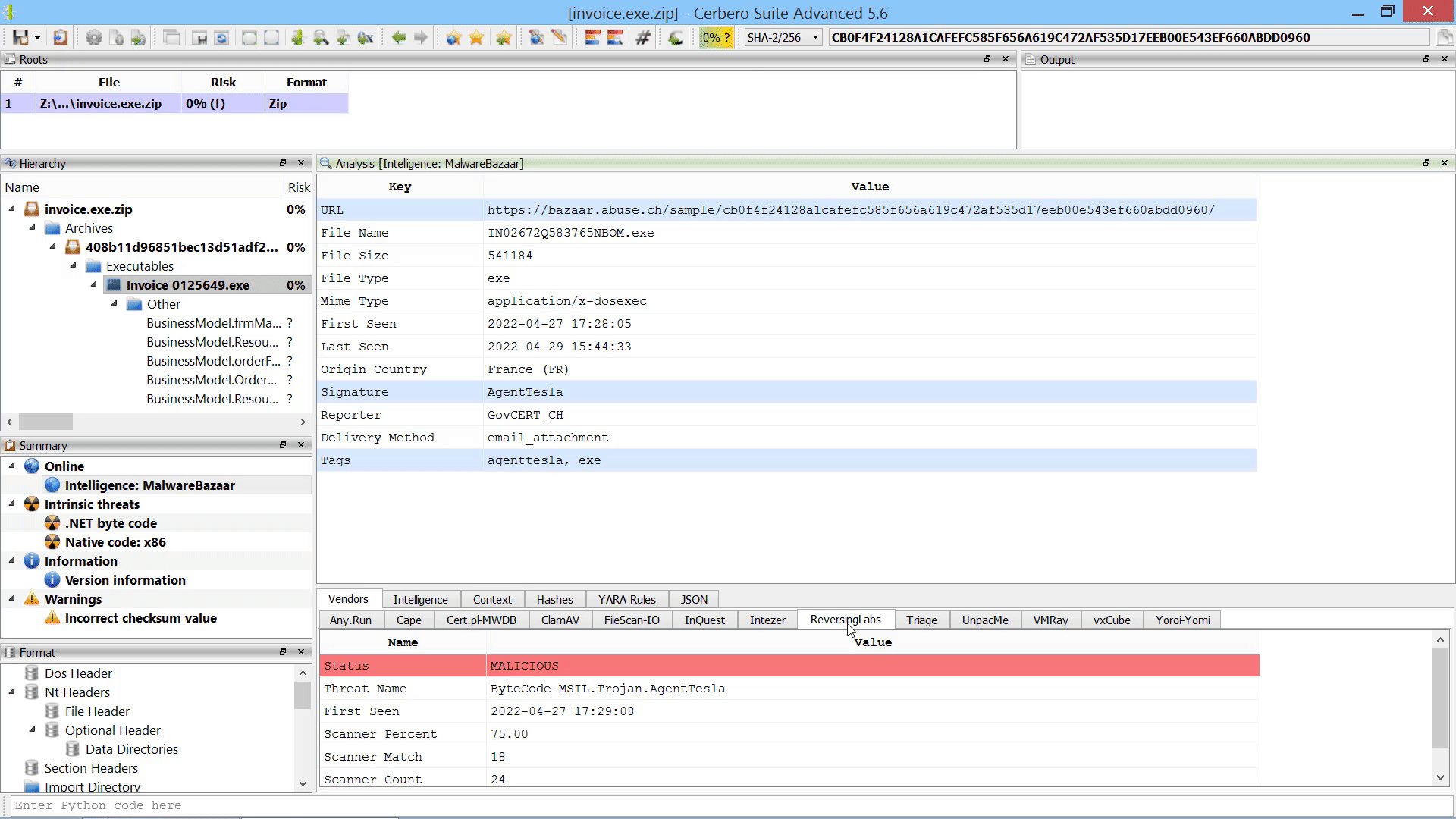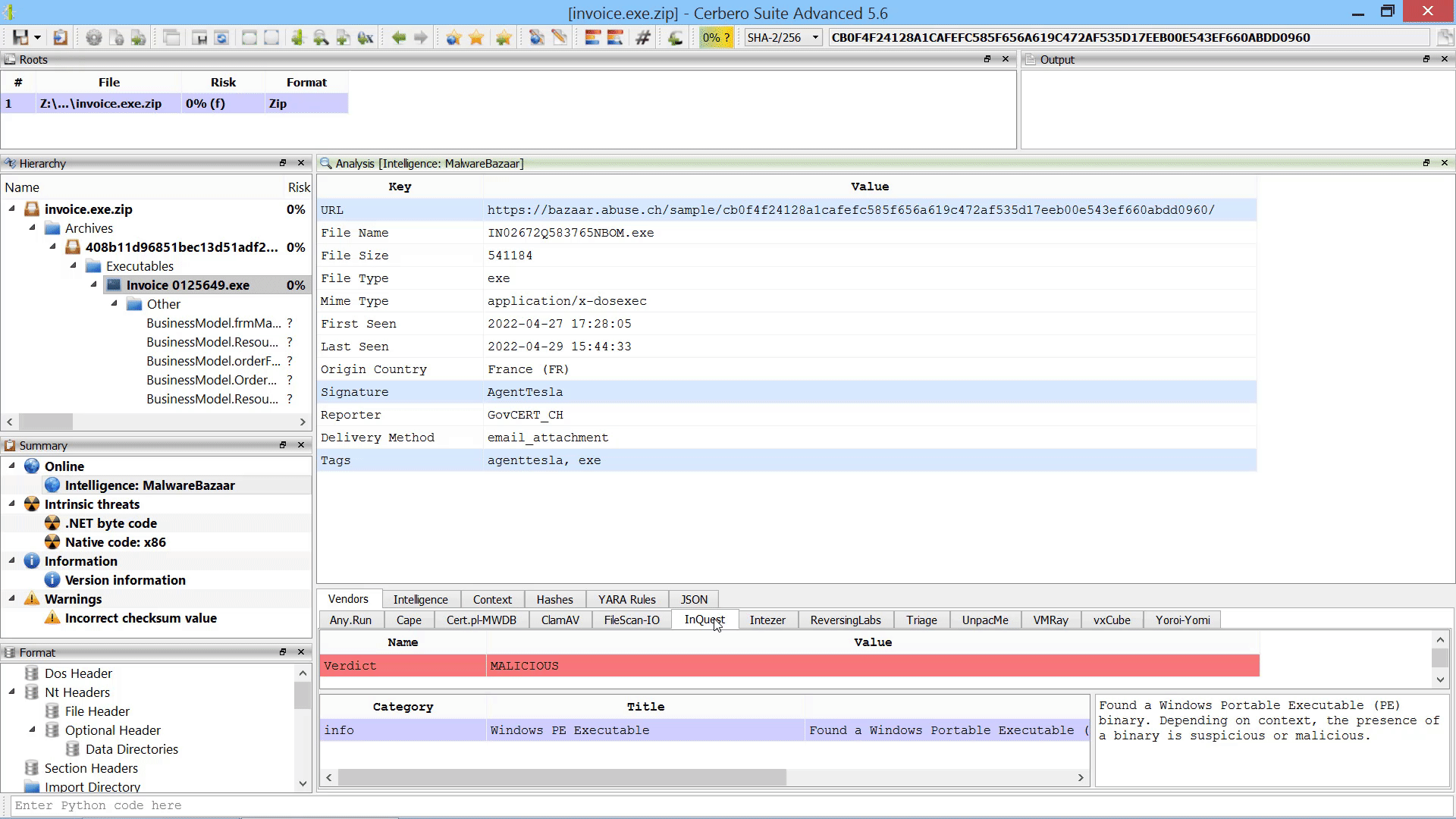
Commercial licenses for Cerbero Suite Advanced have access to this package.
UPX Unpacker Package
We created an UPX Unpacker package available for all licenses.
From the UPX web-site: “UPX is a free, portable, extendable, high-performance executable packer for several executable formats.”
By installing the UPX Unpacker package, binaries compressed with UPX are automatically identified and unpacked as child objects.
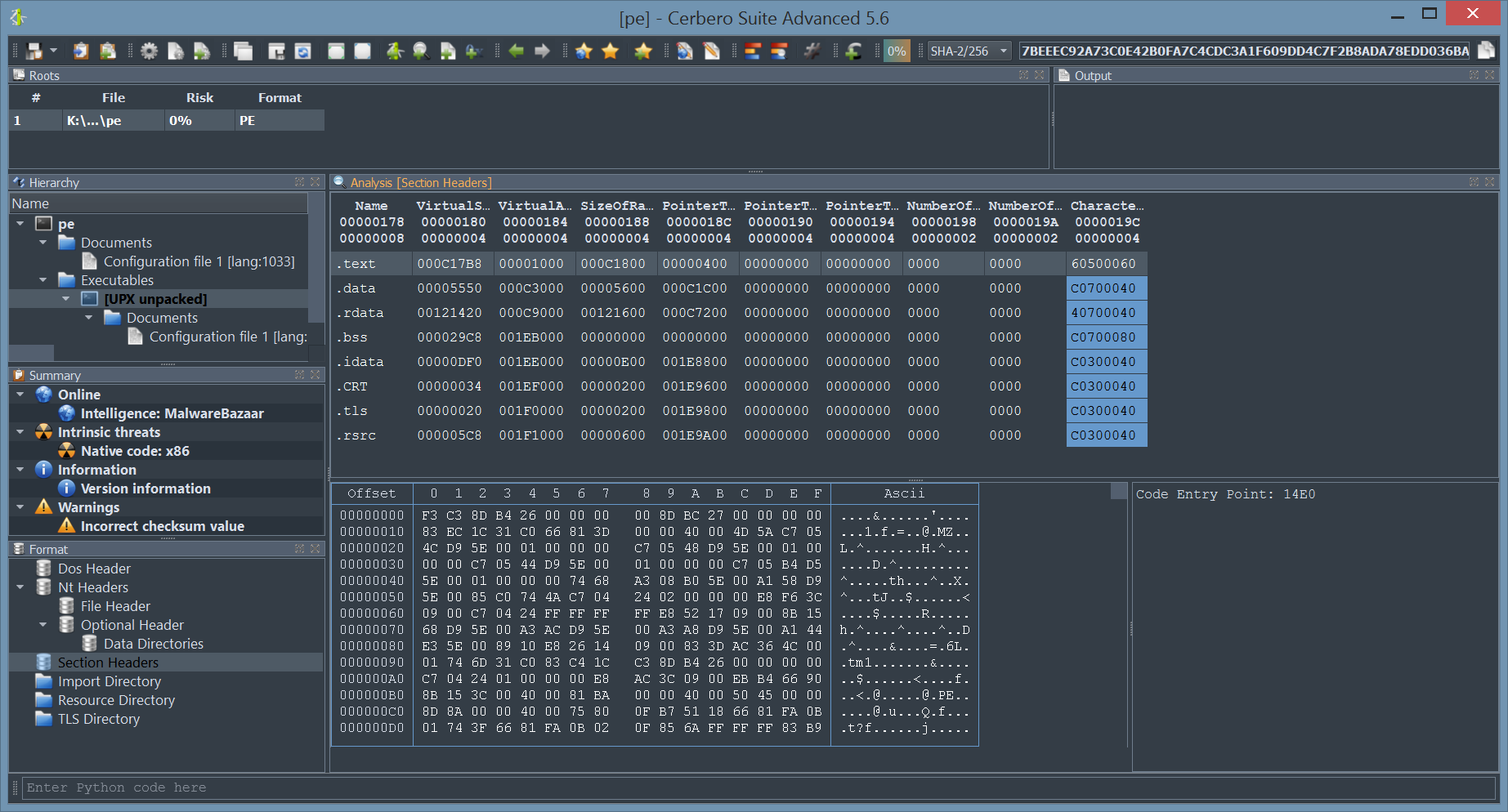
PE, ELF and Mach-O binaries are all supported.
If for some reason a binary is not automatically unpacked, the unpacker can be invoked manually as an action.
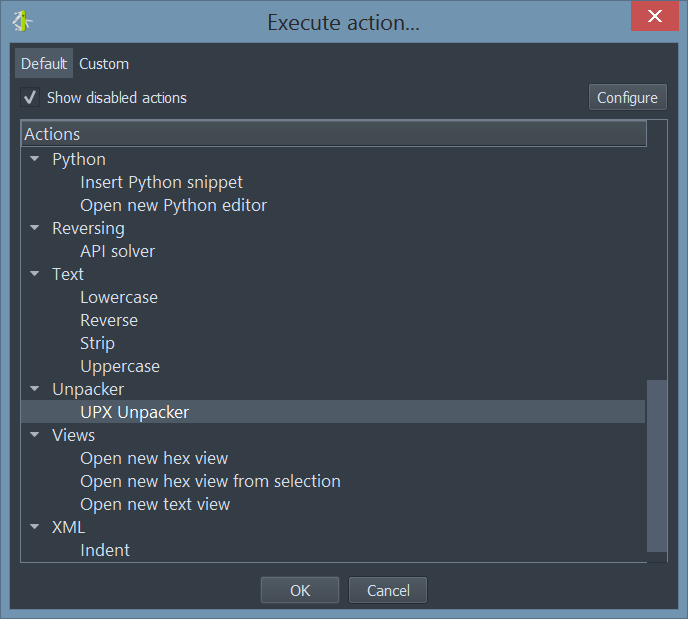
Additionally, the unpacker can be invoked from Python.
You can read more about the topic in our dedicated post.
Internal Project Files
We introduced a new major core feature, namely the capability to generate files which do not exist on disk and store them in the analysis report.
While this feature may not appear as essential, it has countless real-world applications. For example, an unpacker may unpack a file during the scanning process and store the resulting file as an internal file. When the unpacked file is requested, the operation bypasses the unpacker and directly accesses the internal file.
Internal files can be referenced from embedded objects as well as from root entries.
You can read the details about the topic in our dedicated post.
After-Scanning Actions
We made several improvements which can be best described as ‘after-scanning actions’.
For instance, it is now possible to programmatically add scan entries to a report after the scanning has occurred.
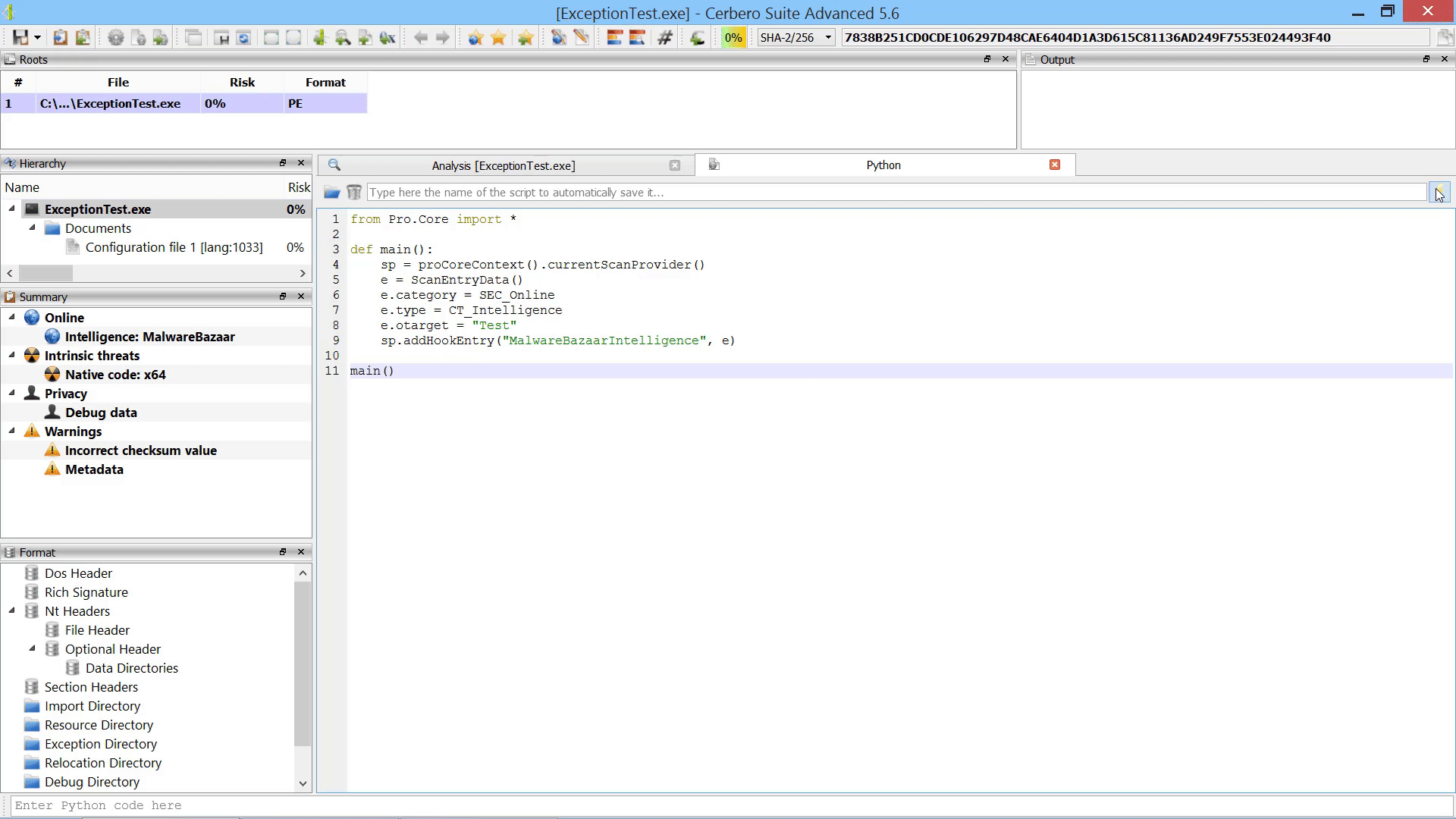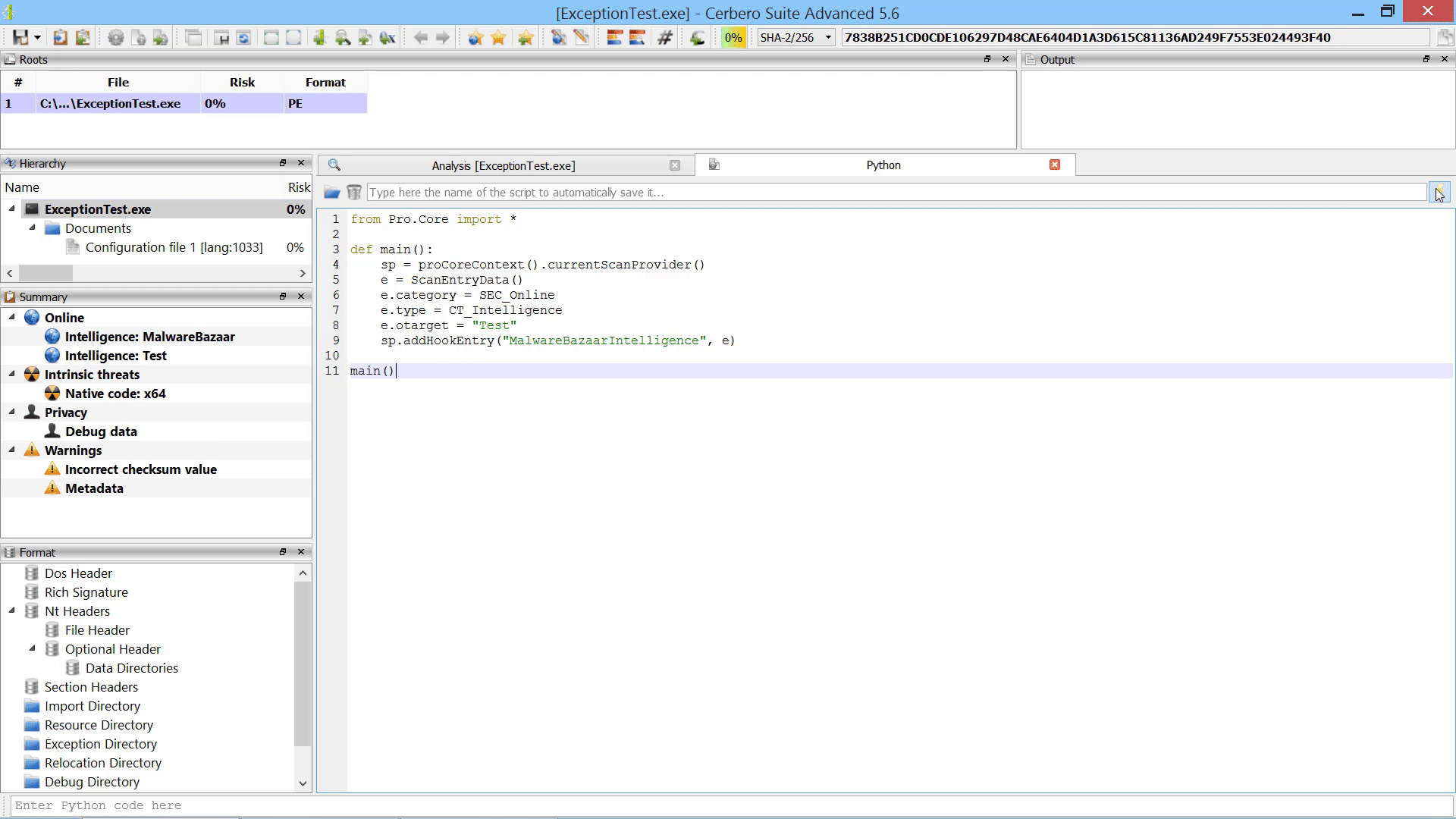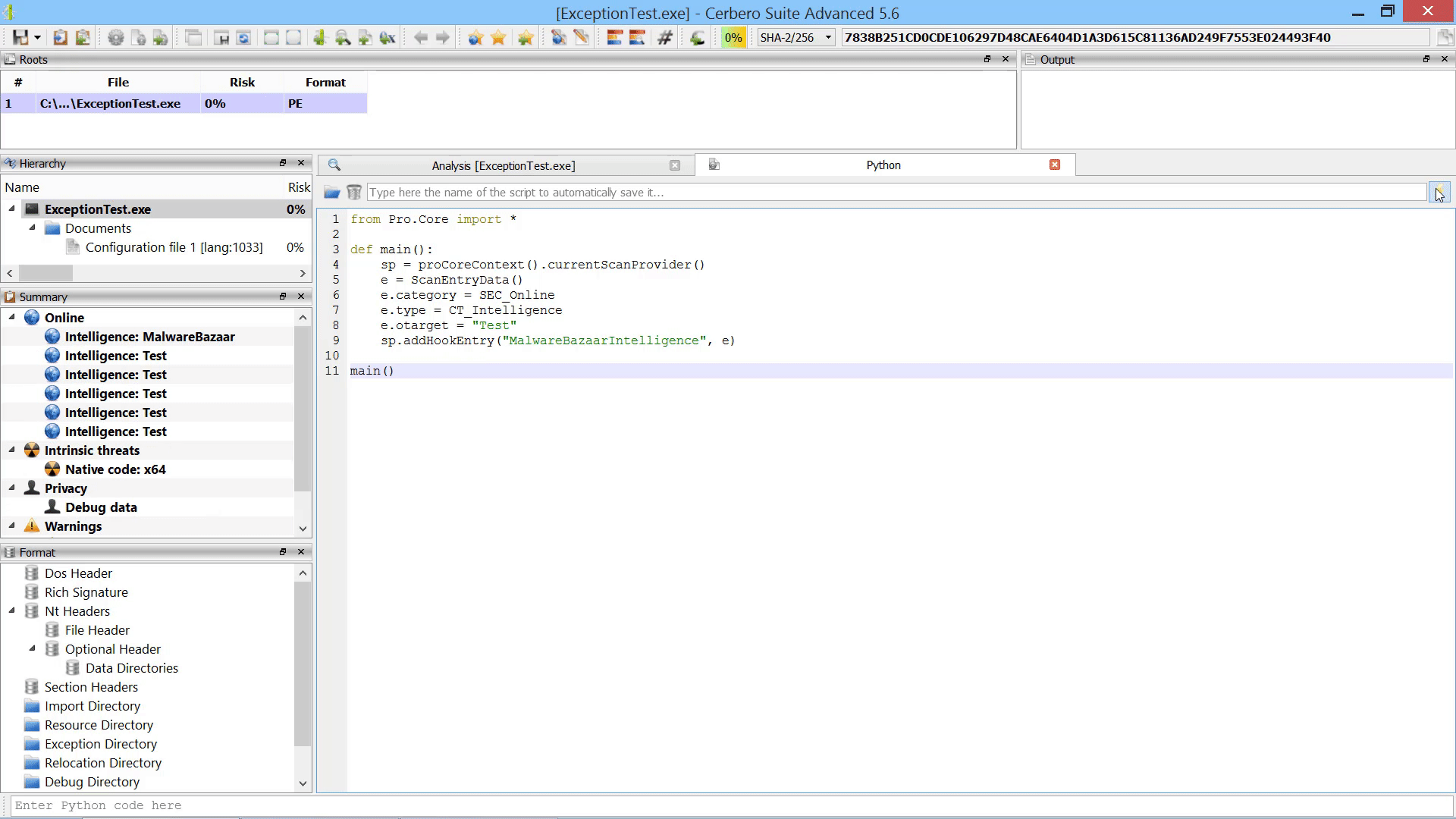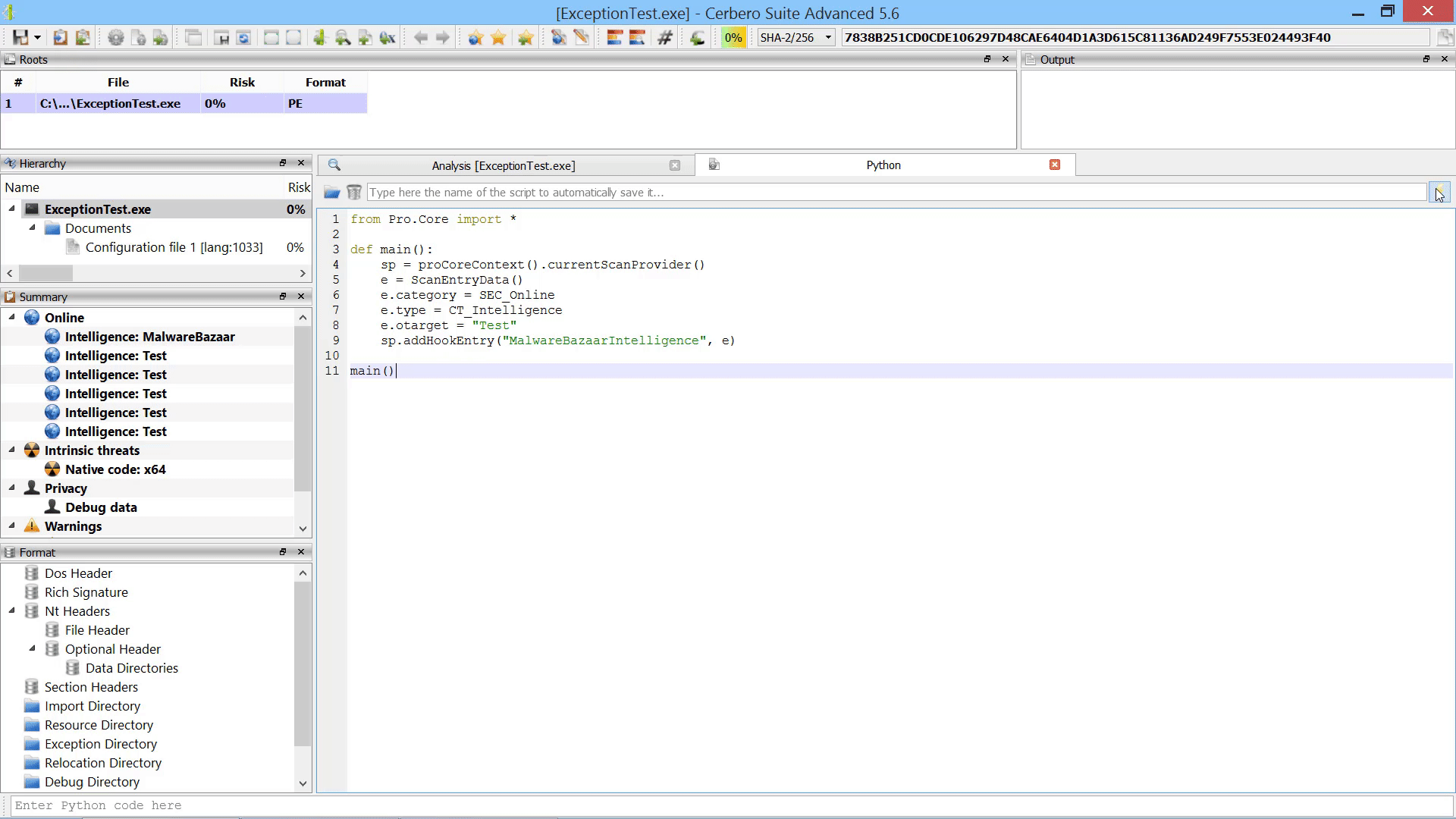
While the user could always manually load embedded objects after scanning, it is now possible to load embedded objects programmatically after scanning.
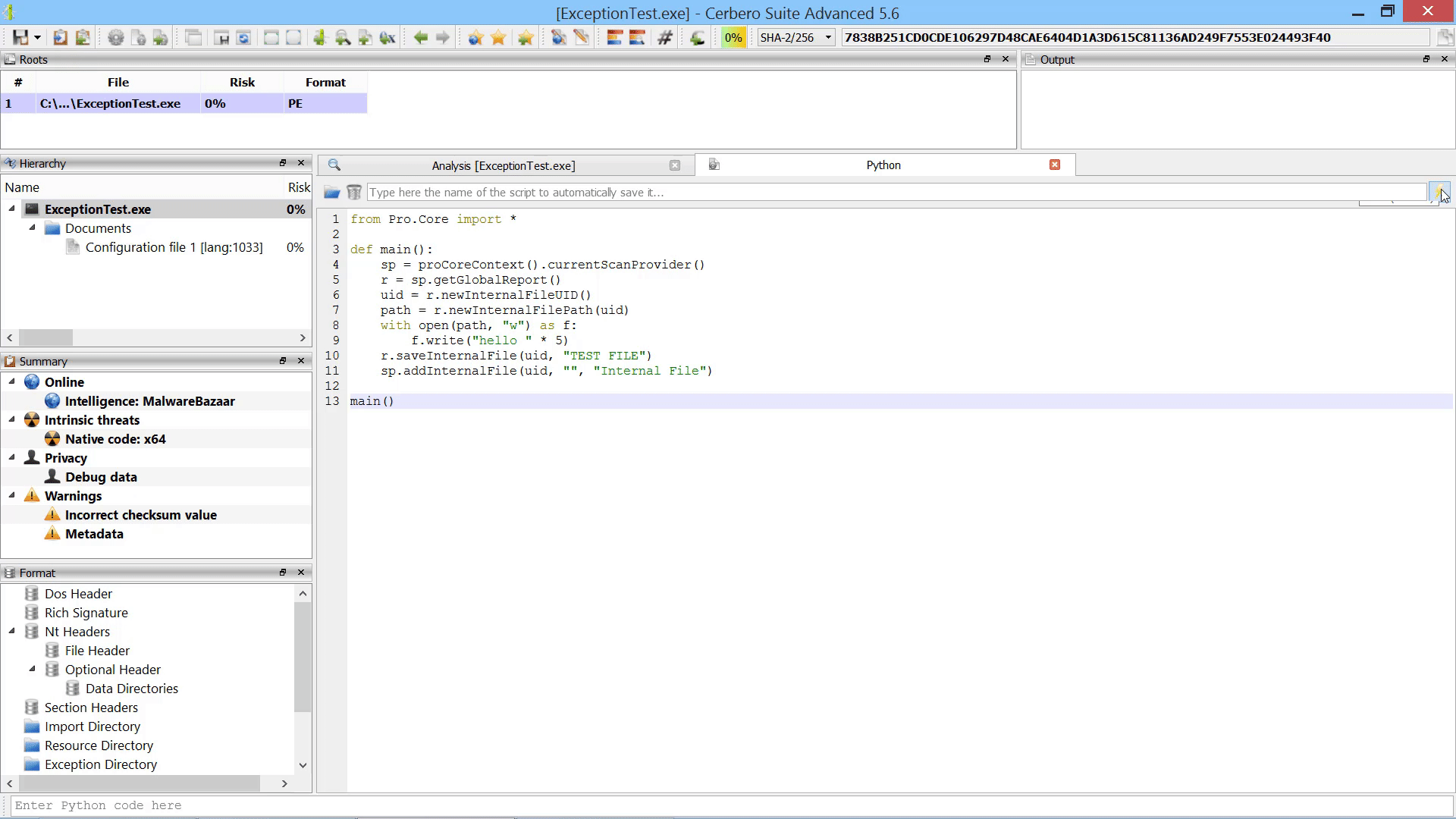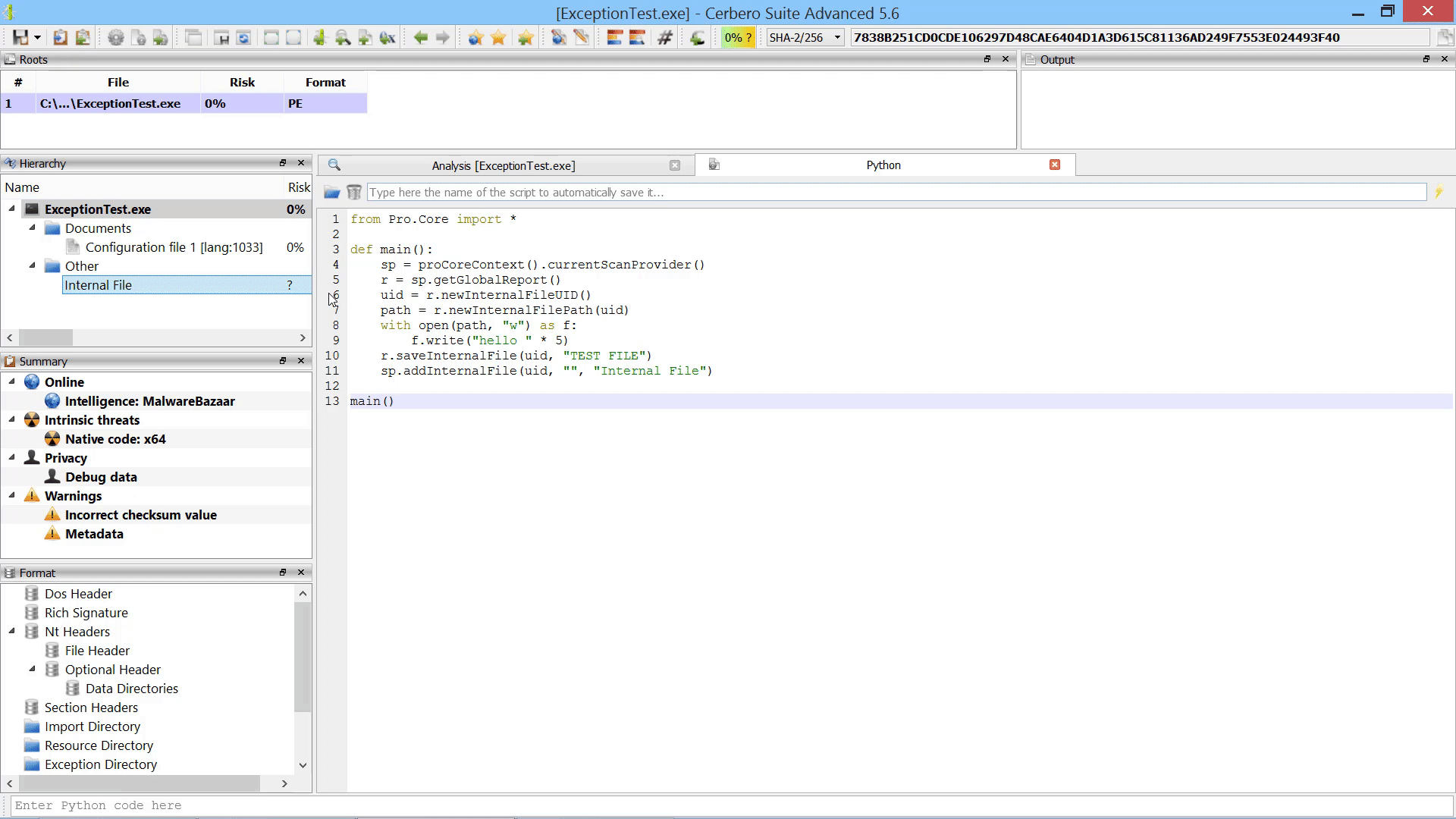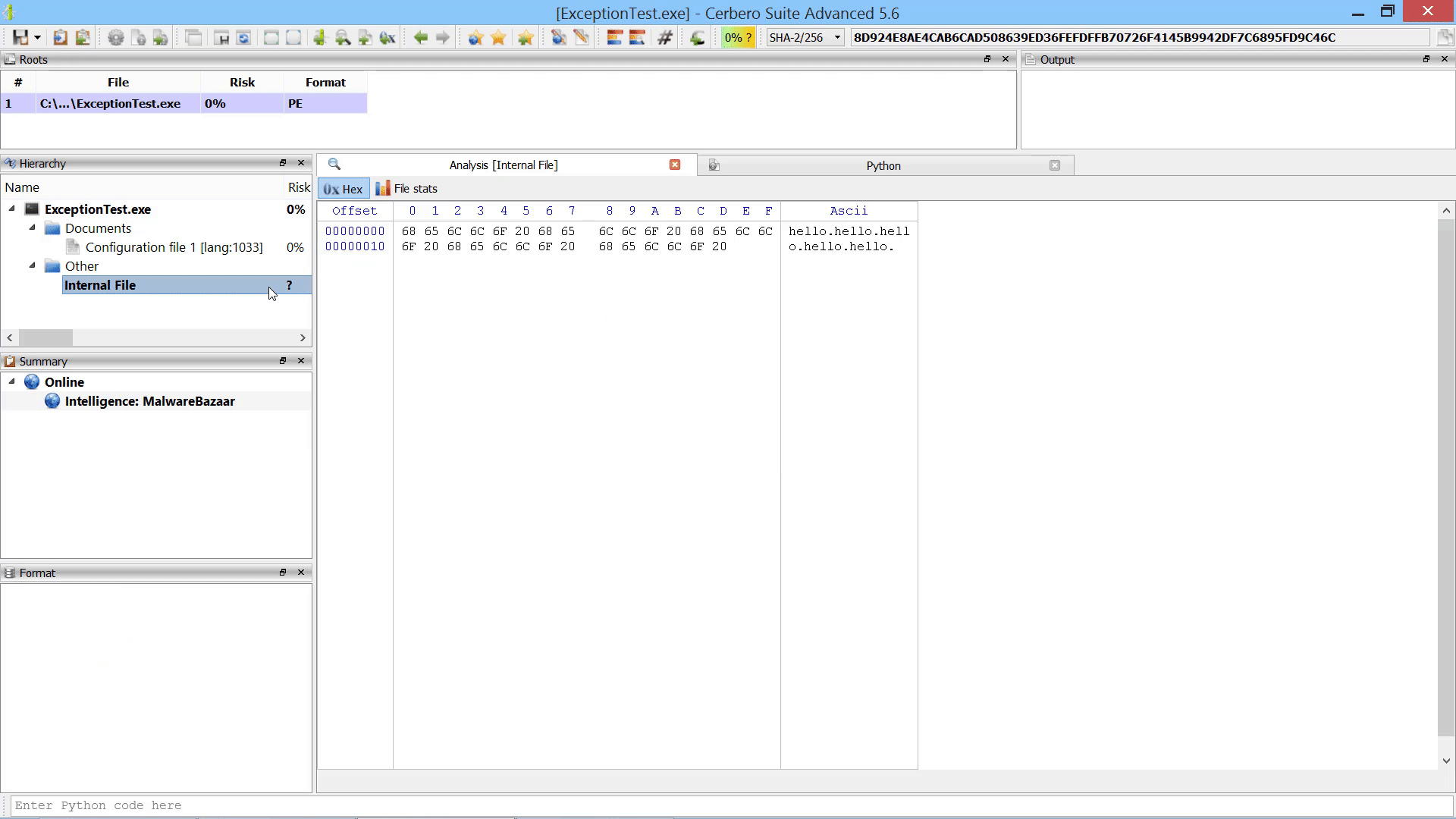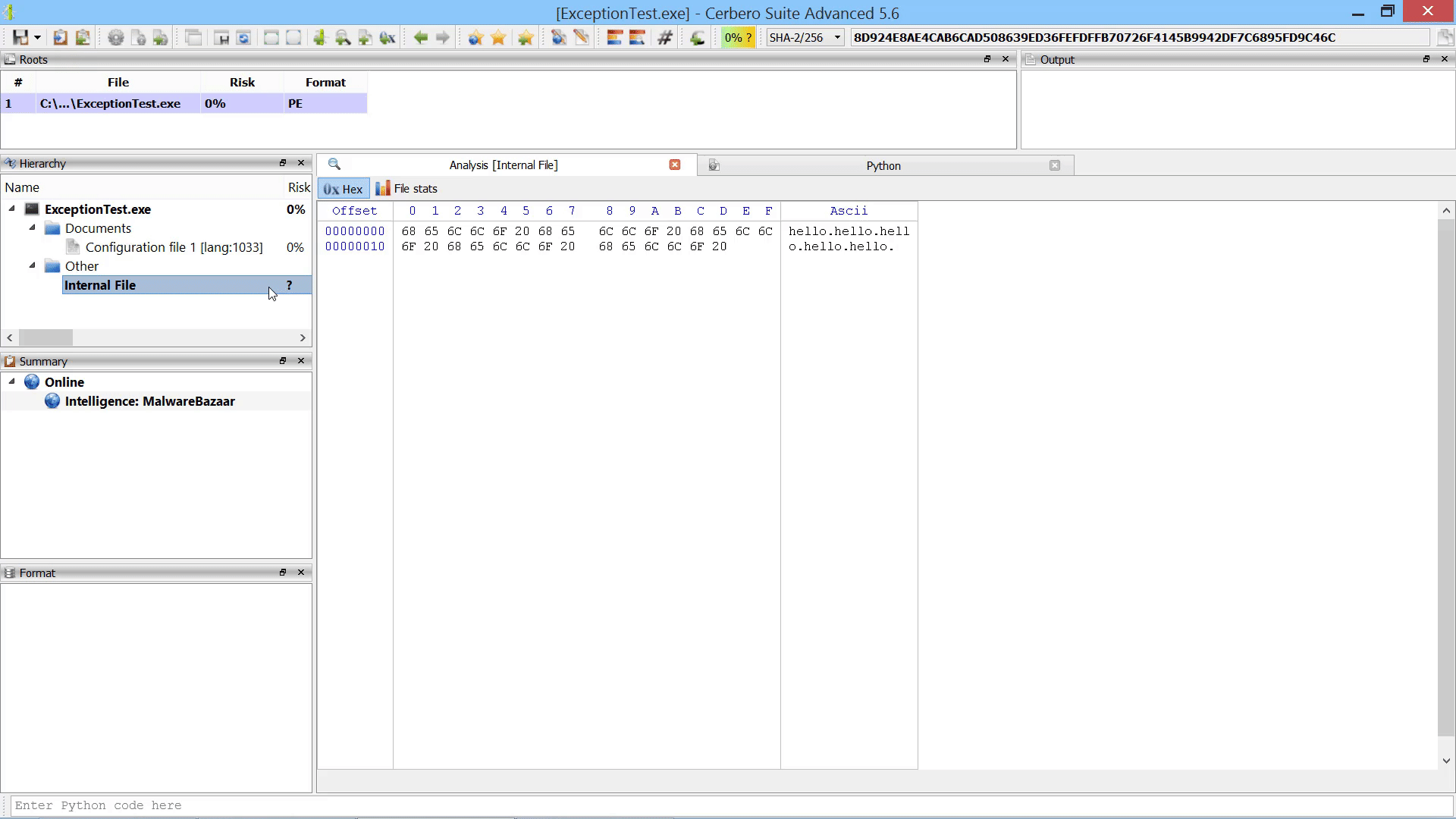
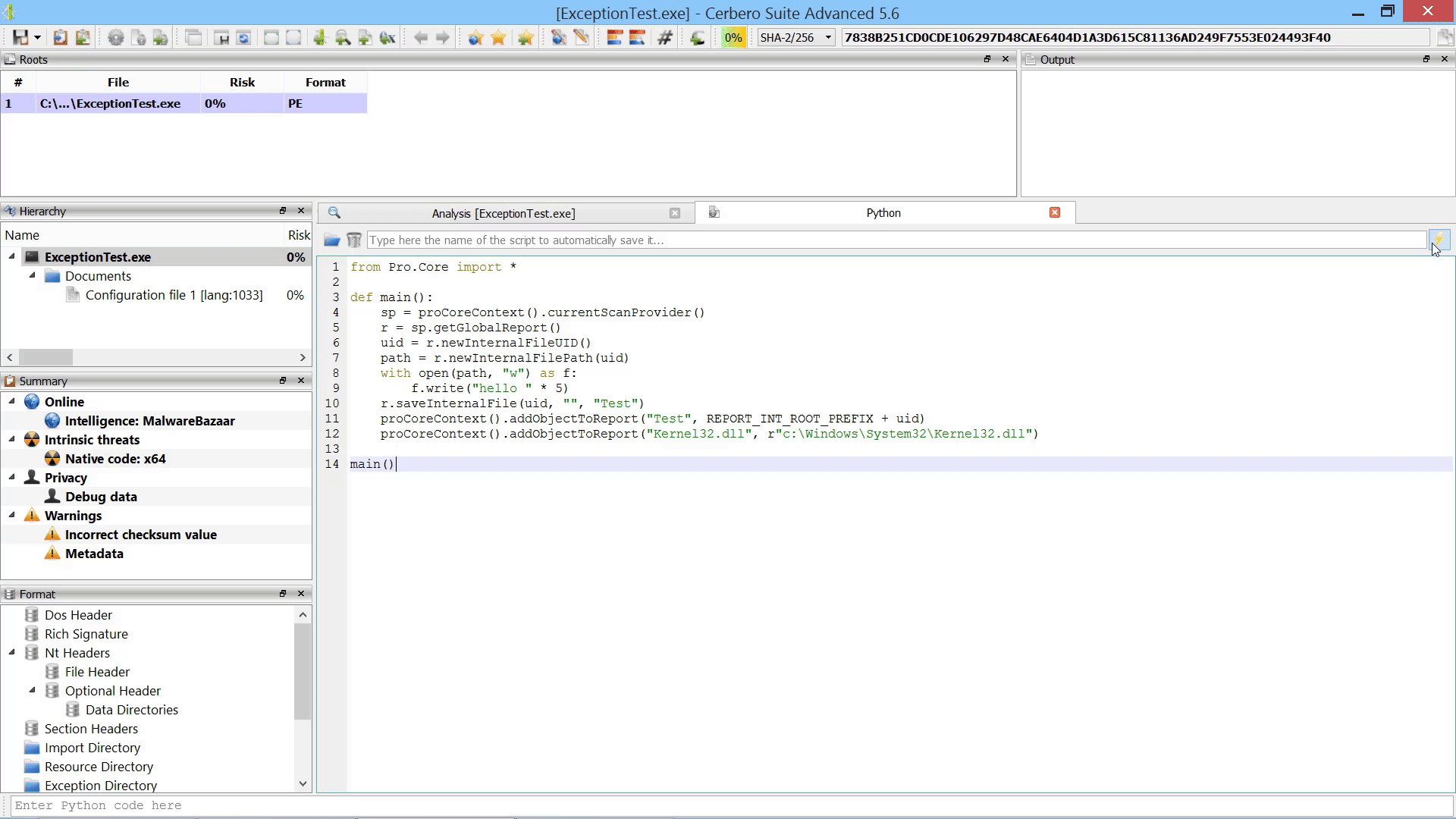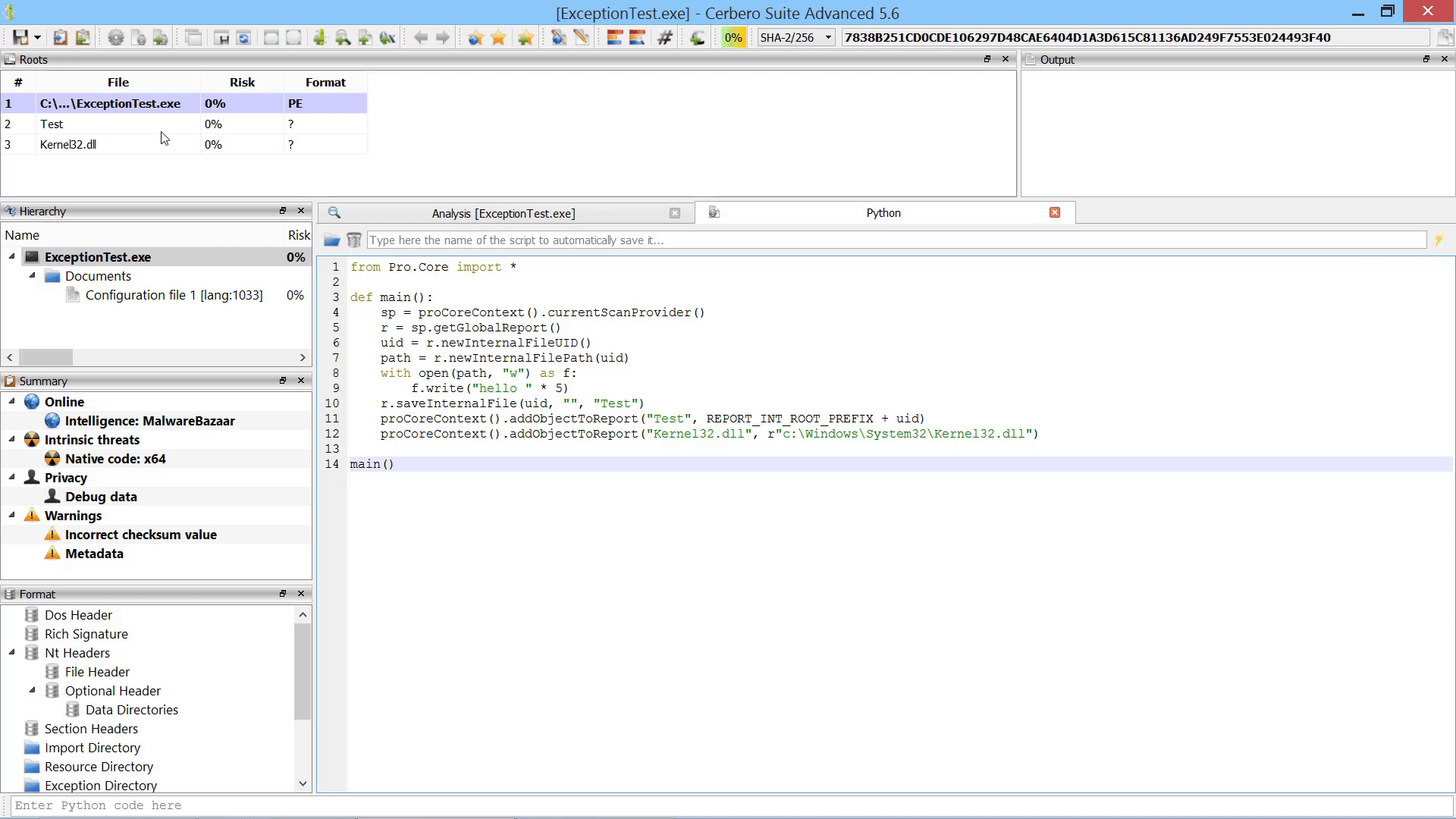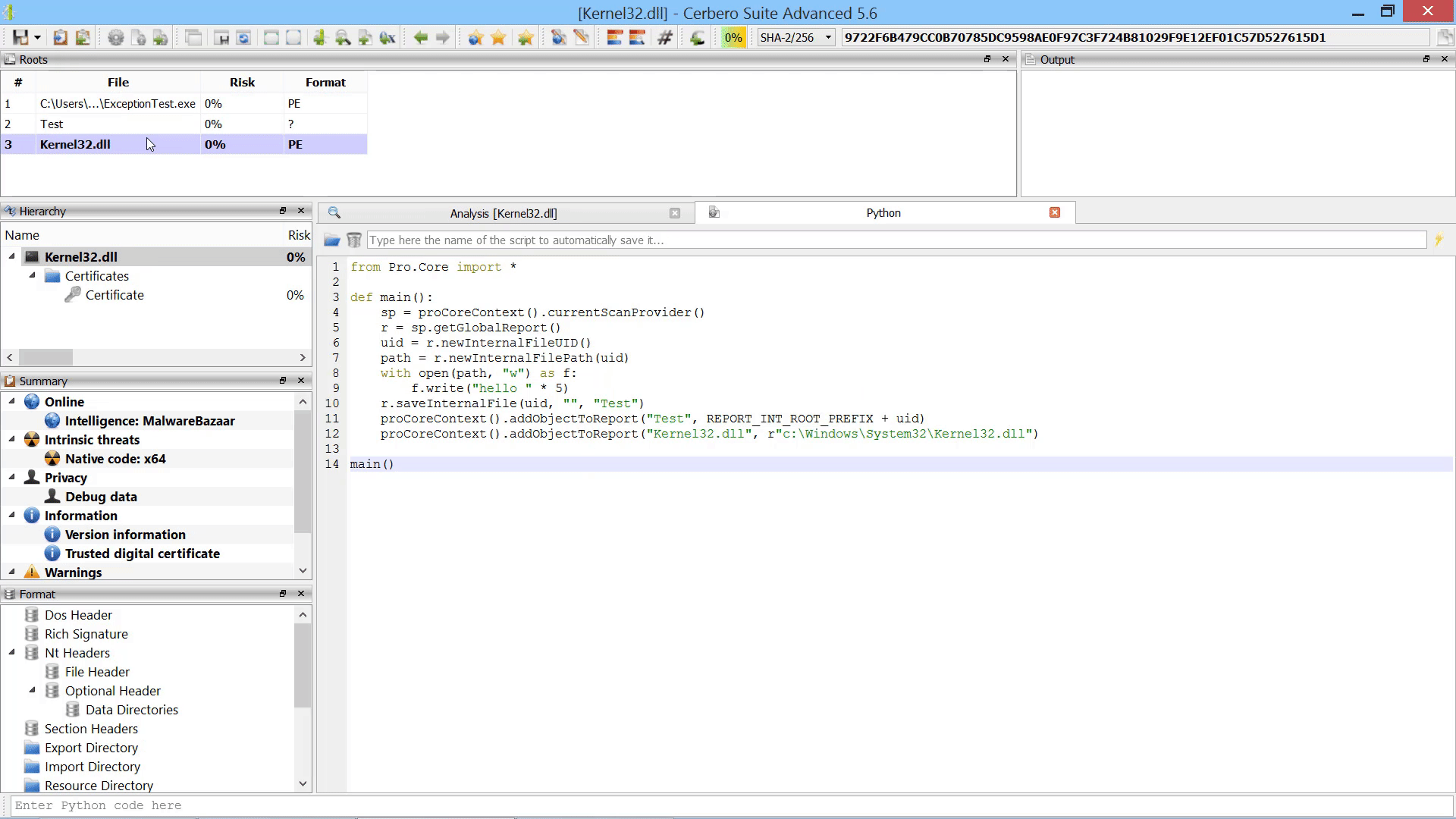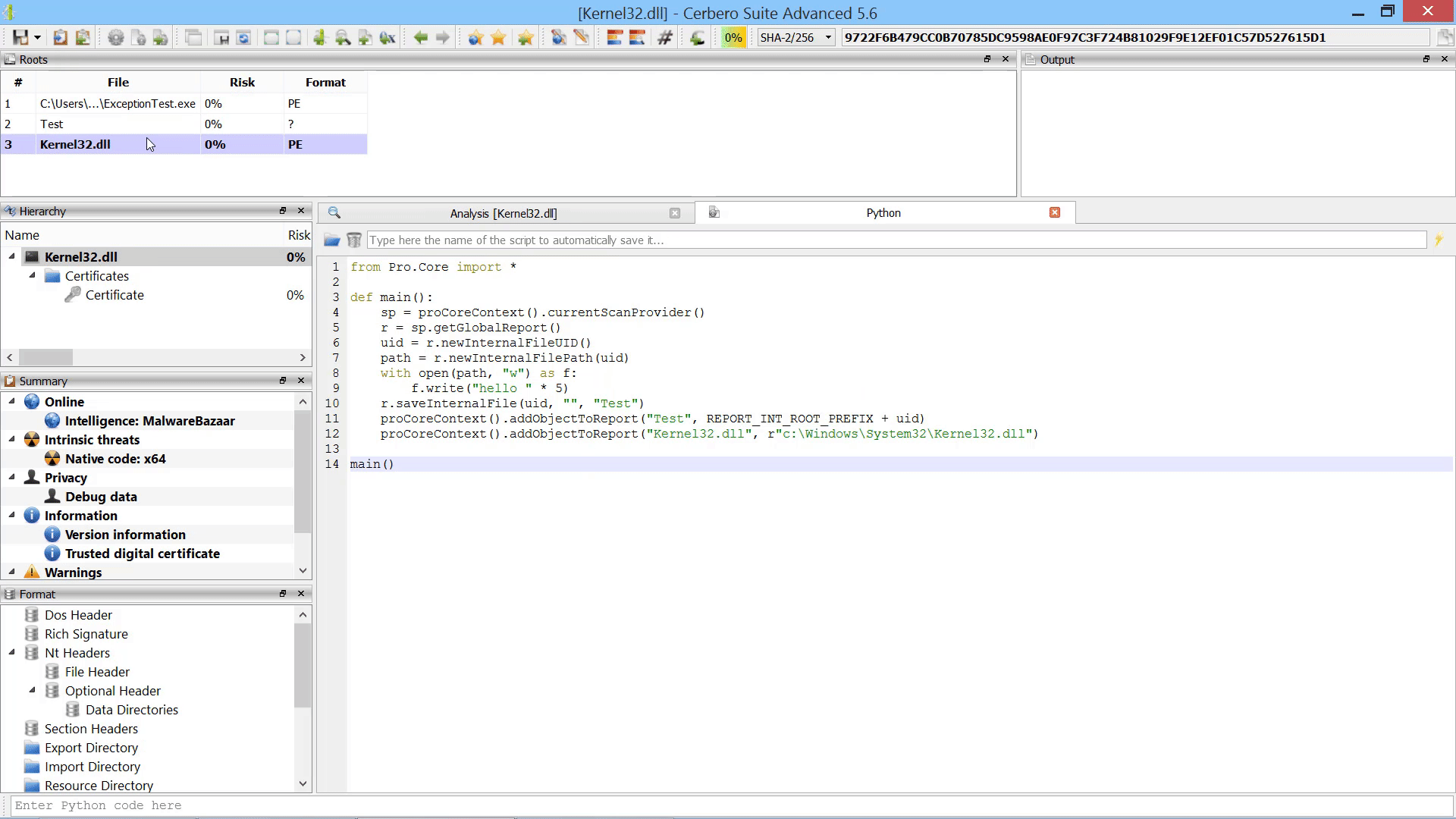
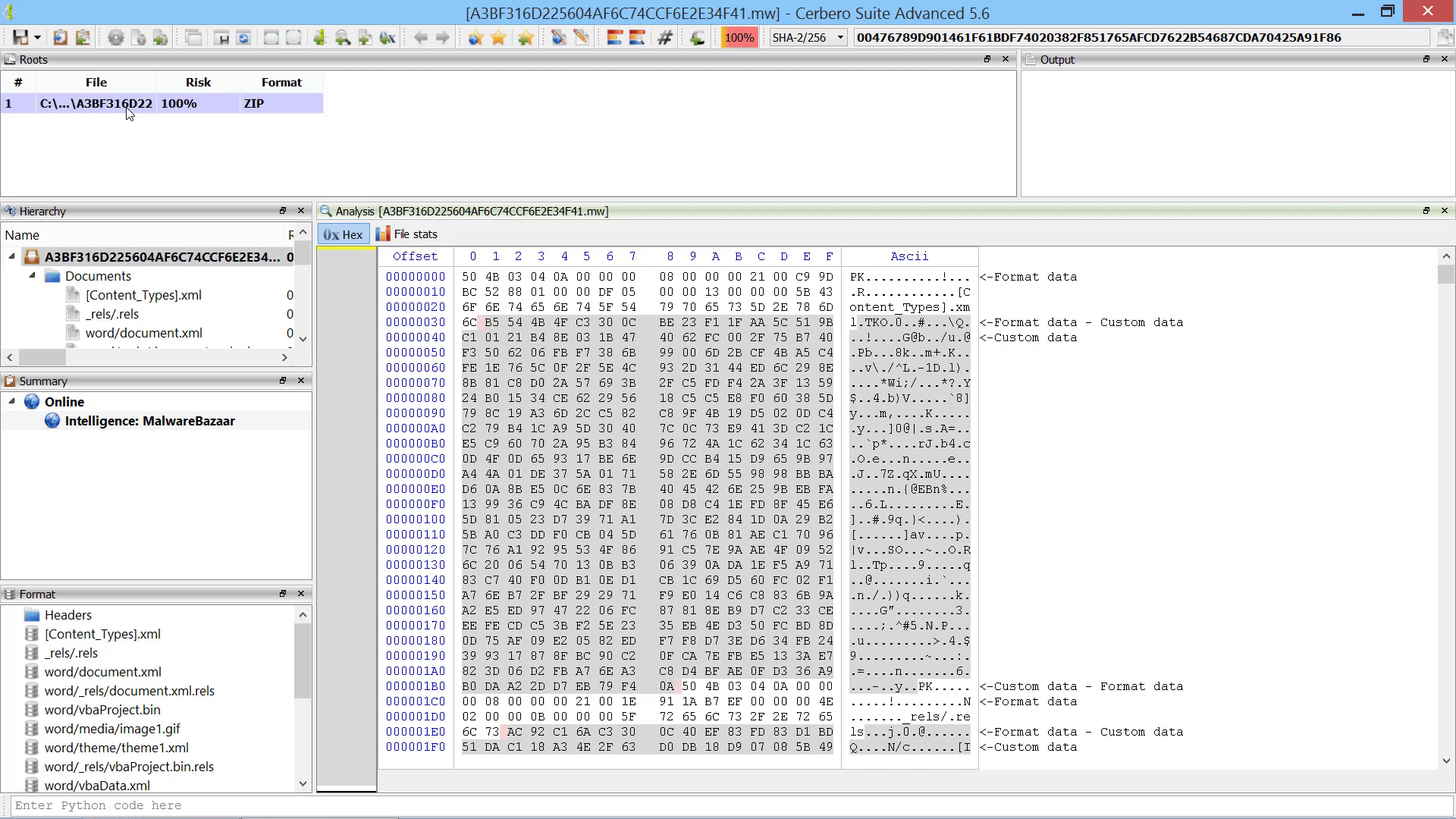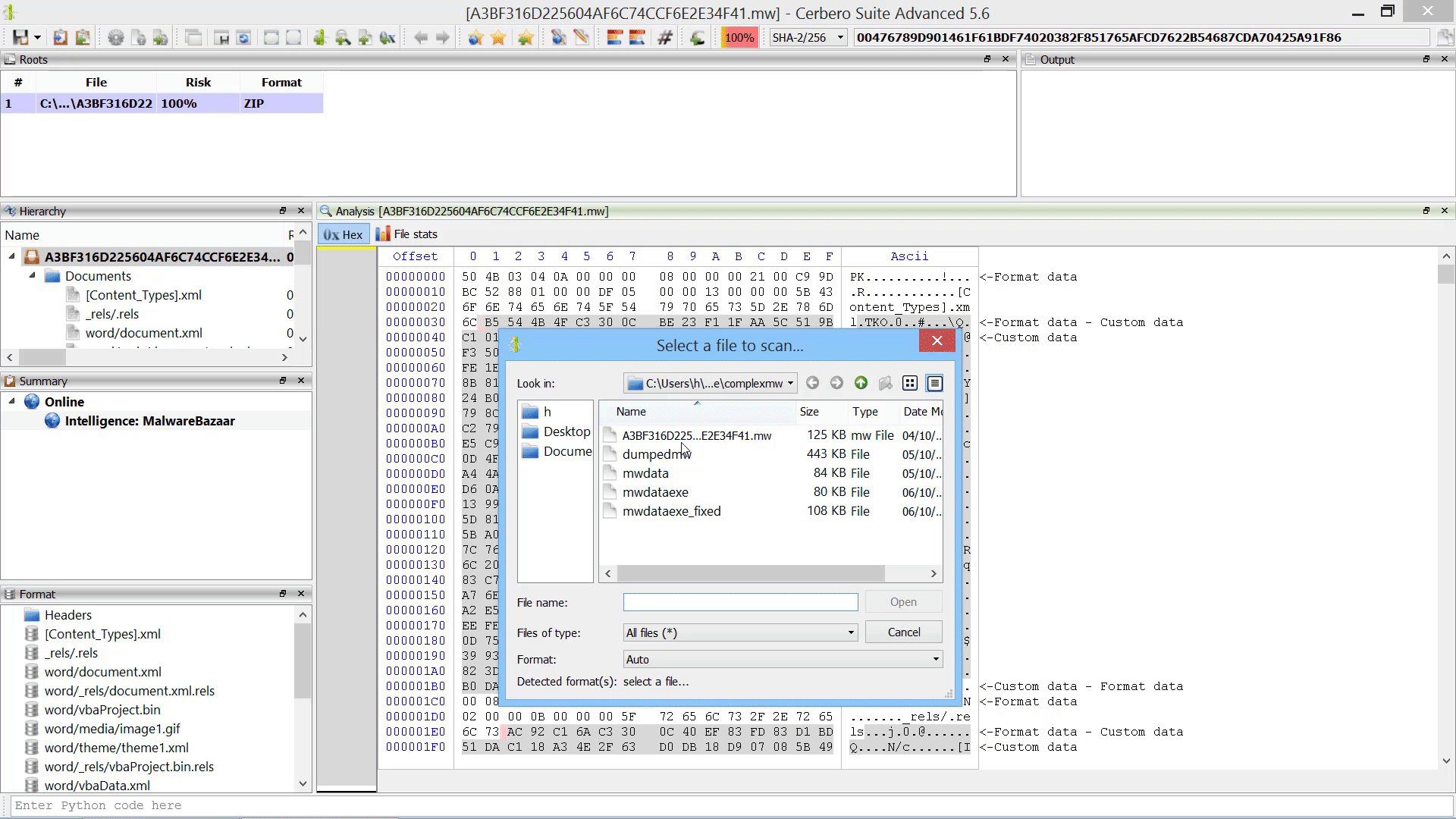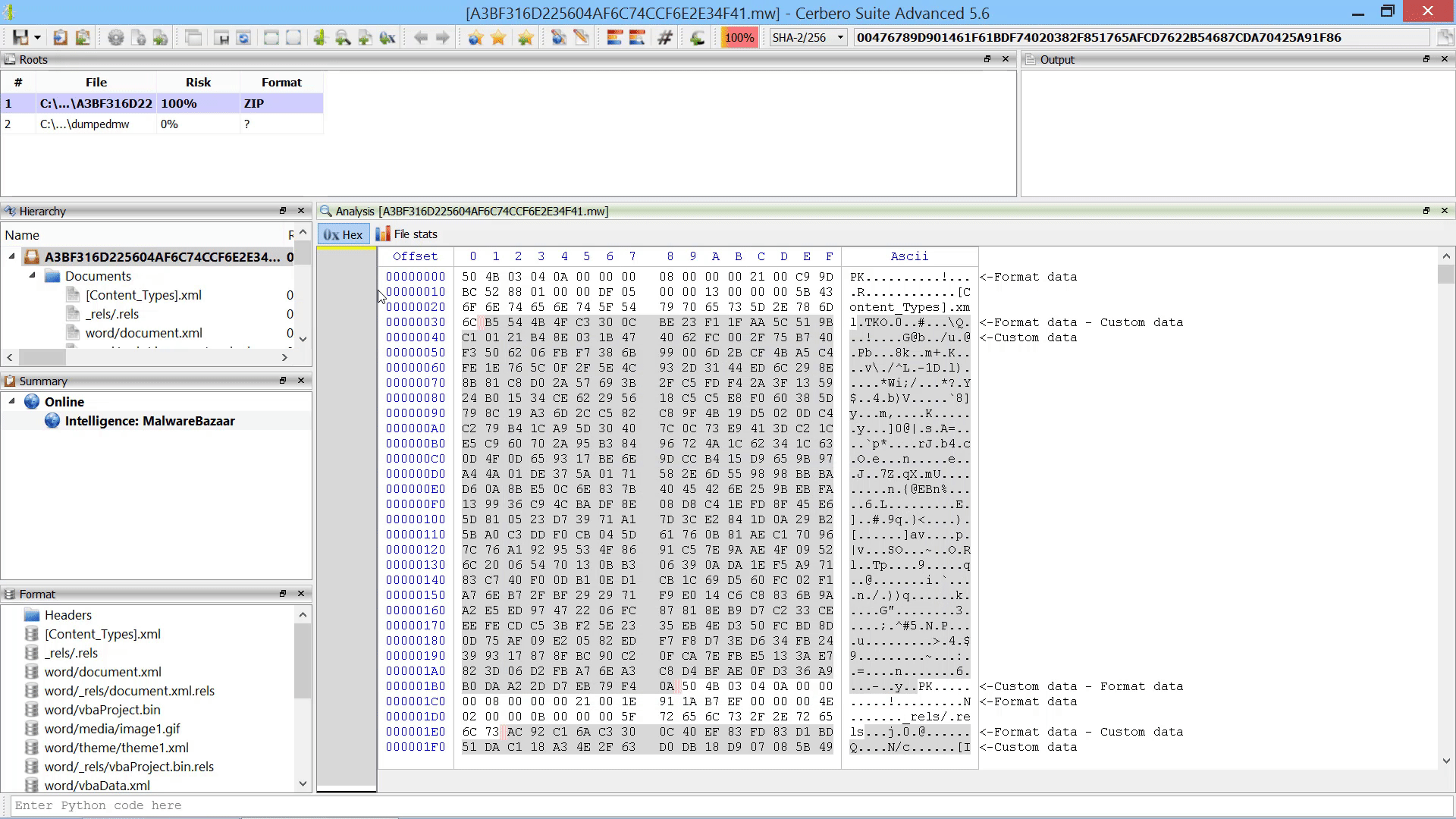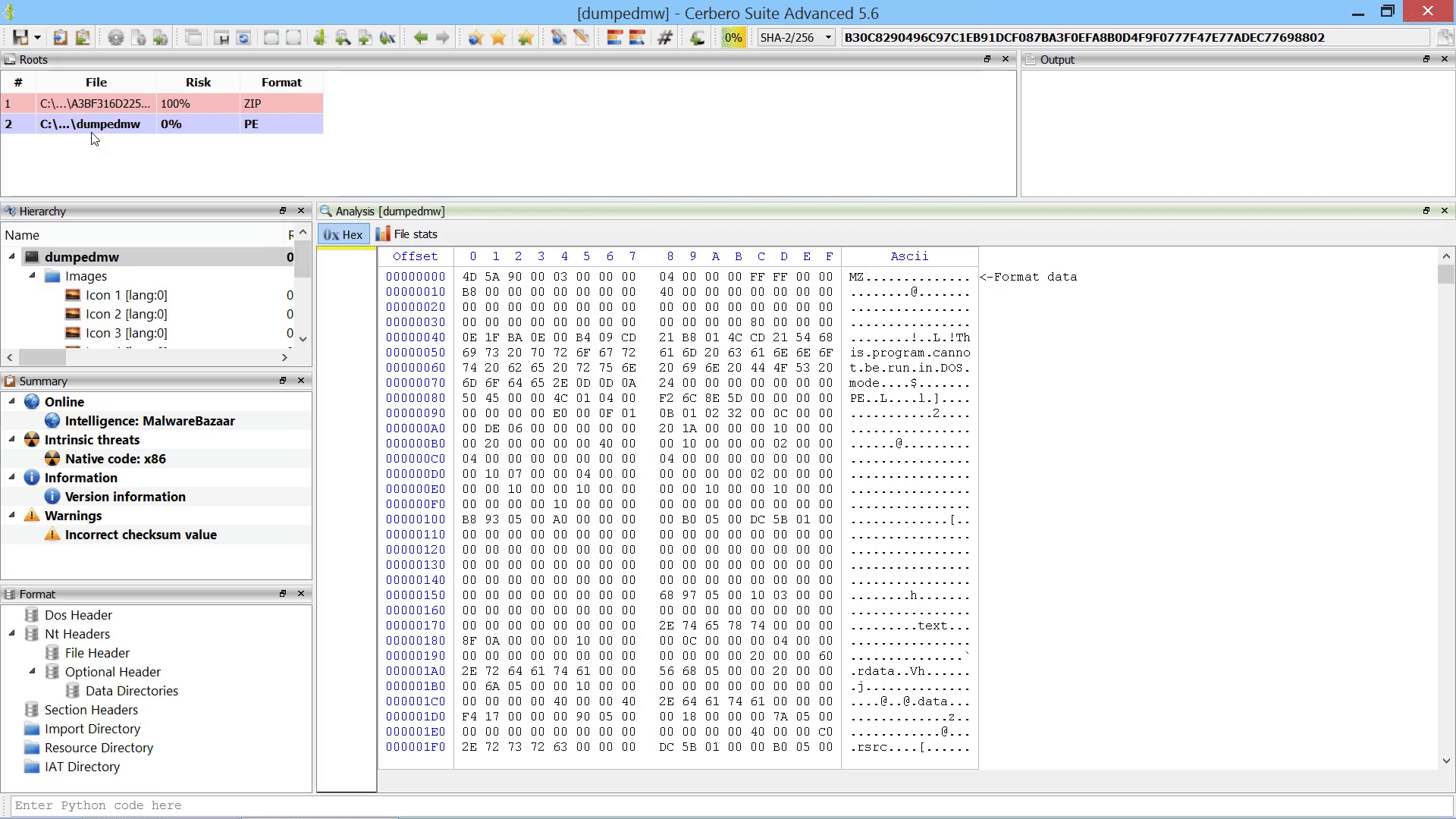
Furthermore, we added the capability to add new root entries to a report by letting the user choose files from disk. This can also be performed programmatically.
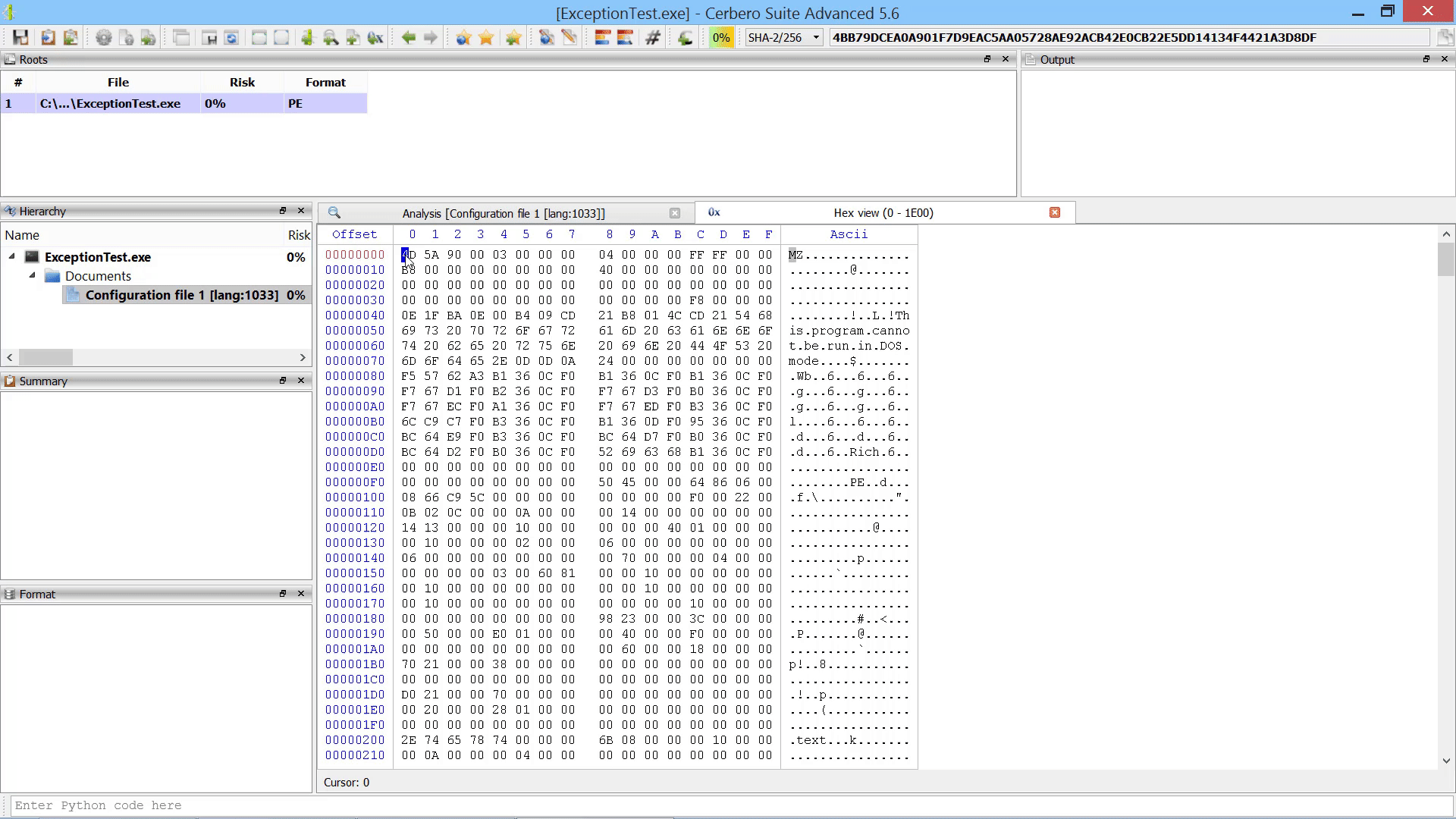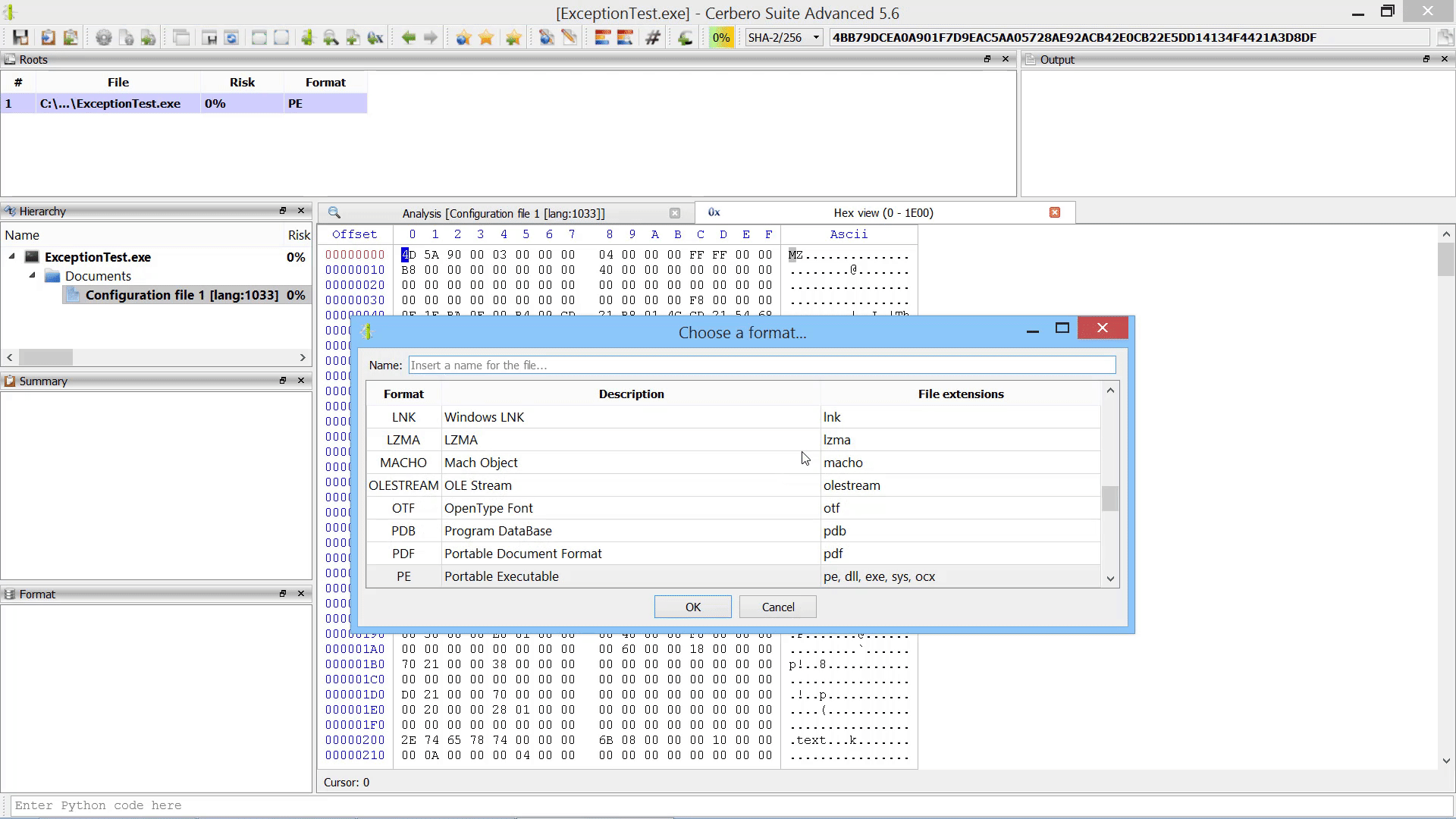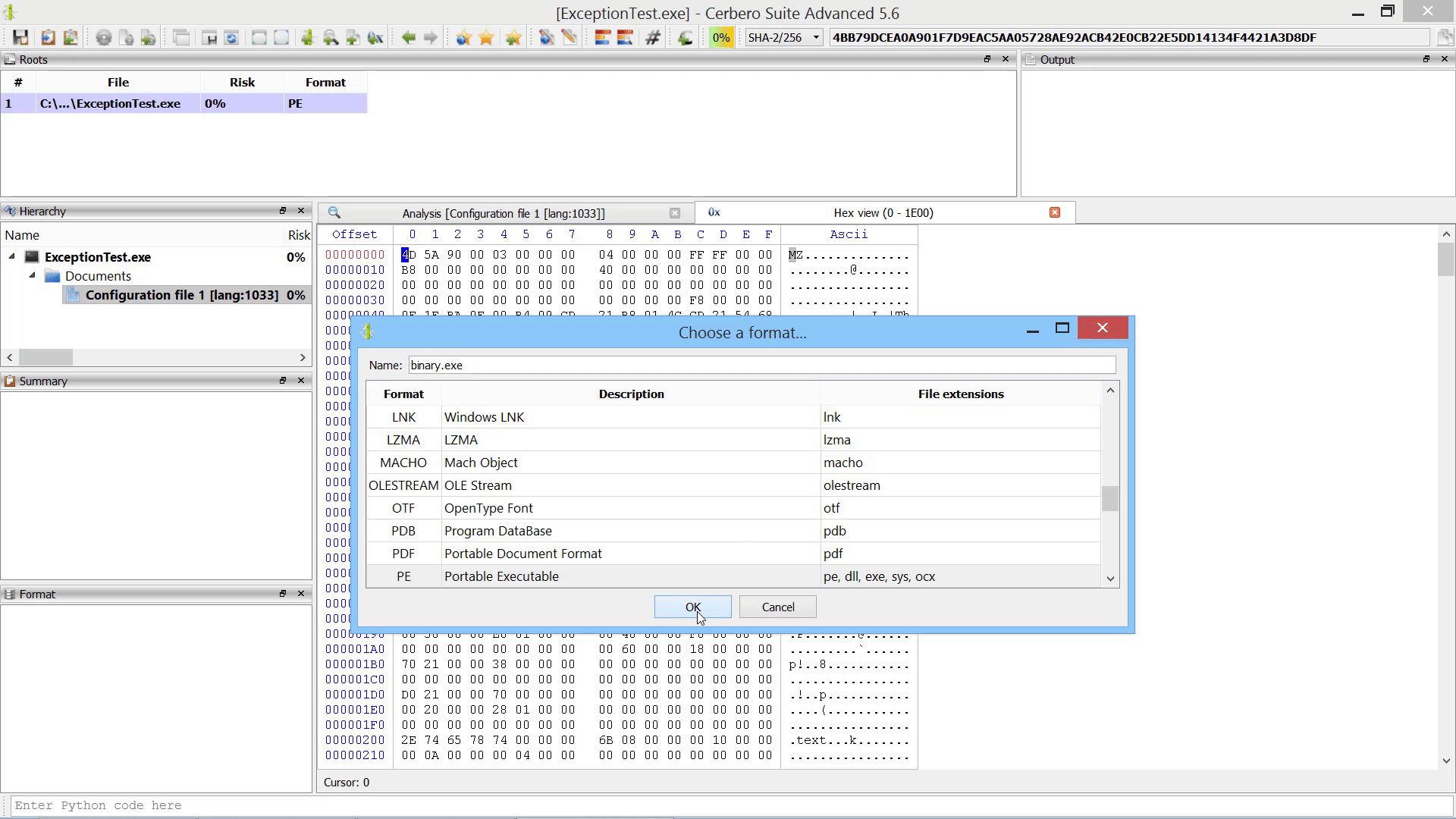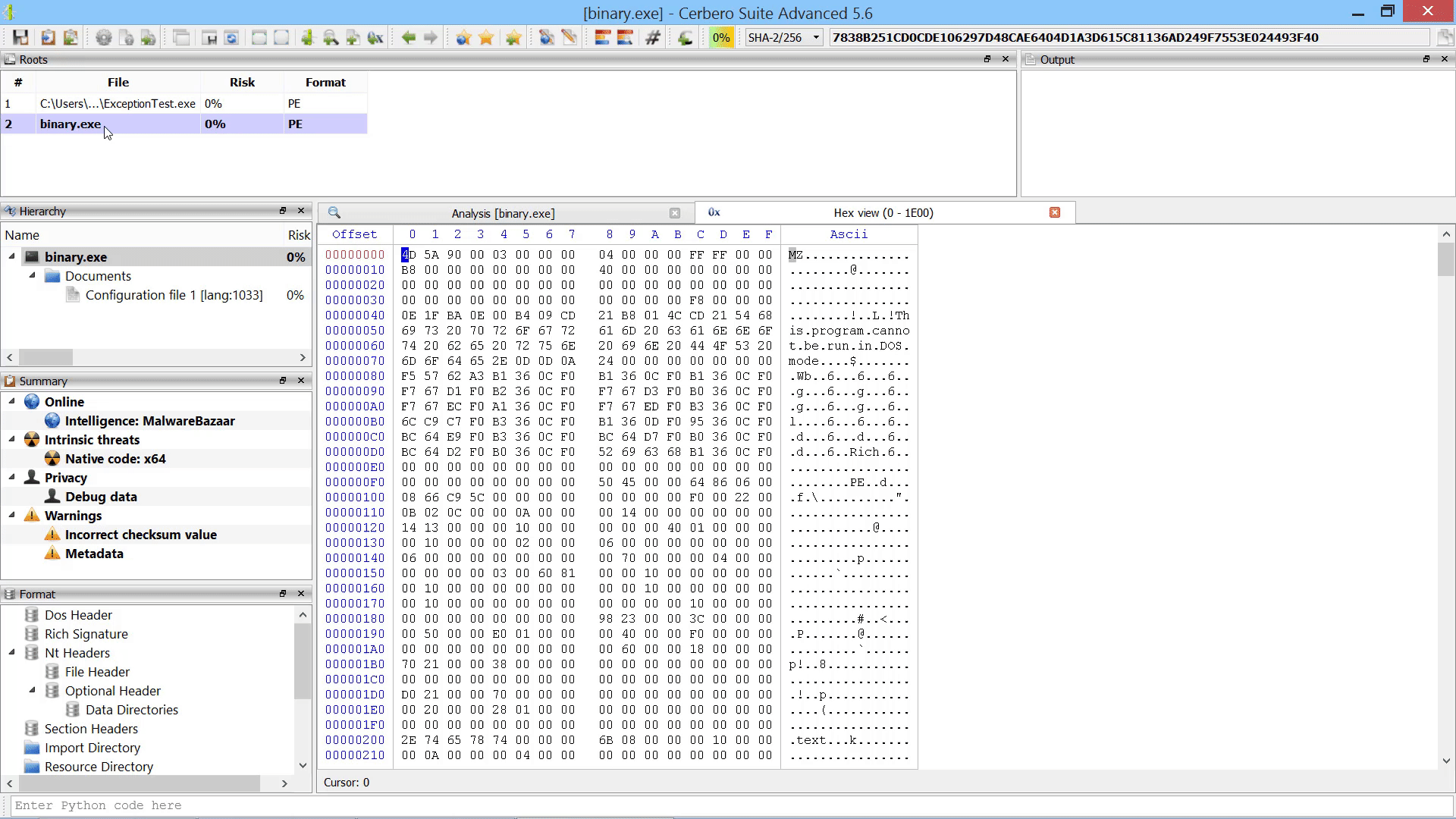
Last but not least, we added the capability to promote the data in a hex view to a root file in the report.
You can read more about the topic in our dedicated post.
Add File To Report Action
As already mentioned this in the paragraph of the after-scanning actions, we added the capability to add new root entries to a report by letting the user choose files from disk.
If added from code, root entries can also reference internal files.
Promote Hex Data To Root File Action
As already mentioned this in the paragraph of the after-scanning actions, we added the capability to promote the data in a hex view to a root file in the report.
The data from the hex view is stored as an internal file and referenced from the root entry. The advantage over loading an embedded object from a hex view is that promoting the data to a root file isn’t limited to analysis hex views. In fact, this action can be performed from any hex view.
Added Core SDK APIs
While we routinely add new APIs to our SDK, this release comes with a larger number of new and improved APIs in the Core module.
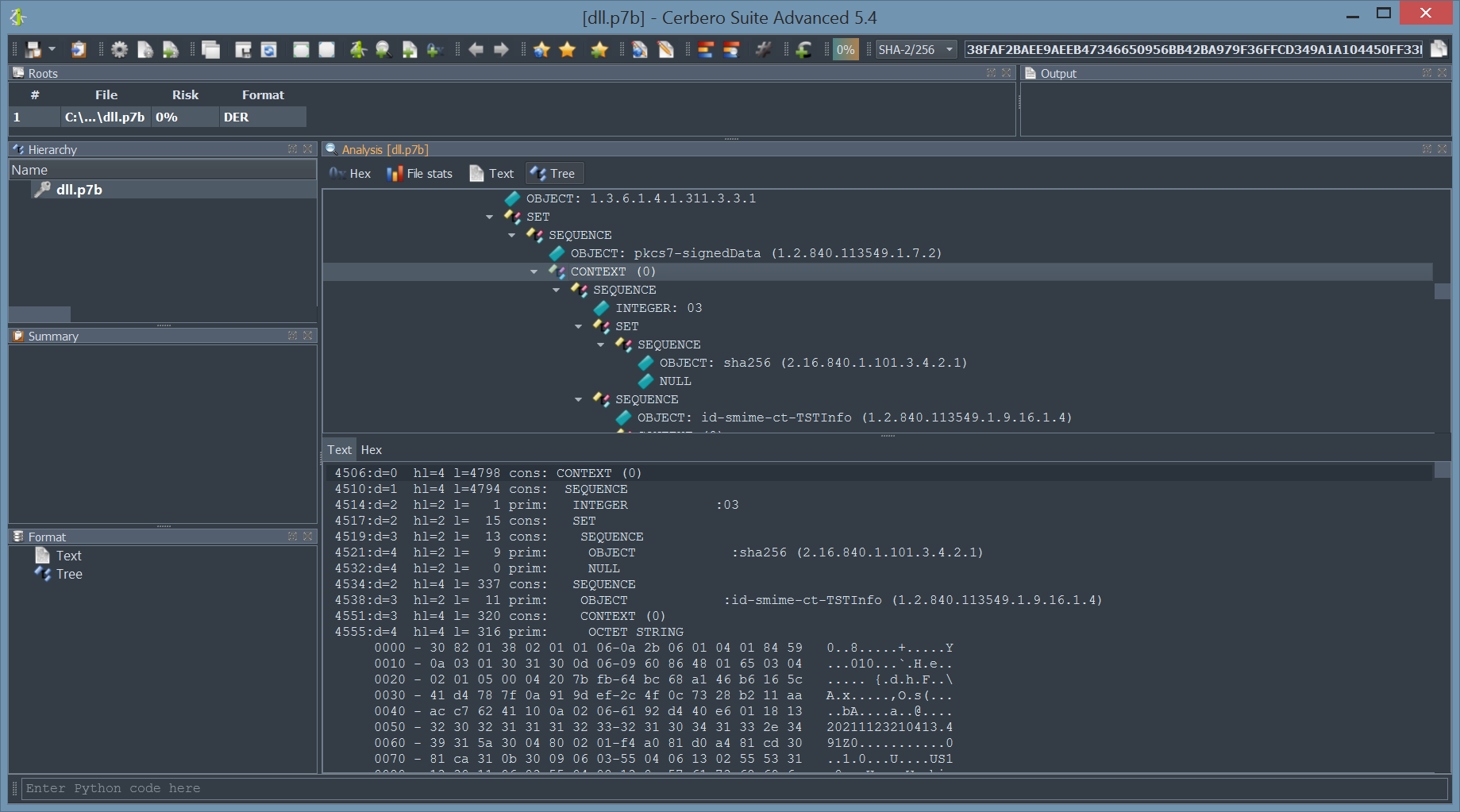
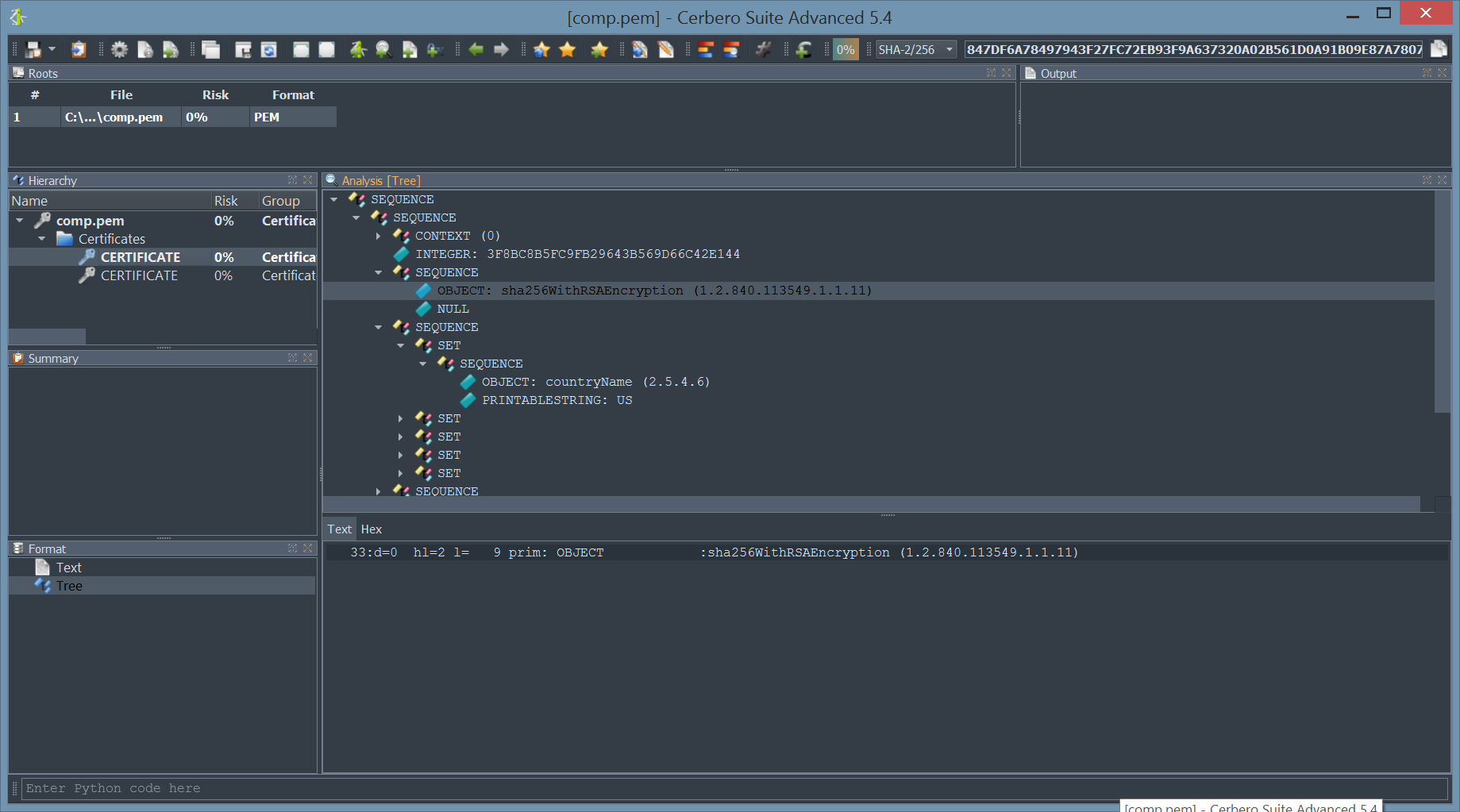
CAB & Certificates Modules Documentation
Having already completed the SDK documentation of our core modules, we have started documenting our file format modules and just finished the first two.
We have documented the API for parsing Microsoft Cabinet files.

And we have documented our comprehensive API for parsing certificate files in both DER and PEM encodings.
We’ll continue documenting our file format modules in the upcoming months.
Improved Settings Page
We have improved our settings page. Specifically, we have switched from a tab-based interfaced to a list-based one.
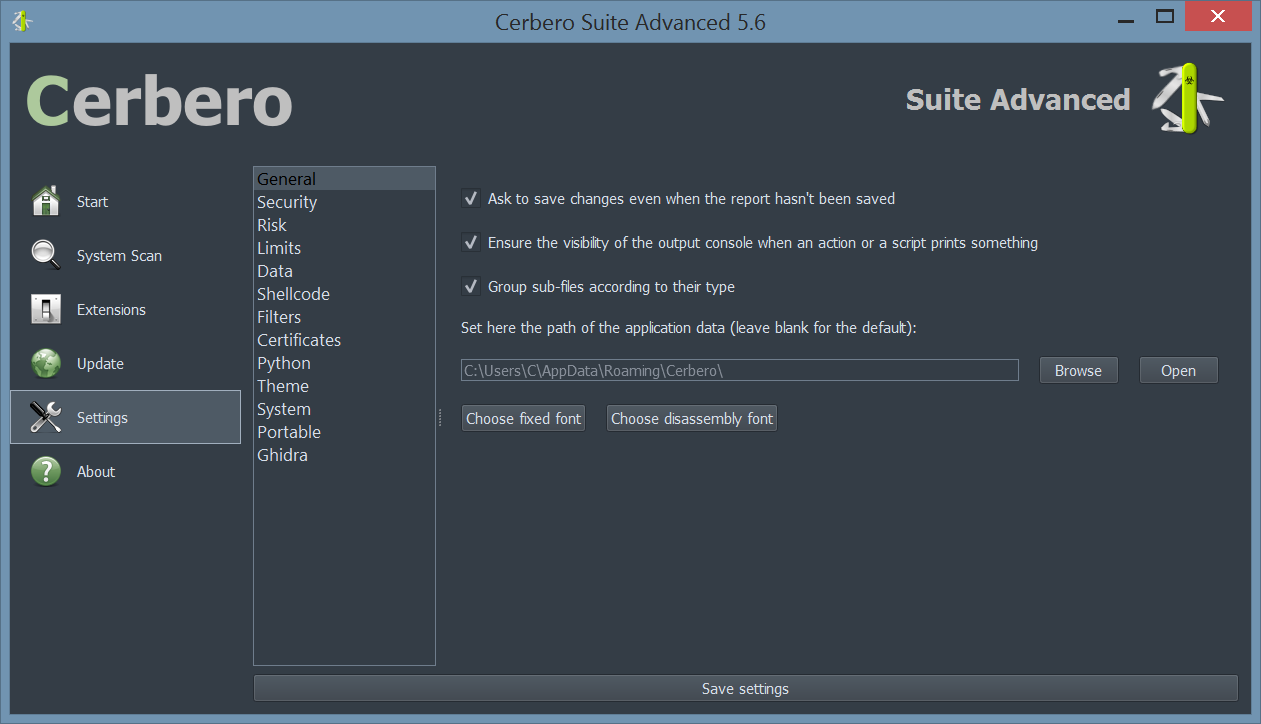
The reason for this change lies in the capability of plugins to add custom pages to the settings and a tab-based interfaced may get too cramped in the future.
Fixed Python GIL Issues
We fixed a number of issues related to the Python Global Interpreter Lock. These issues would show themselves rarely but could lead to crashes under the right conditions when using scan providers implemented in Python.
VBA Extraction Code Page Support
A user reported issues with VBA extraction related to code page support. The extracted VBA now correctly shows non-ascii characters.

We have also made other minor improvements and fixed a few minor issues.