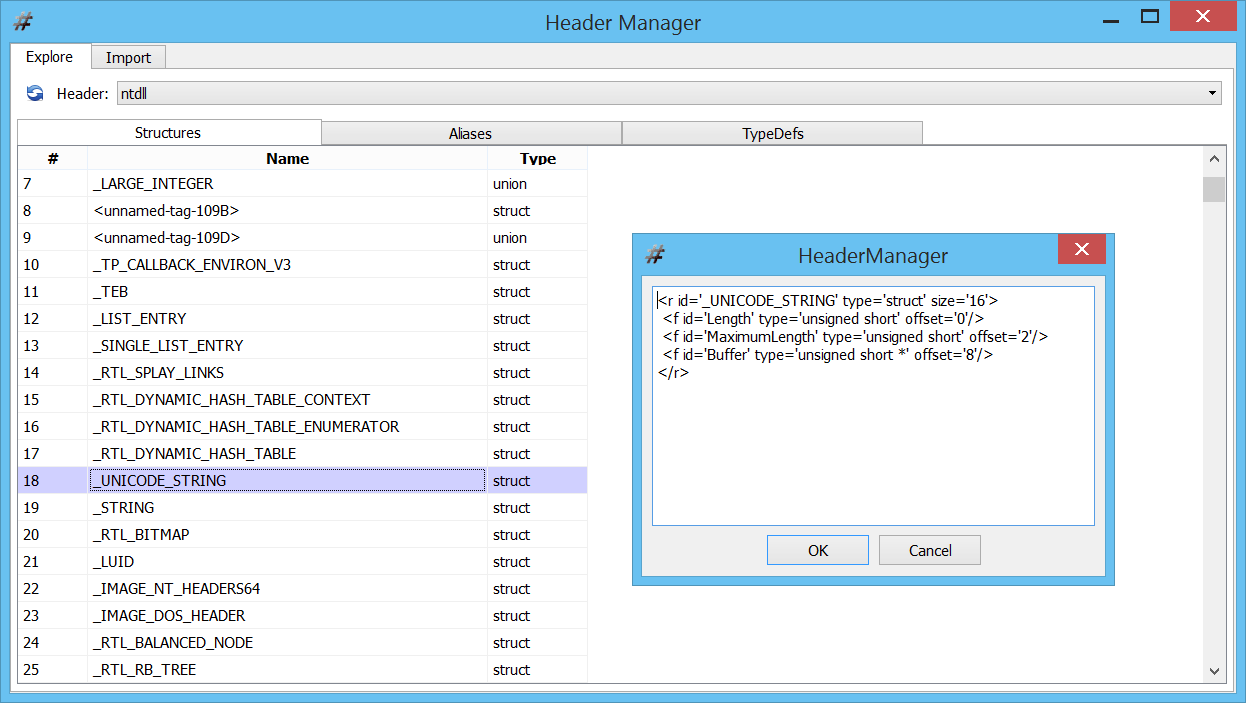
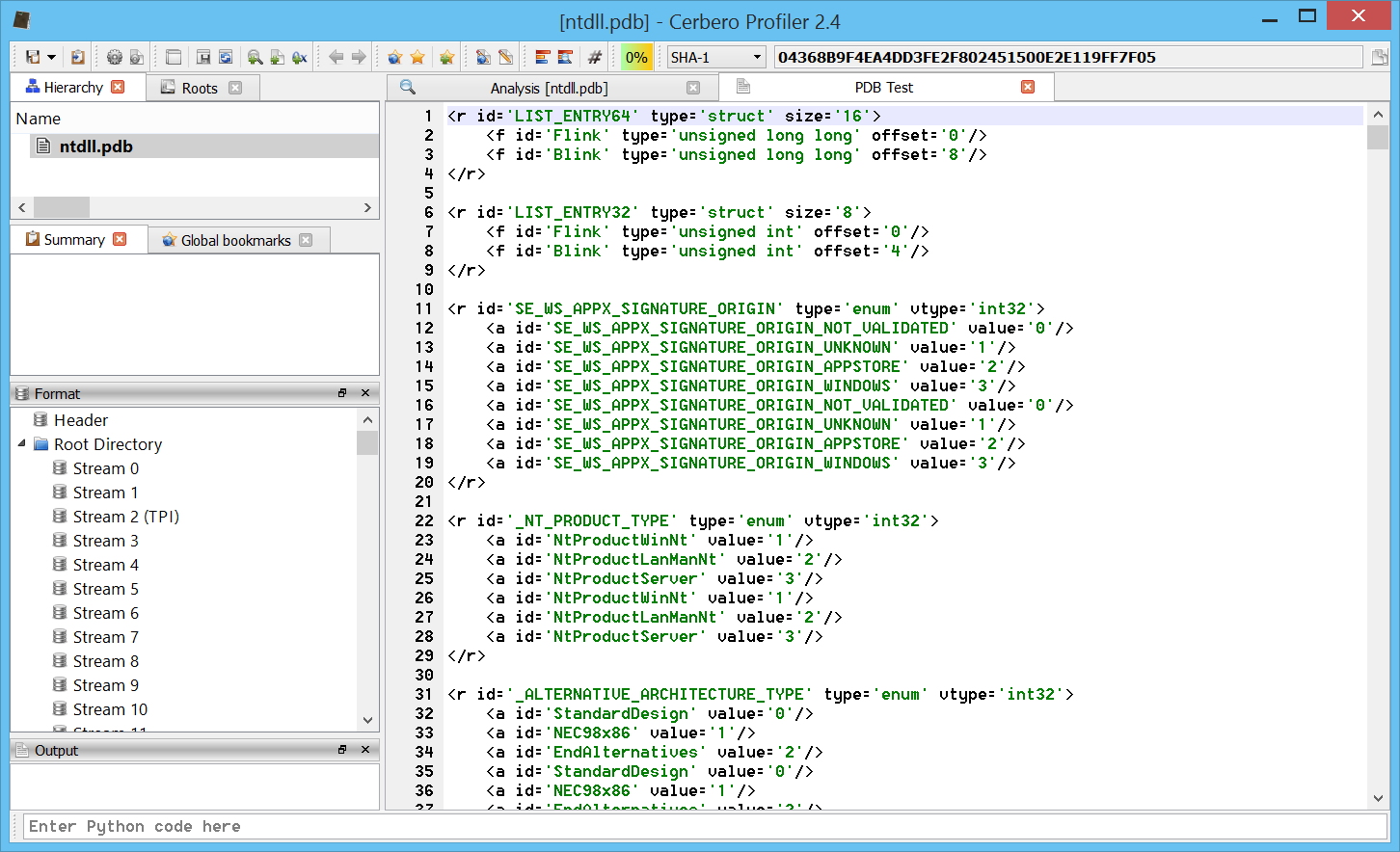
Profiler 2.4 is out with the following news:
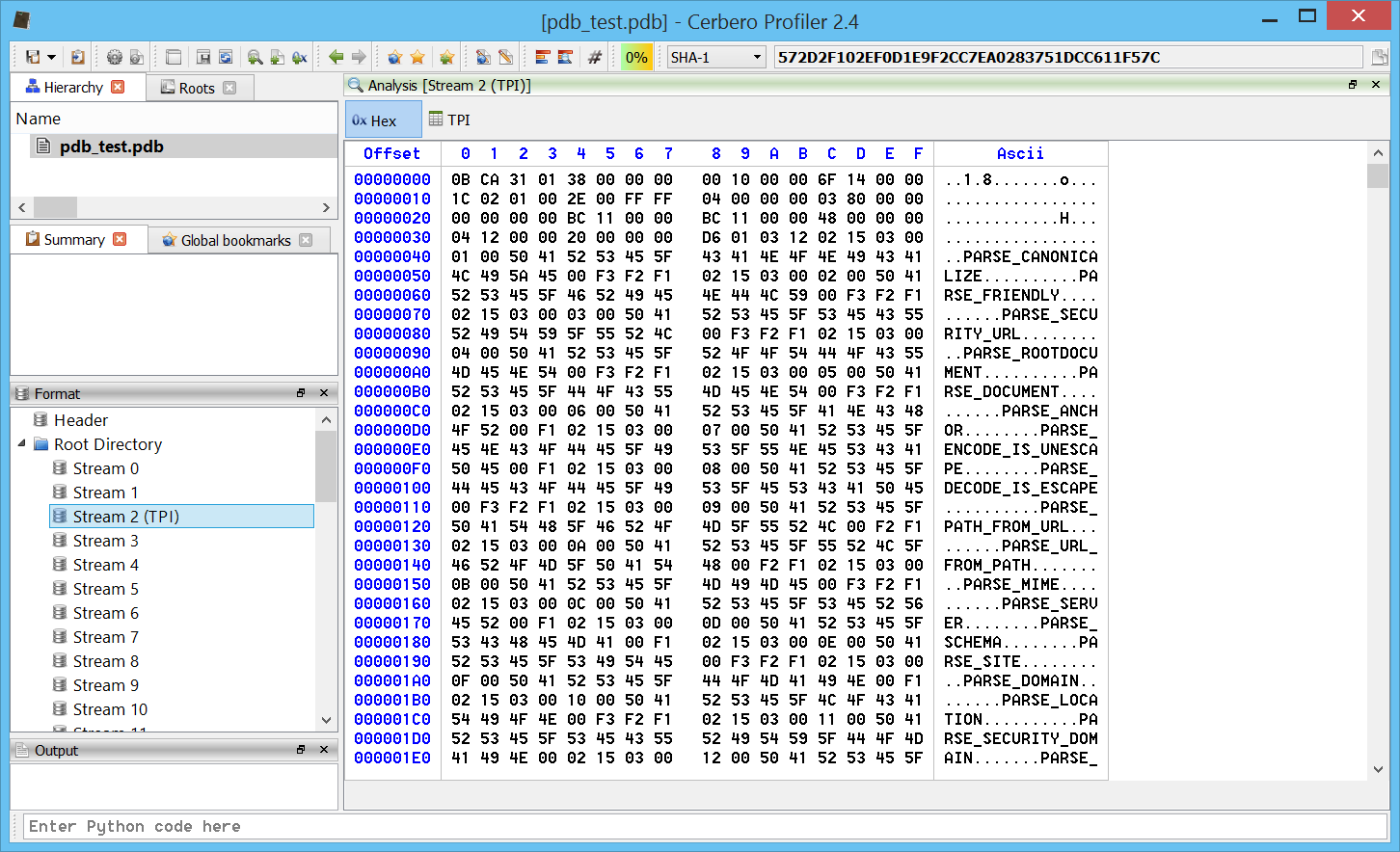
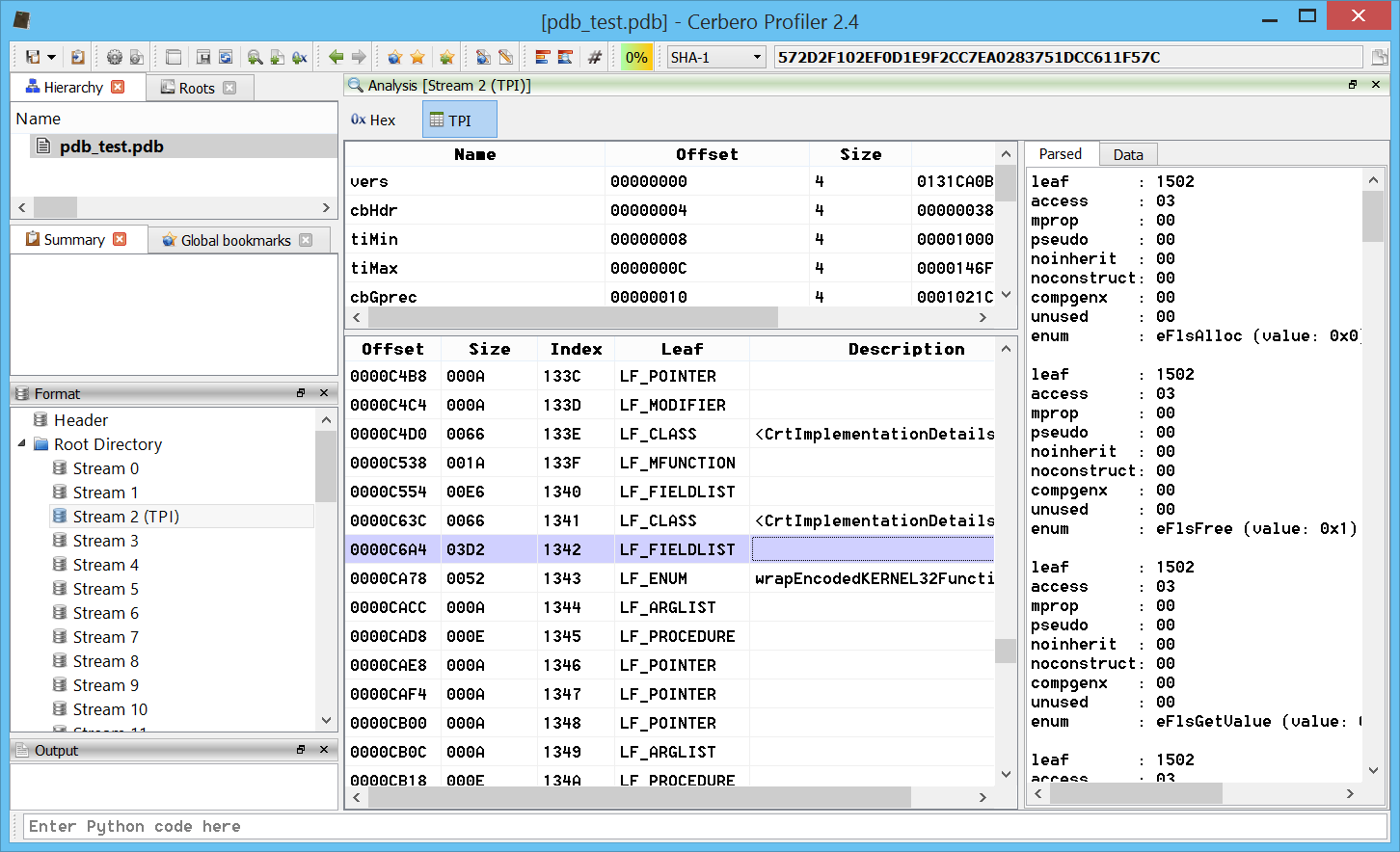
– added initial support for PDB files (including export of types)
– added support for Windows Encoded Scripts (VBE, JSE)
– introduced fixed xml structures
– added automatic string decoding in struct tables
– added Python string command line execution
– remember the last selected logic group
– fixed missing support for wchar_t in C types
– updated Qt to 5.4.1
– various bug fixes
While the most important newly introduced feature is the support for PDB files, here are some interesting new features:
Support for Windows Encoded Scripts (VBE, JSE)
Windows encoded scripts like VBE and JSE files (the encoded variants of VBS and JS script files) are now supported and automatically decoded.
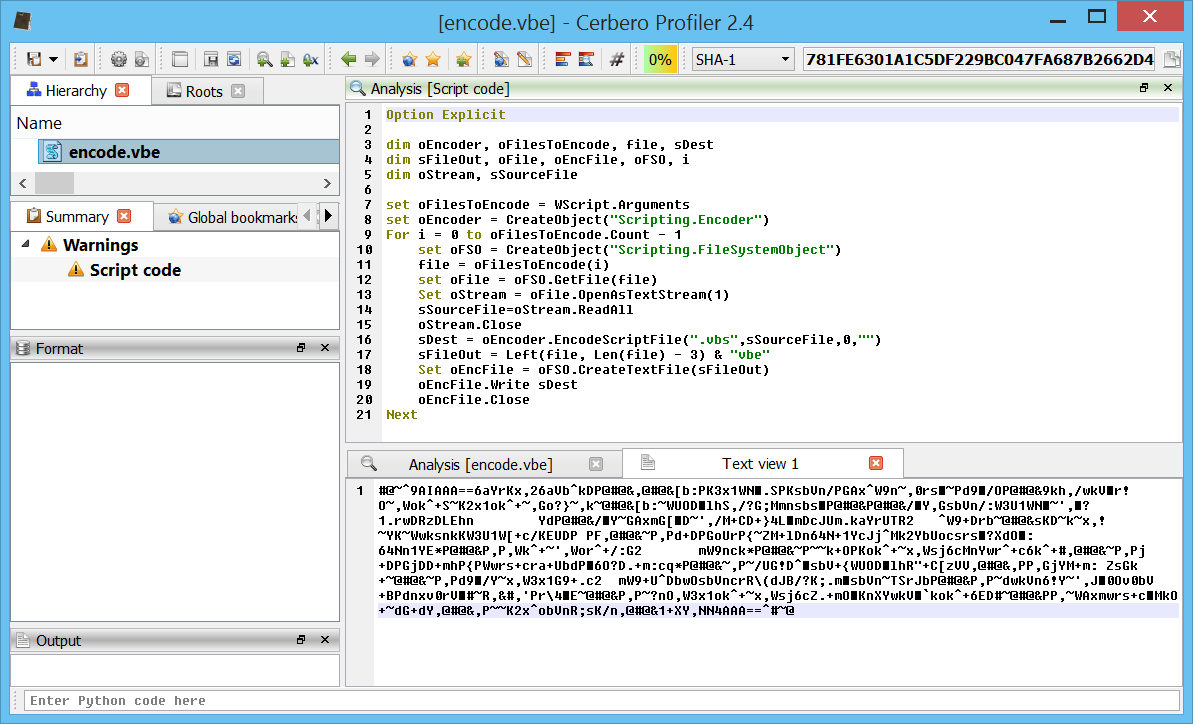
In the screen-shot you can see the decoded output of an encoded file (showed at the bottom).
Automatic string decoding in struct tables
A very basic feature: byte-arrays in structures are automatically checked for strings and in case decoded.
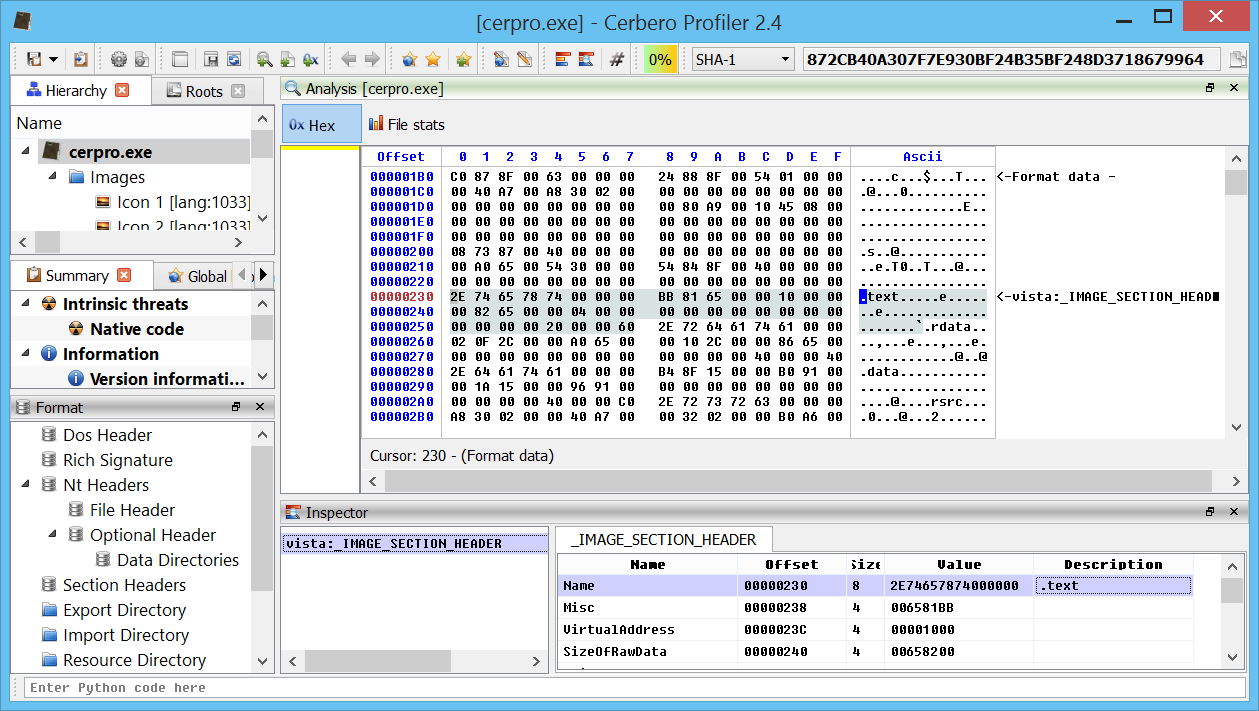
(notice the section name automatically displayed as ascii string)
Python string command line execution
Apart from executing script files passed as command line arguments, now it is also possible to execute Python statements directly passed as argument.
For instance:
cerpro -c -e "from Pro.Core import *;proCoreContext().msgBox(0, \"Hello world!\")" The optional argument ‘-c’ specifies to not display the UI.
Enjoy!