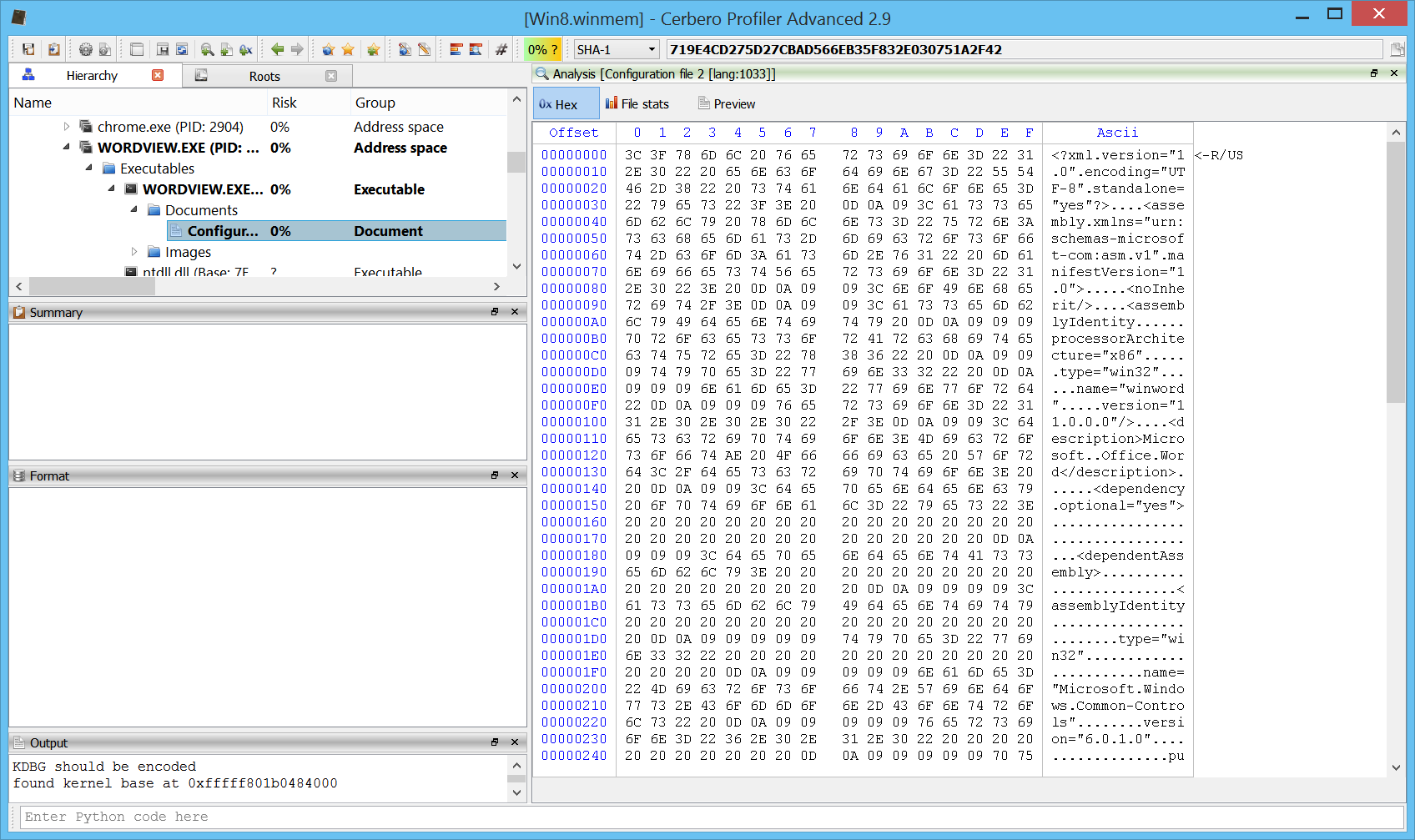
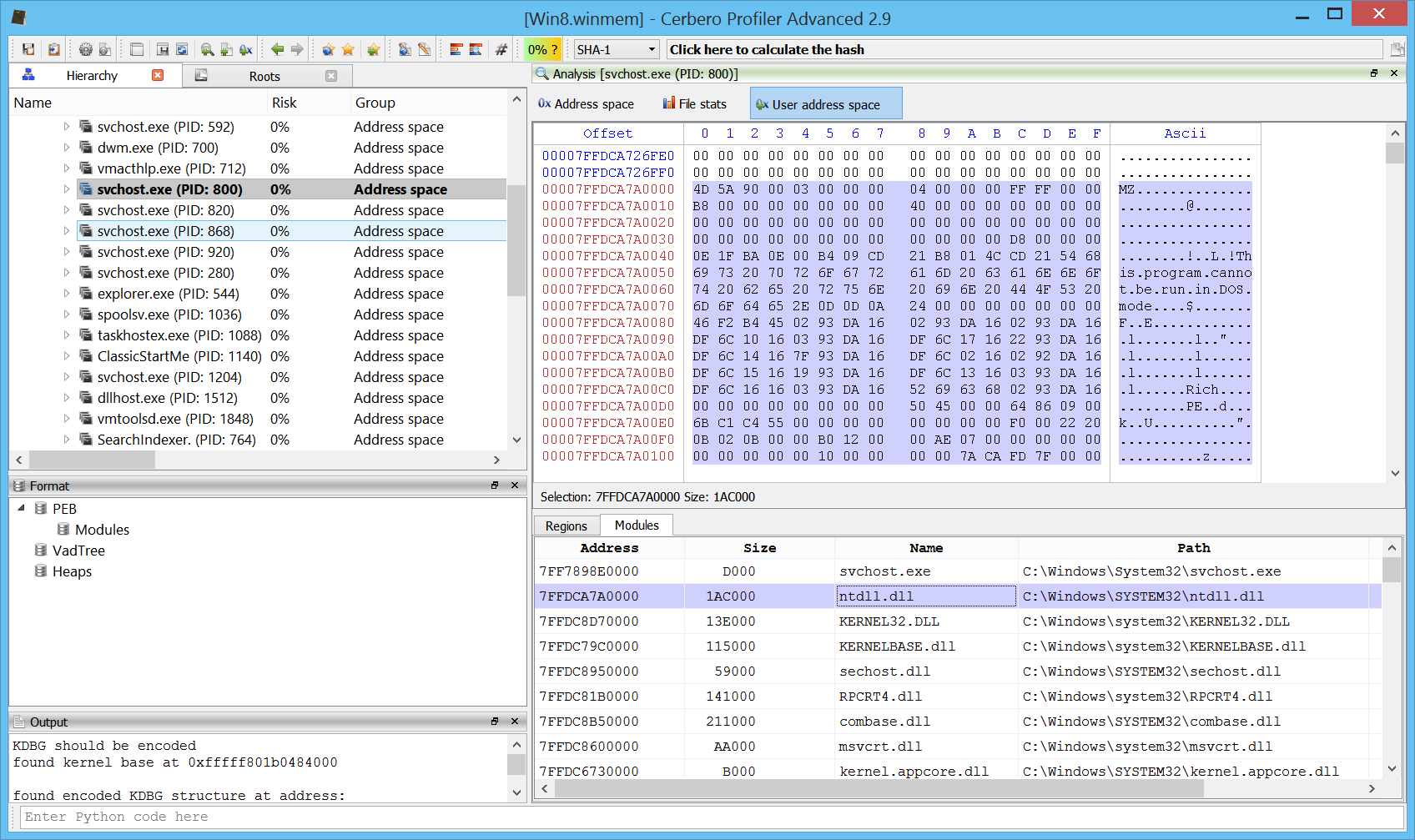
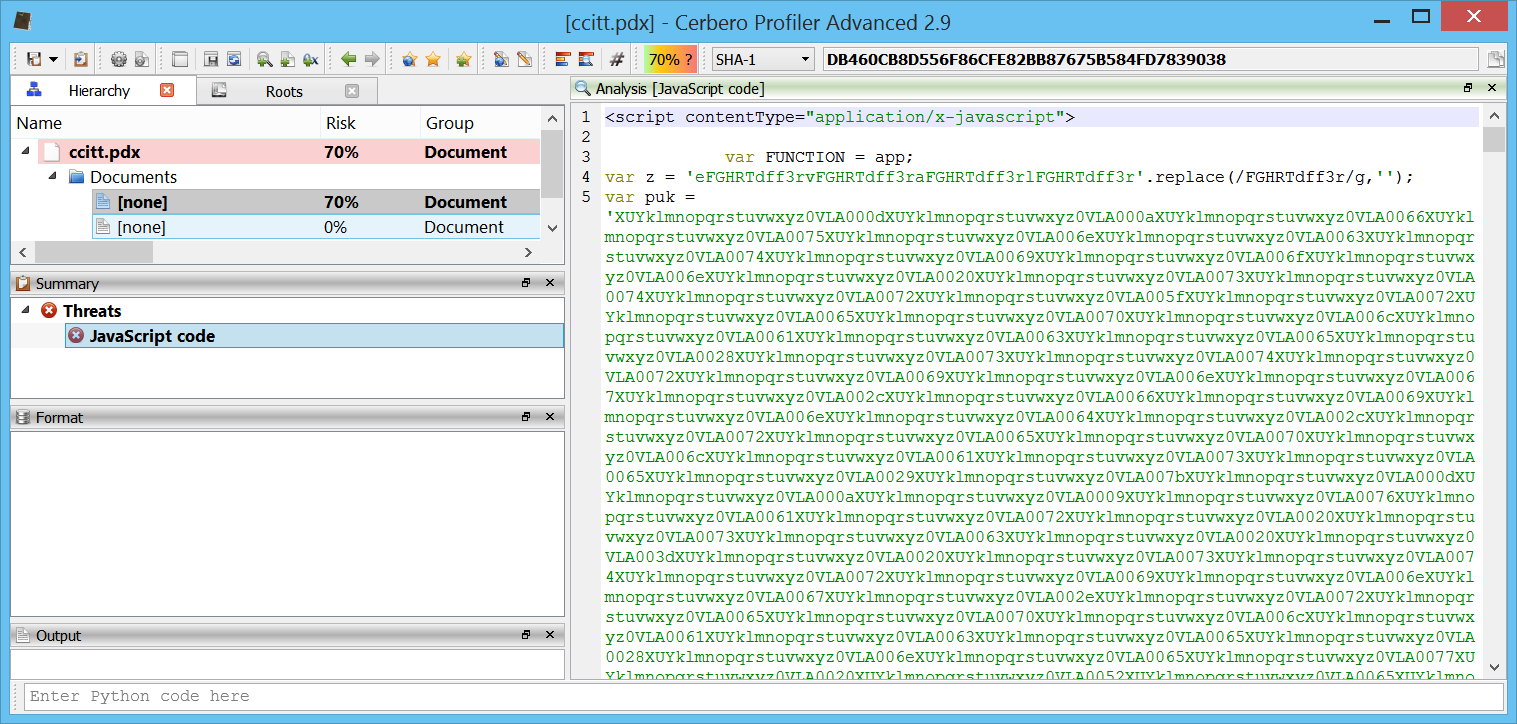
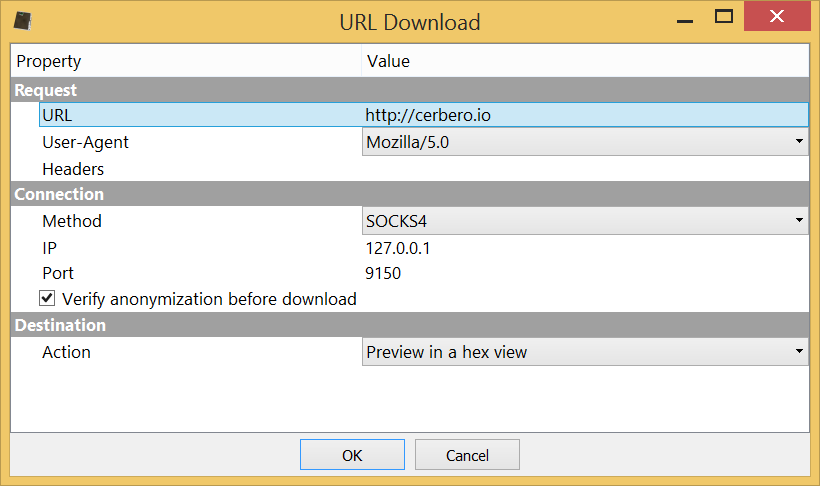
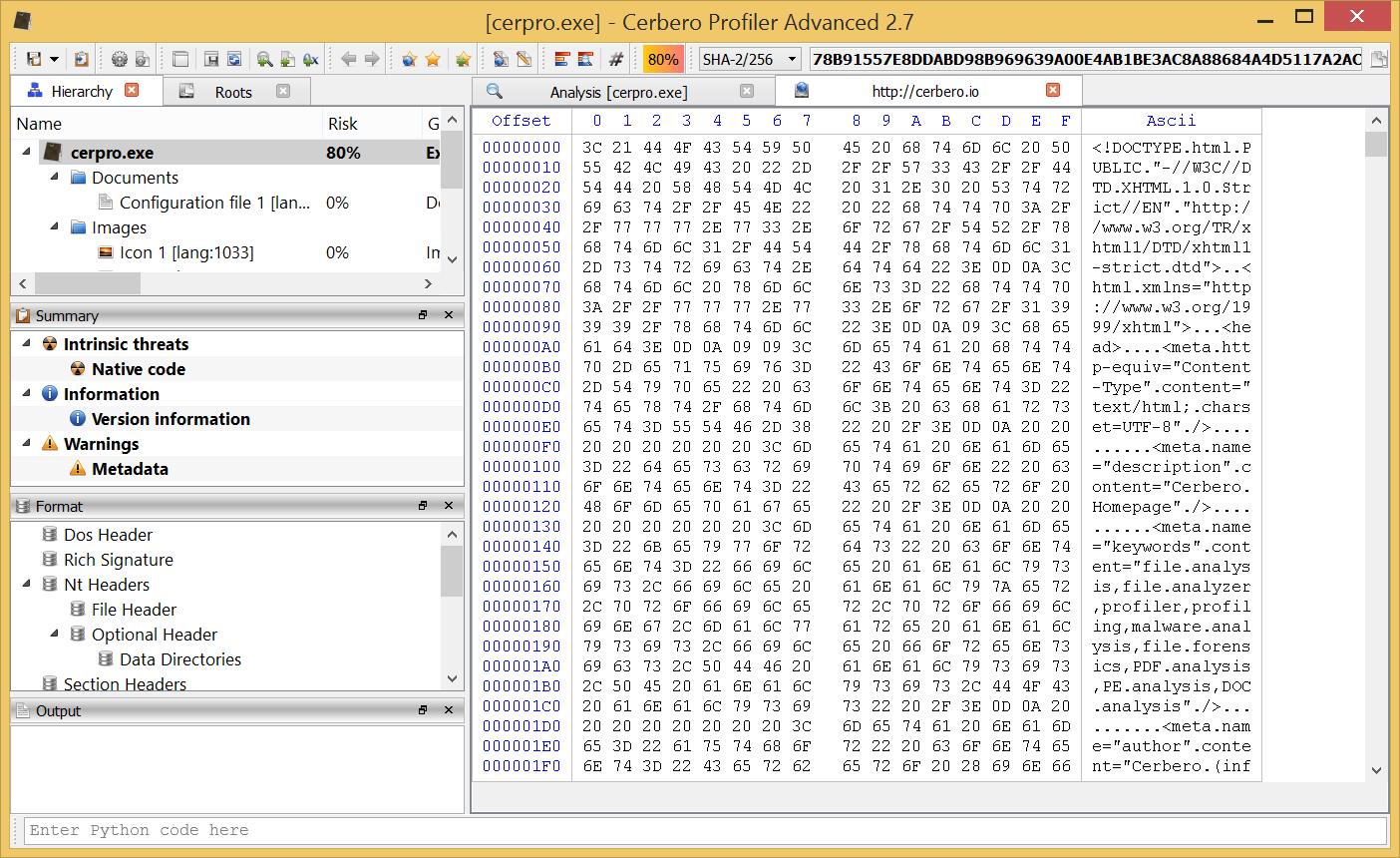
Version 3.1 is out with many improvements! The main news is the support in Carbon for ELF files and the improved deployment of the Linux edition.
This is the full list of news:
+ added ELF Carbon loader
+ added edit bytes command to Carbon
+ added write method to Carbon
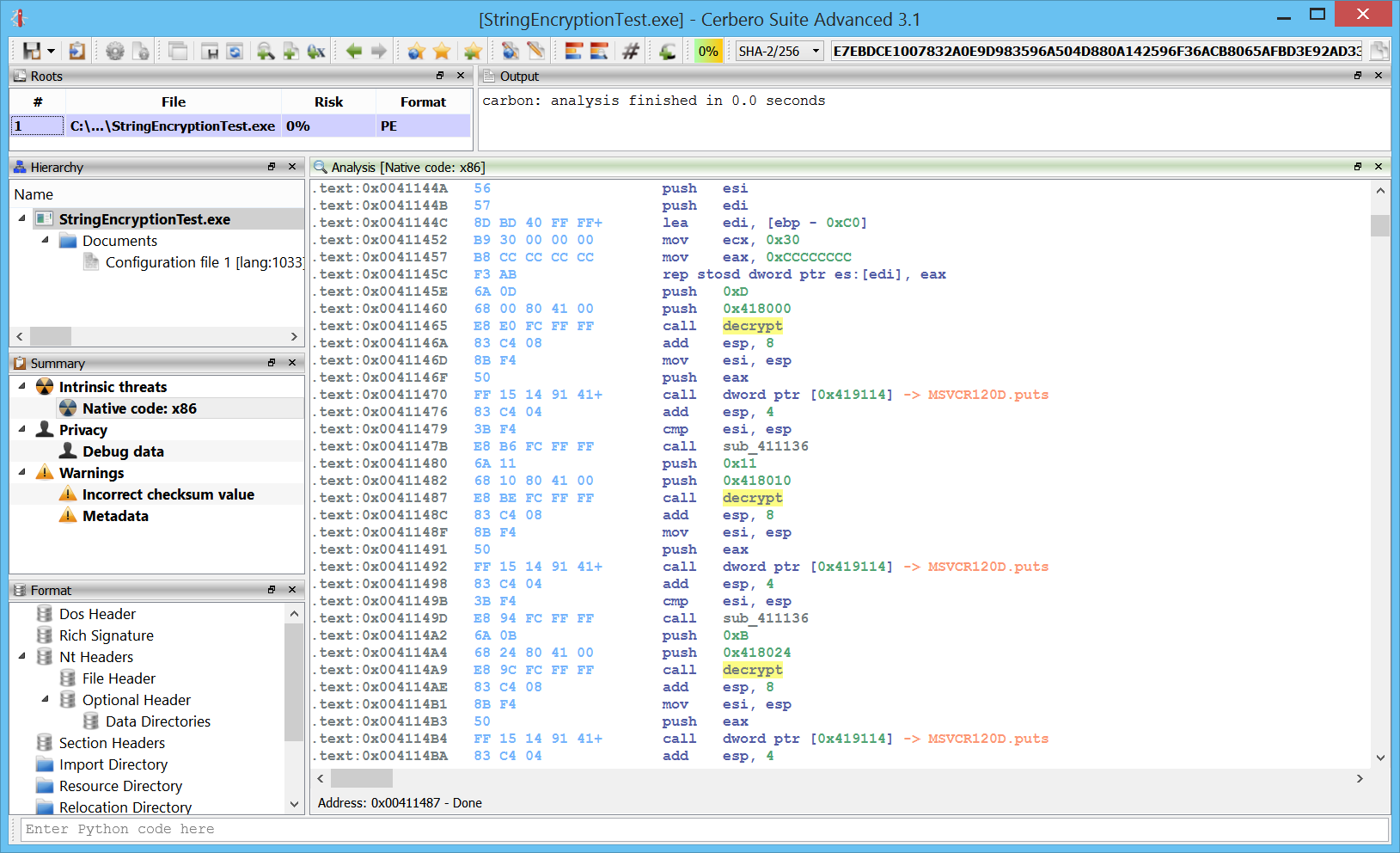
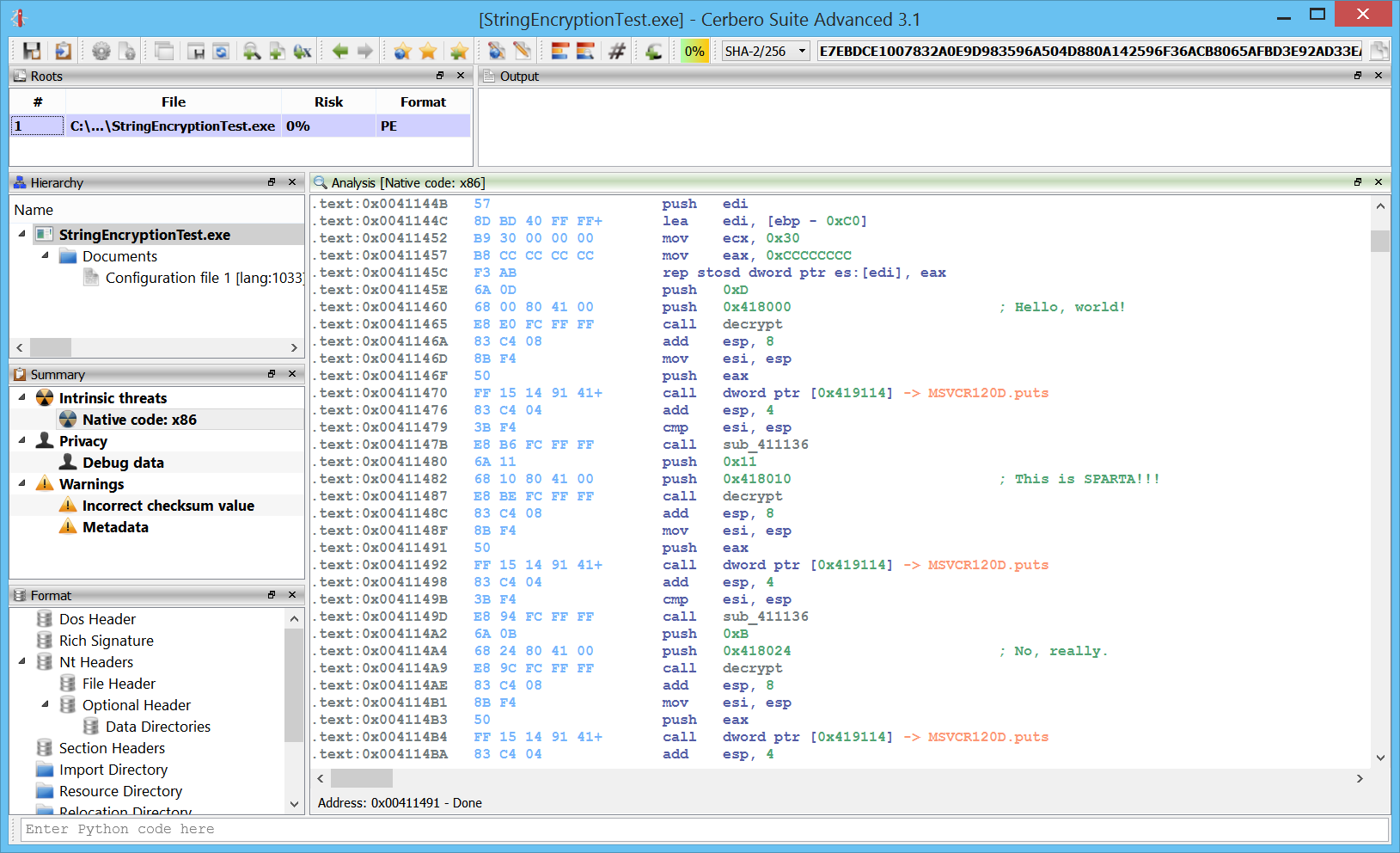
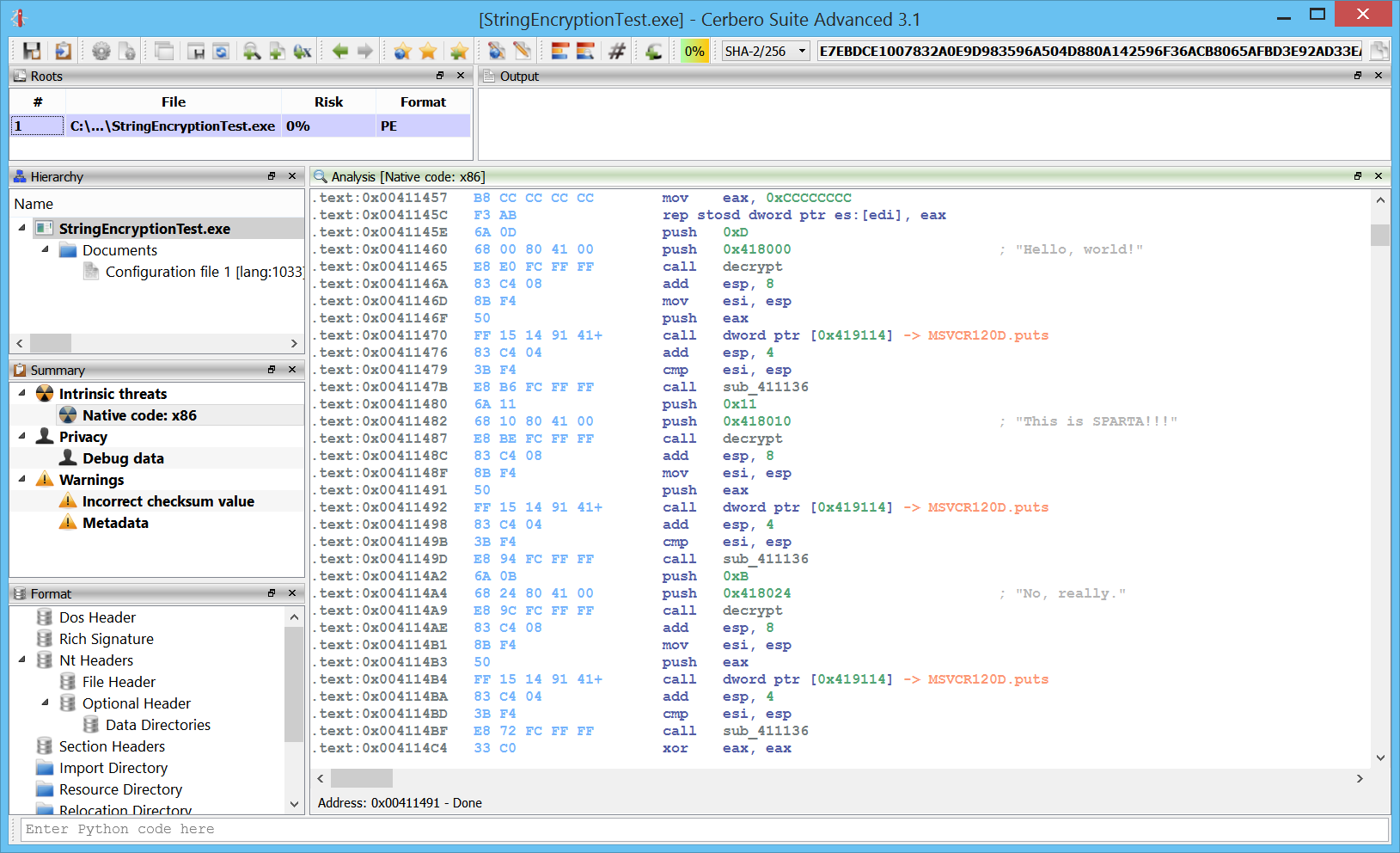
+ added detection of 16-bits wide strings in Carbon
+ added open in hex editor action in Carbon
+ added filters to Carbon
+ added Carbon Monokai theme
– added single view mode (Ctrl+Alt+S)
– improved deployment on Linux
+ improved x86/x64 disassembly
– improved hex workspace
– updated capstone to 4.0.1
– fixed misidentified object crash
– fixed some bugs
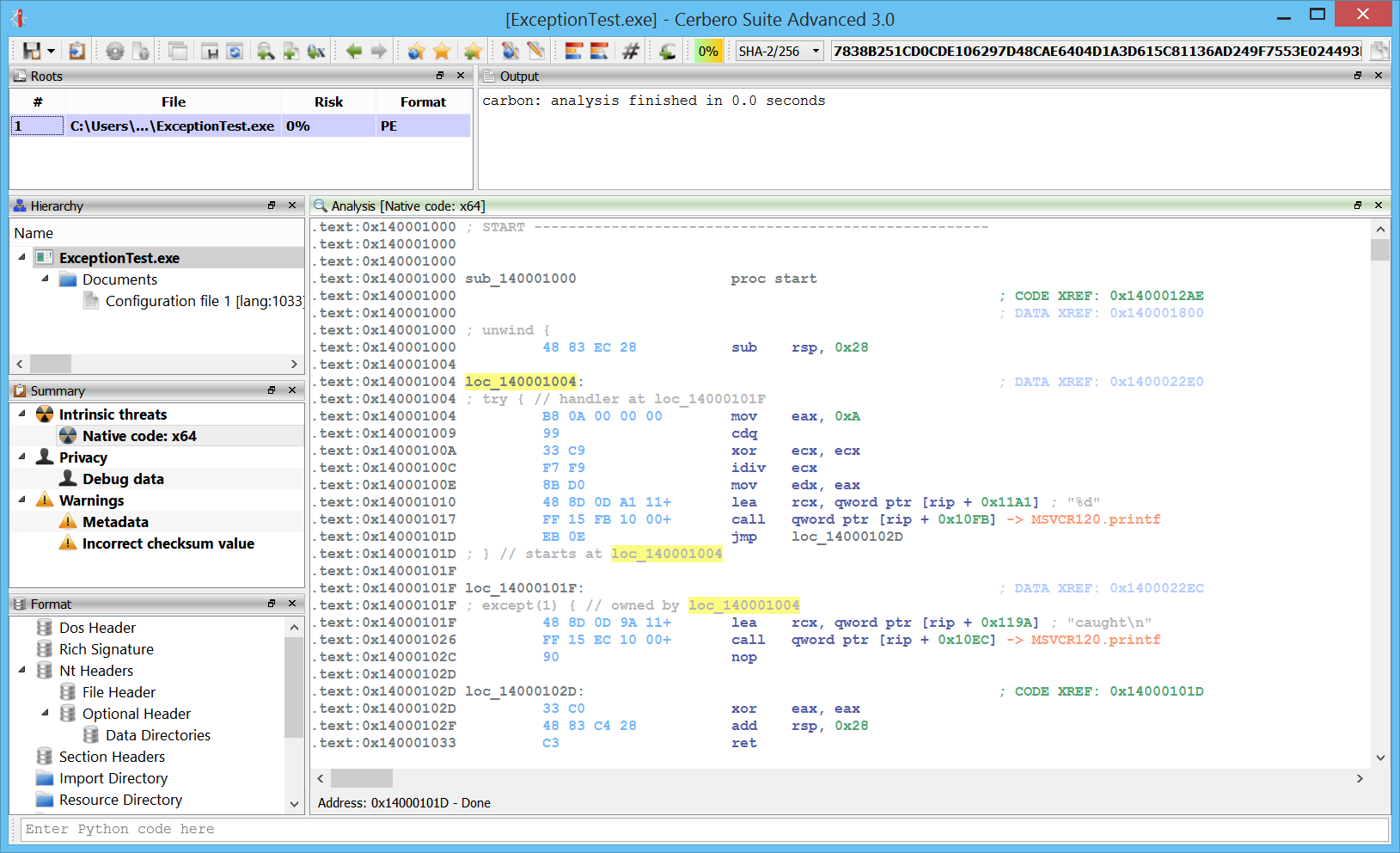
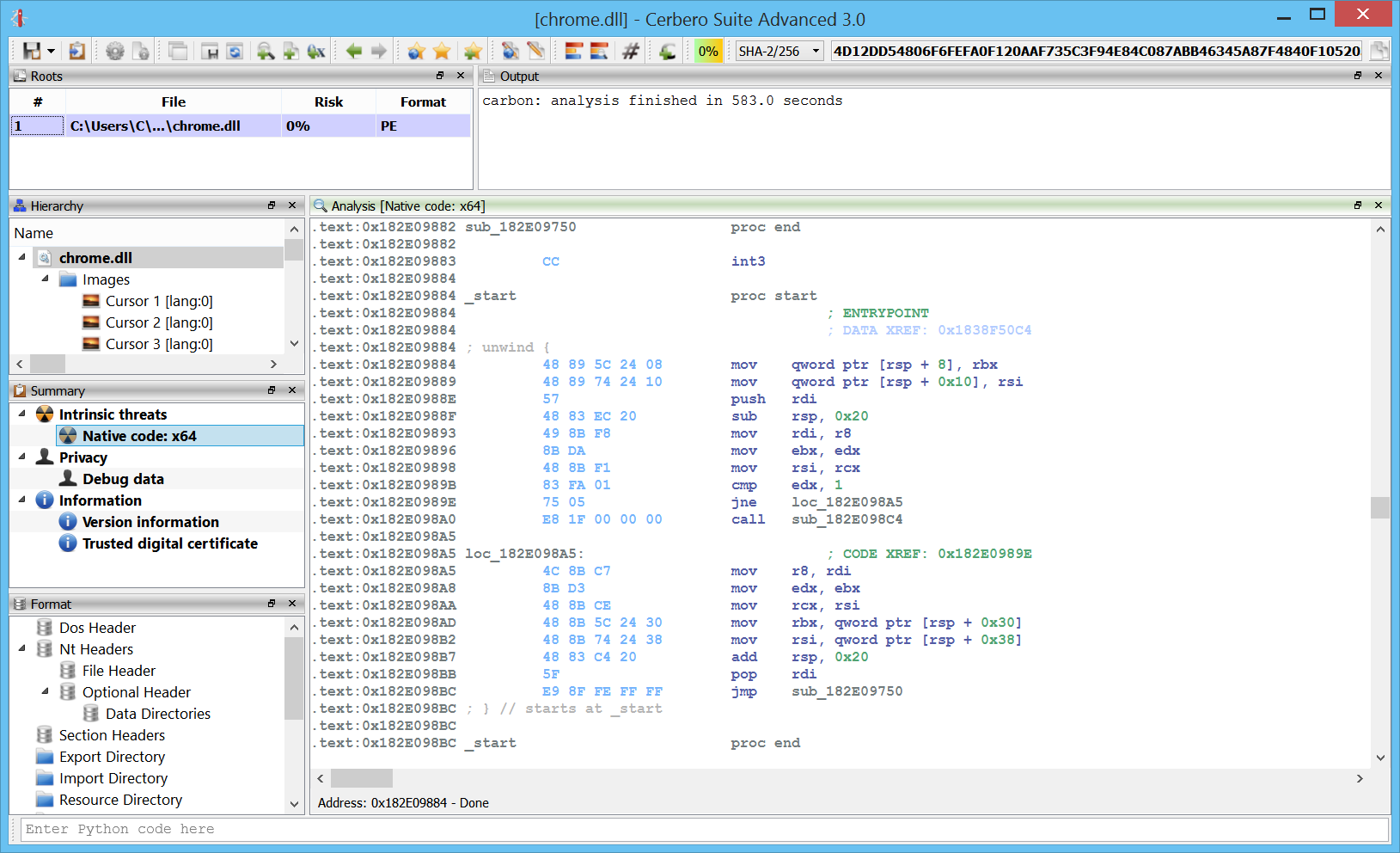
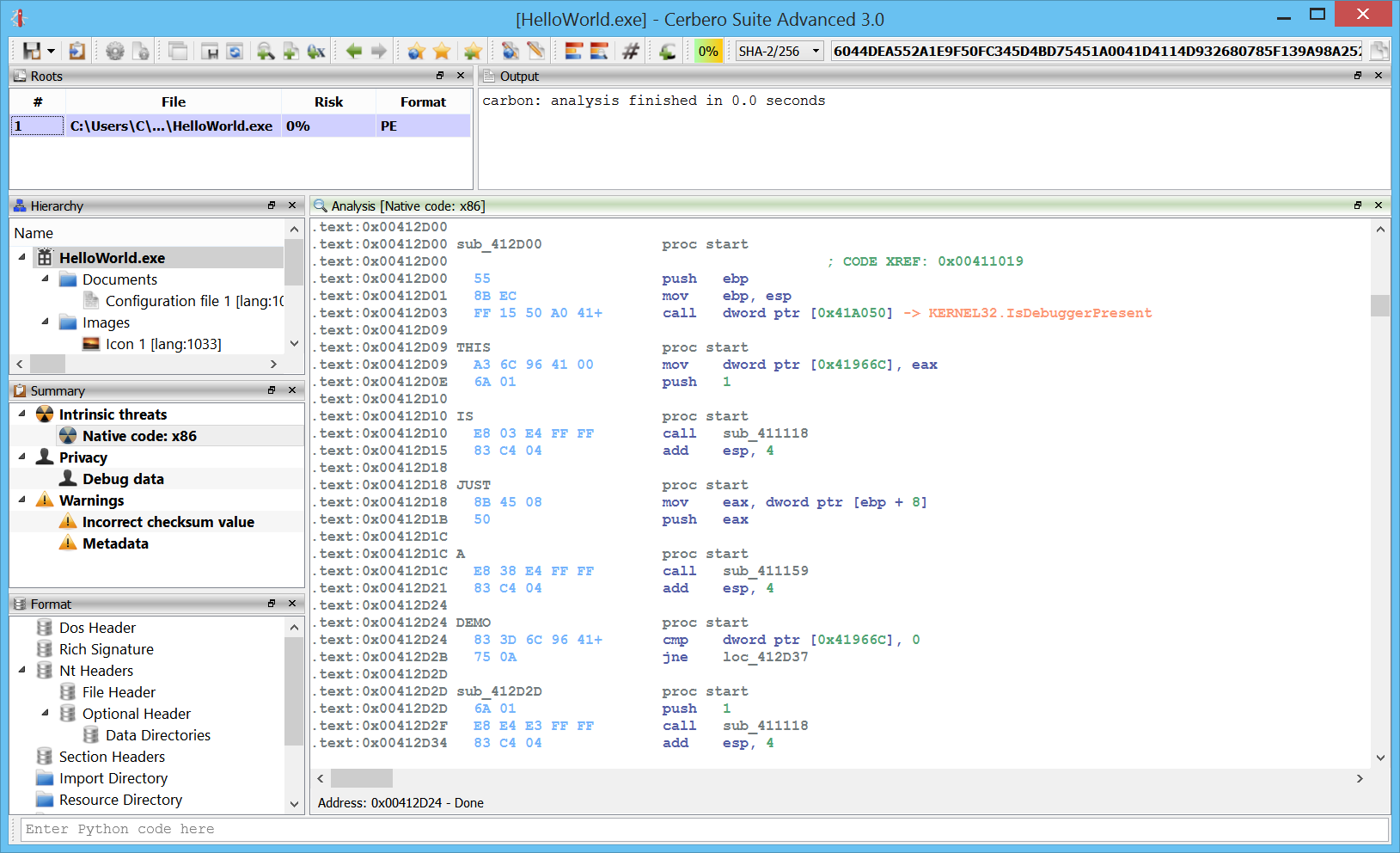
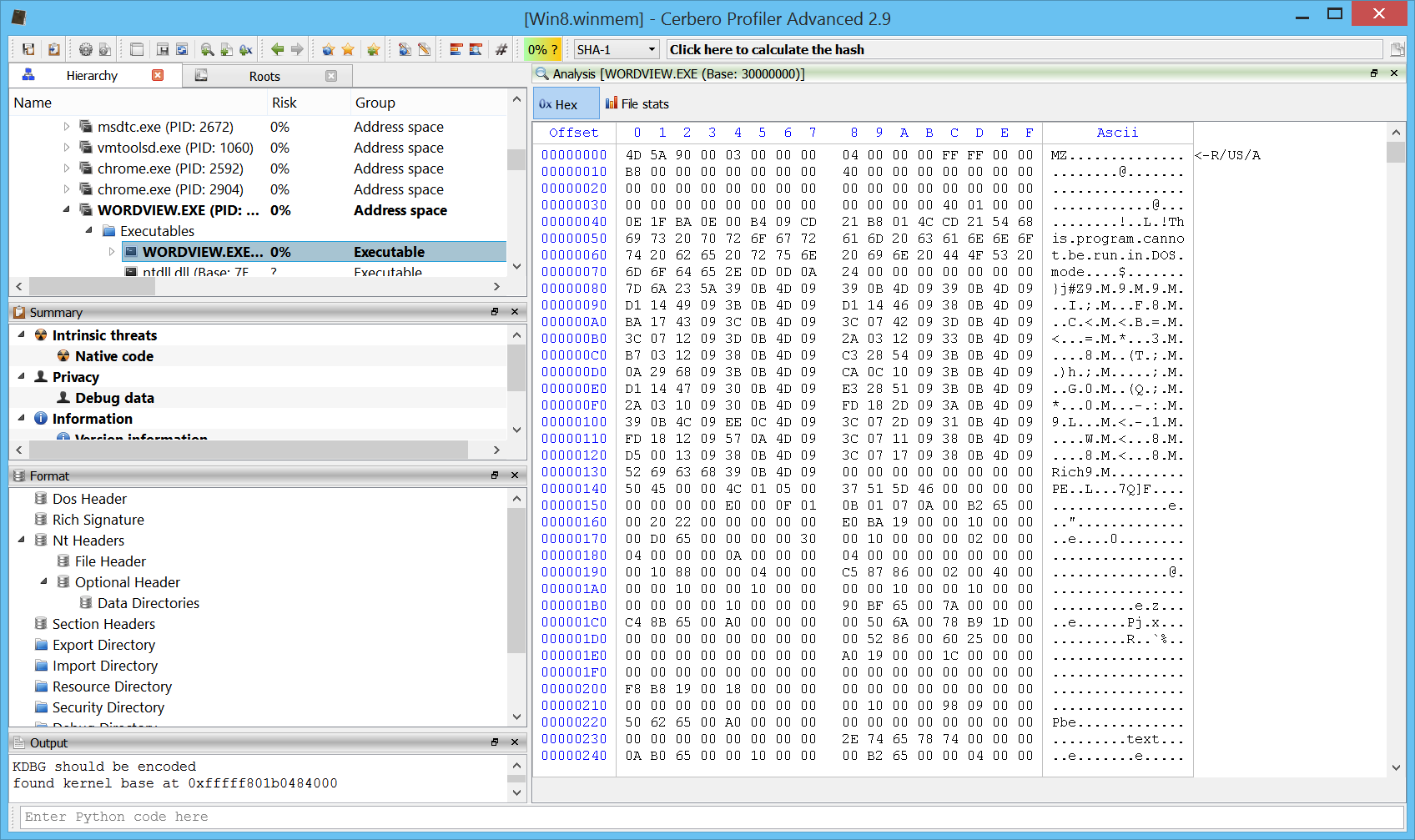
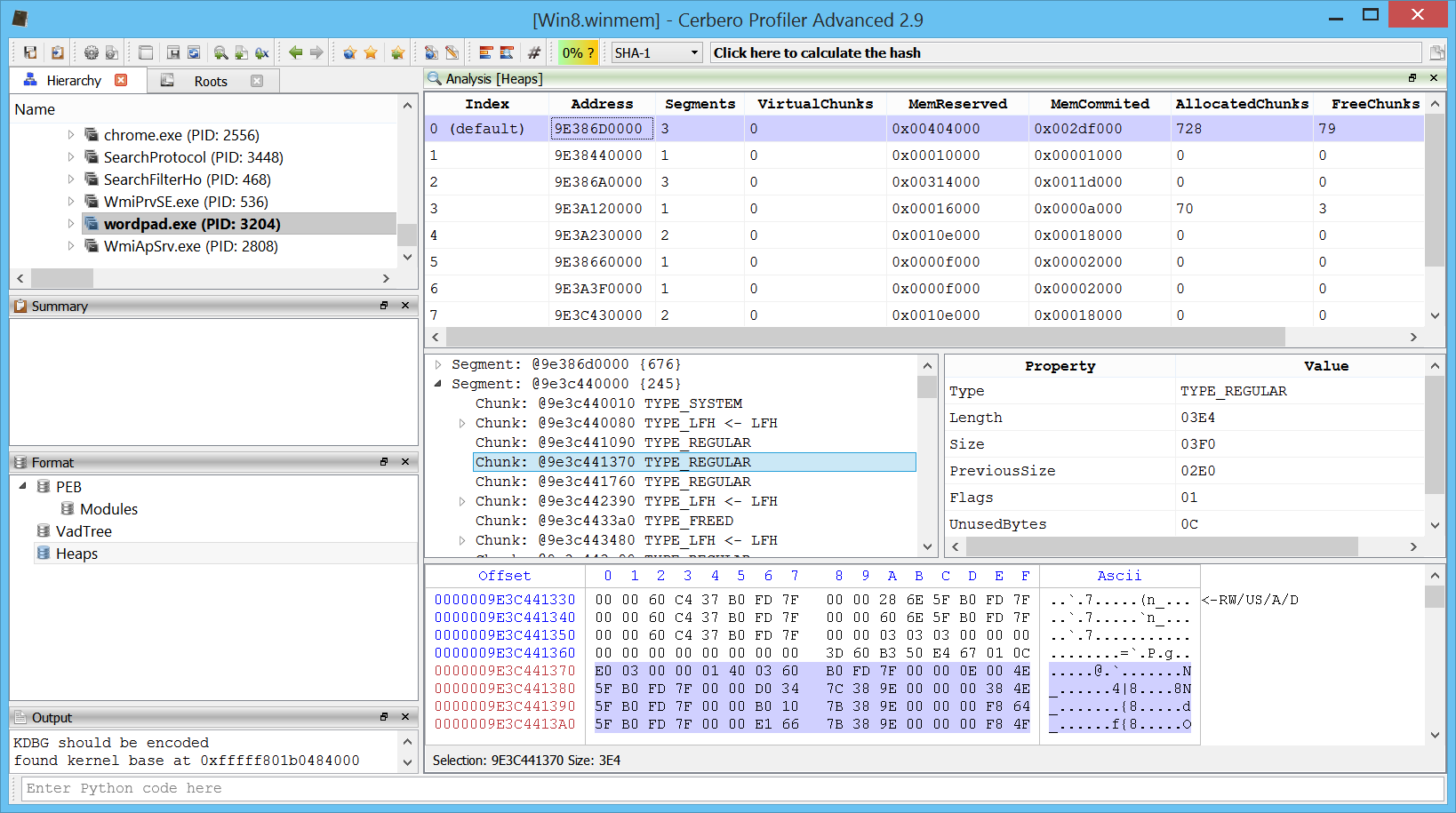
Carbon: ELF loader
Here we can see an ELF x64 file in Carbon. As we can see we have an entry point with a call to __libc_start_main.
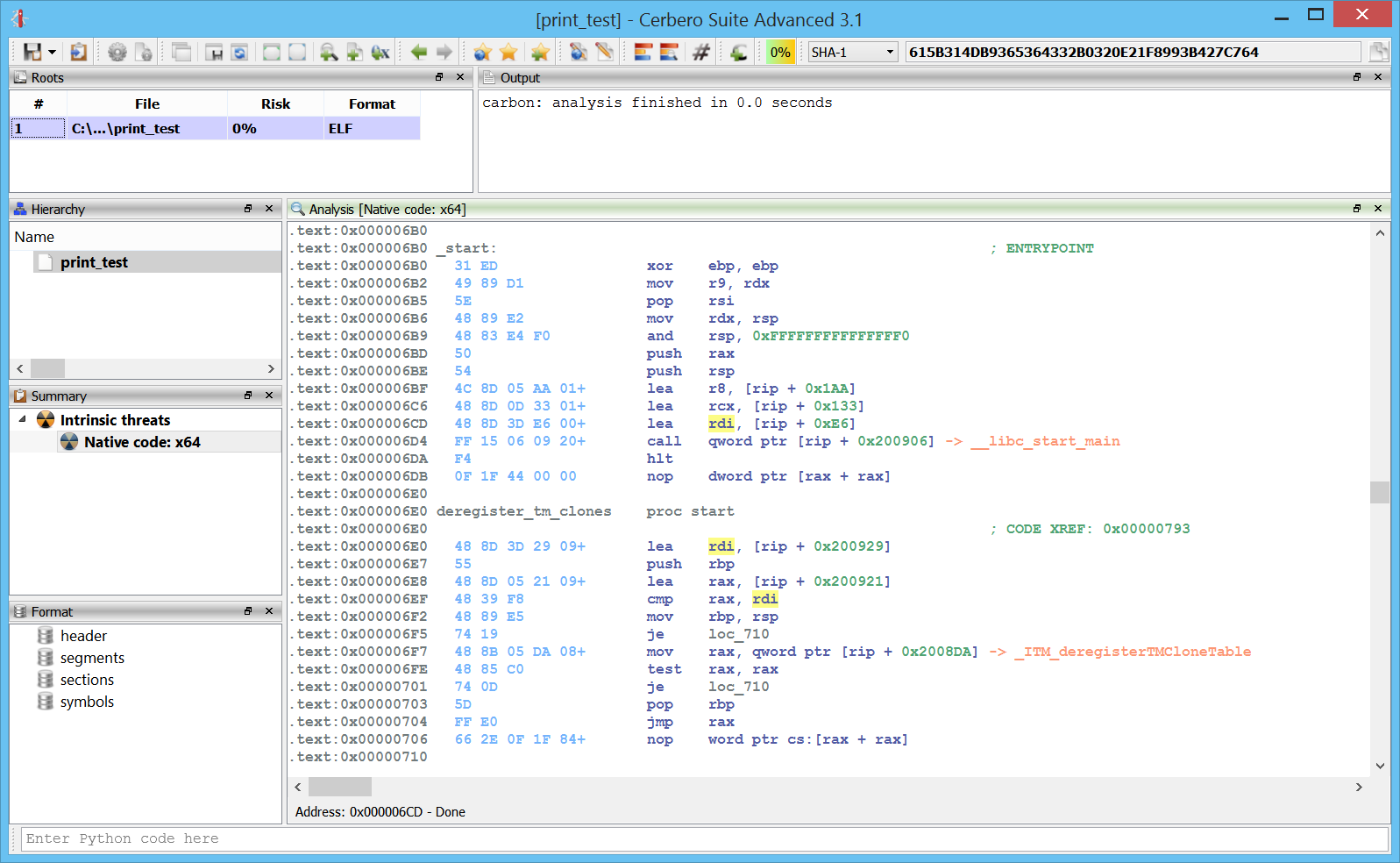
We can follow the first argument which will bring us to the main function.
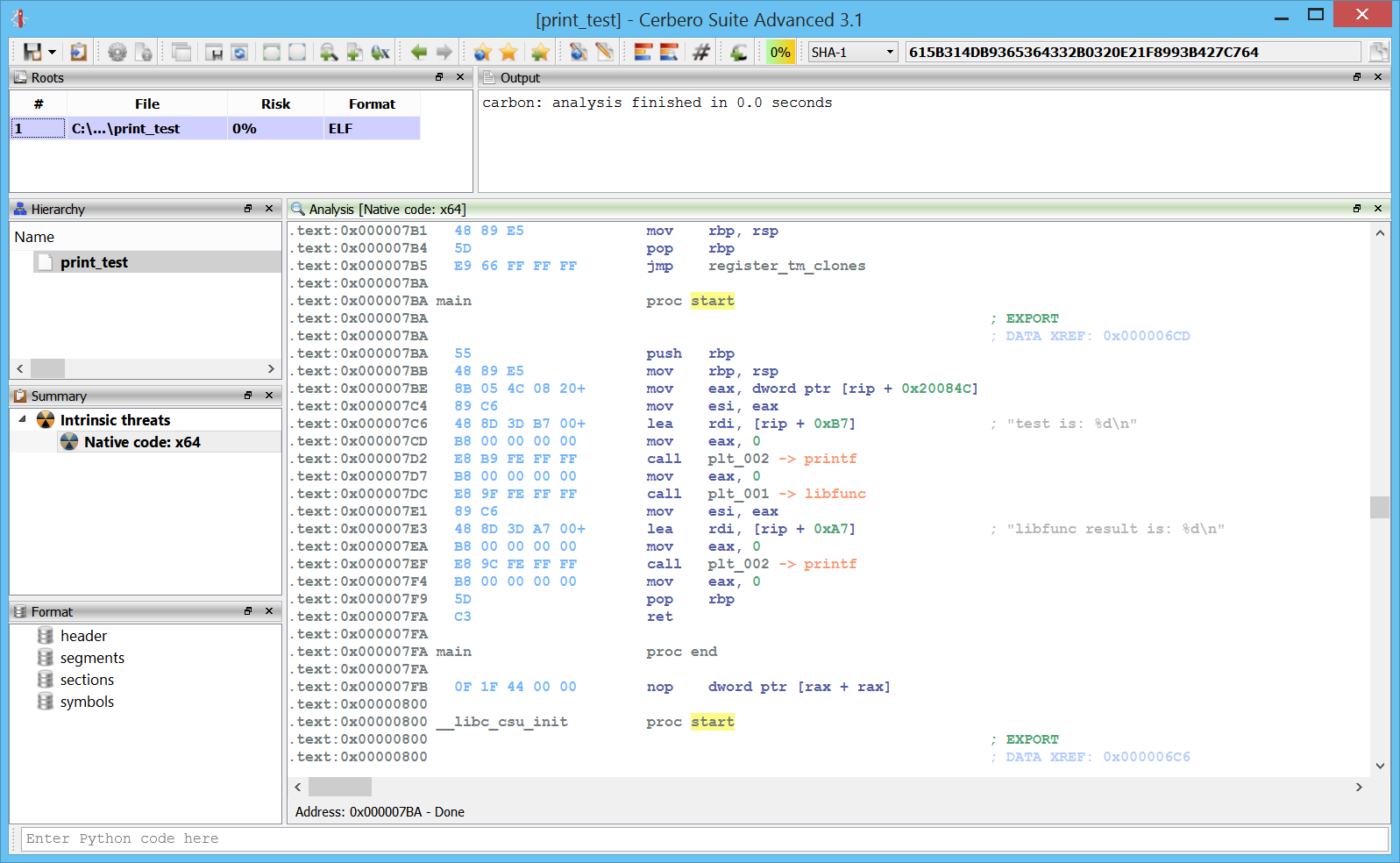
.text:0x000007BA main proc start
.text:0x000007BA ; EXPORT
.text:0x000007BA ; DATA XREF: 0x000006CD
.text:0x000007BA 55 push rbp
.text:0x000007BB 48 89 E5 mov rbp, rsp
.text:0x000007BE 8B 05 4C 08 20+ mov eax, dword ptr [rip + 0x20084C]
.text:0x000007C4 89 C6 mov esi, eax
.text:0x000007C6 48 8D 3D B7 00+ lea rdi, [rip + 0xB7] ; "test is: %d\n"
.text:0x000007CD B8 00 00 00 00 mov eax, 0
.text:0x000007D2 E8 B9 FE FF FF call plt_002 -> printf
.text:0x000007D7 B8 00 00 00 00 mov eax, 0
.text:0x000007DC E8 9F FE FF FF call plt_001 -> libfunc
.text:0x000007E1 89 C6 mov esi, eax
.text:0x000007E3 48 8D 3D A7 00+ lea rdi, [rip + 0xA7] ; "libfunc result is: %d\n"
.text:0x000007EA B8 00 00 00 00 mov eax, 0
.text:0x000007EF E8 9C FE FF FF call plt_002 -> printf
.text:0x000007F4 B8 00 00 00 00 mov eax, 0
.text:0x000007F9 5D pop rbp
.text:0x000007FA C3 ret
.text:0x000007FA
.text:0x000007FA main proc end Carbon: detection of 16-bits wide strings
Simple 16-bit wide strings are now automatically detected in Carbon.
Carbon: open in hex editor action
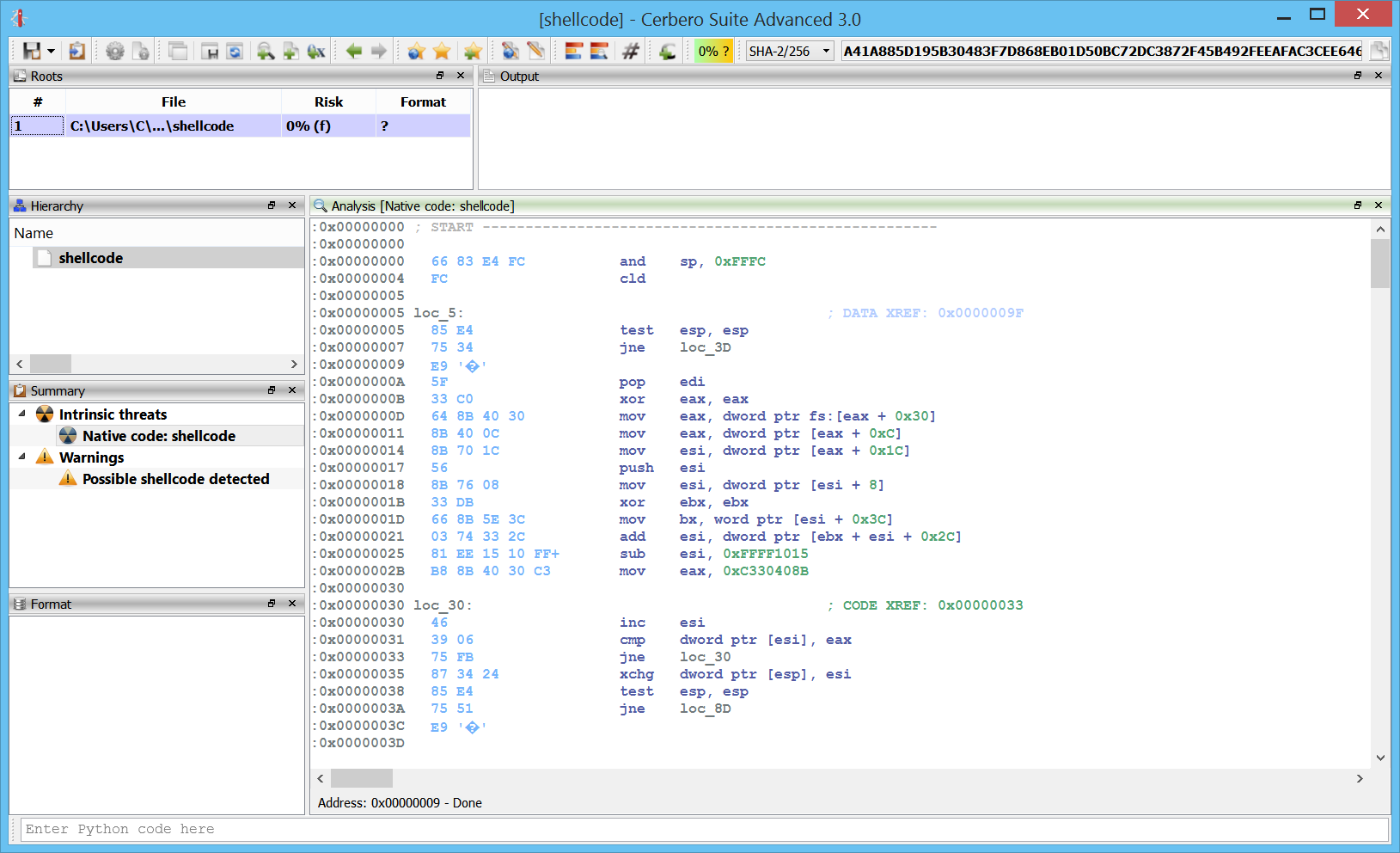
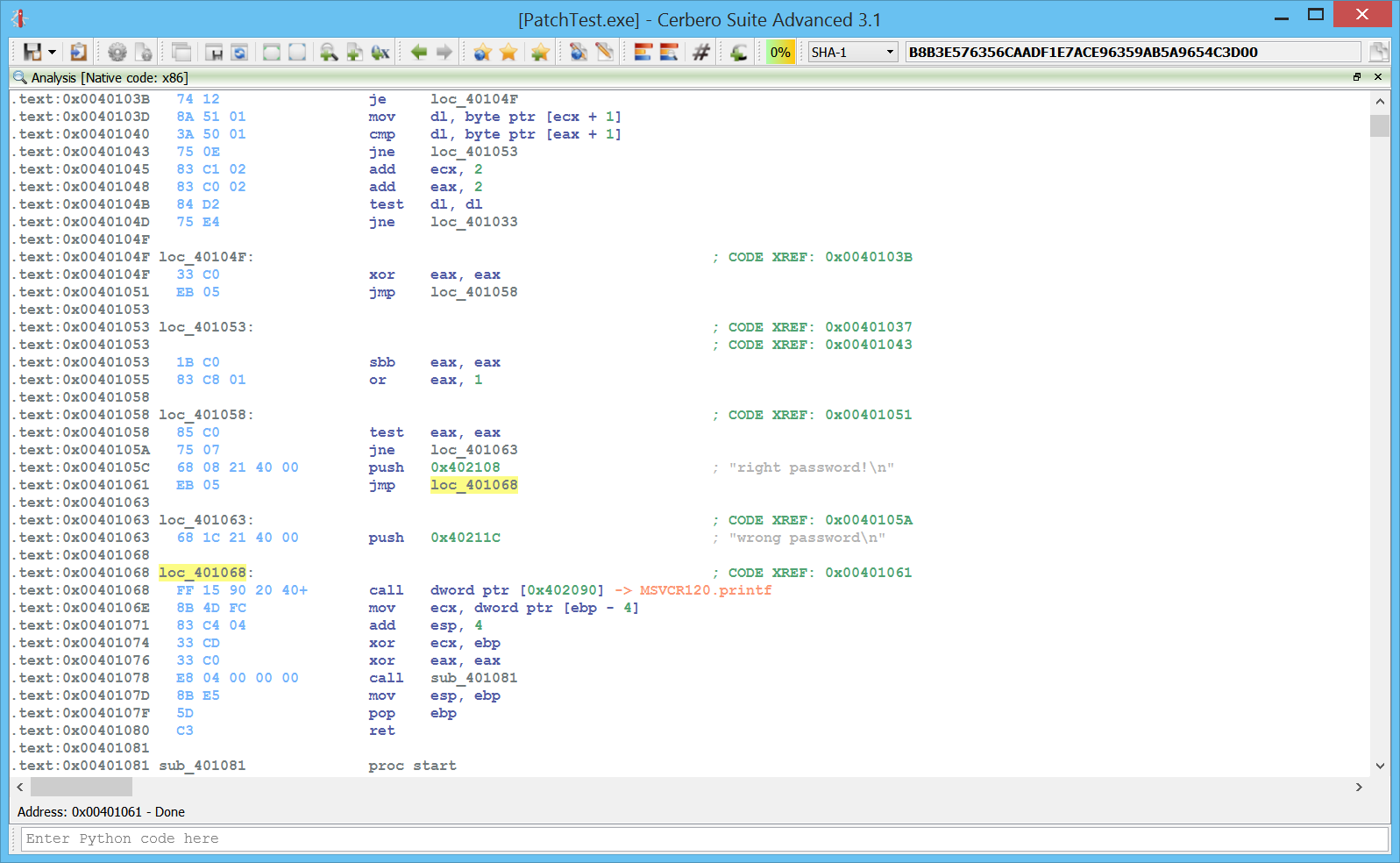
It is now possible to open the hex editor from the disassembly. To demonstrate this feature I crafted a small executable which asks for a password and prints an error message if the password is wrong.
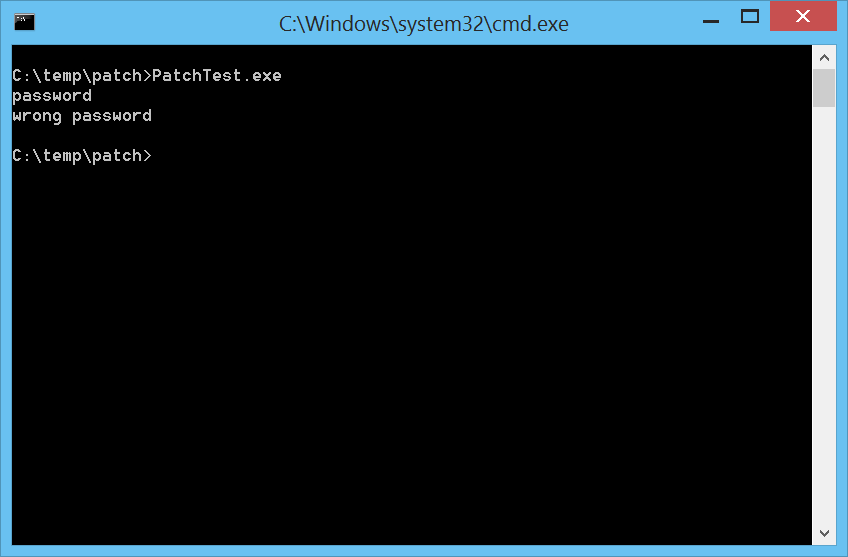
We can easily find the “wrong password” string in Carbon by pressing Ctrl+5.
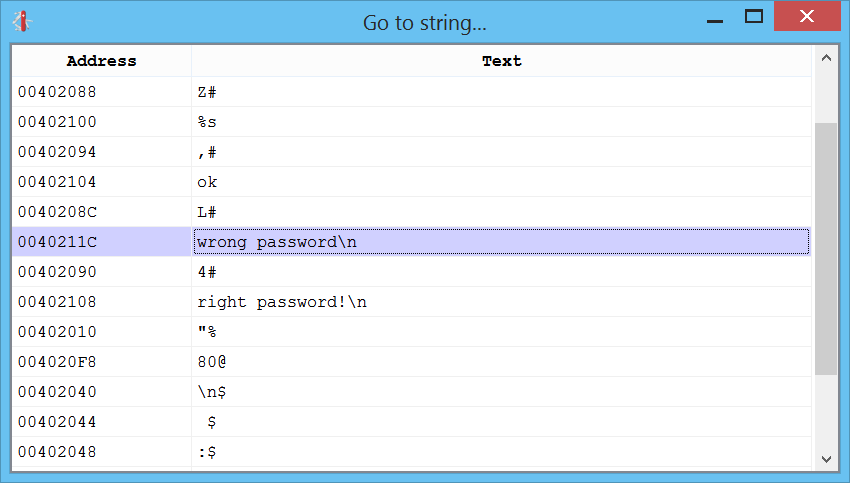
Right before the referenced string, there’s a scanf followed by a strcmp.
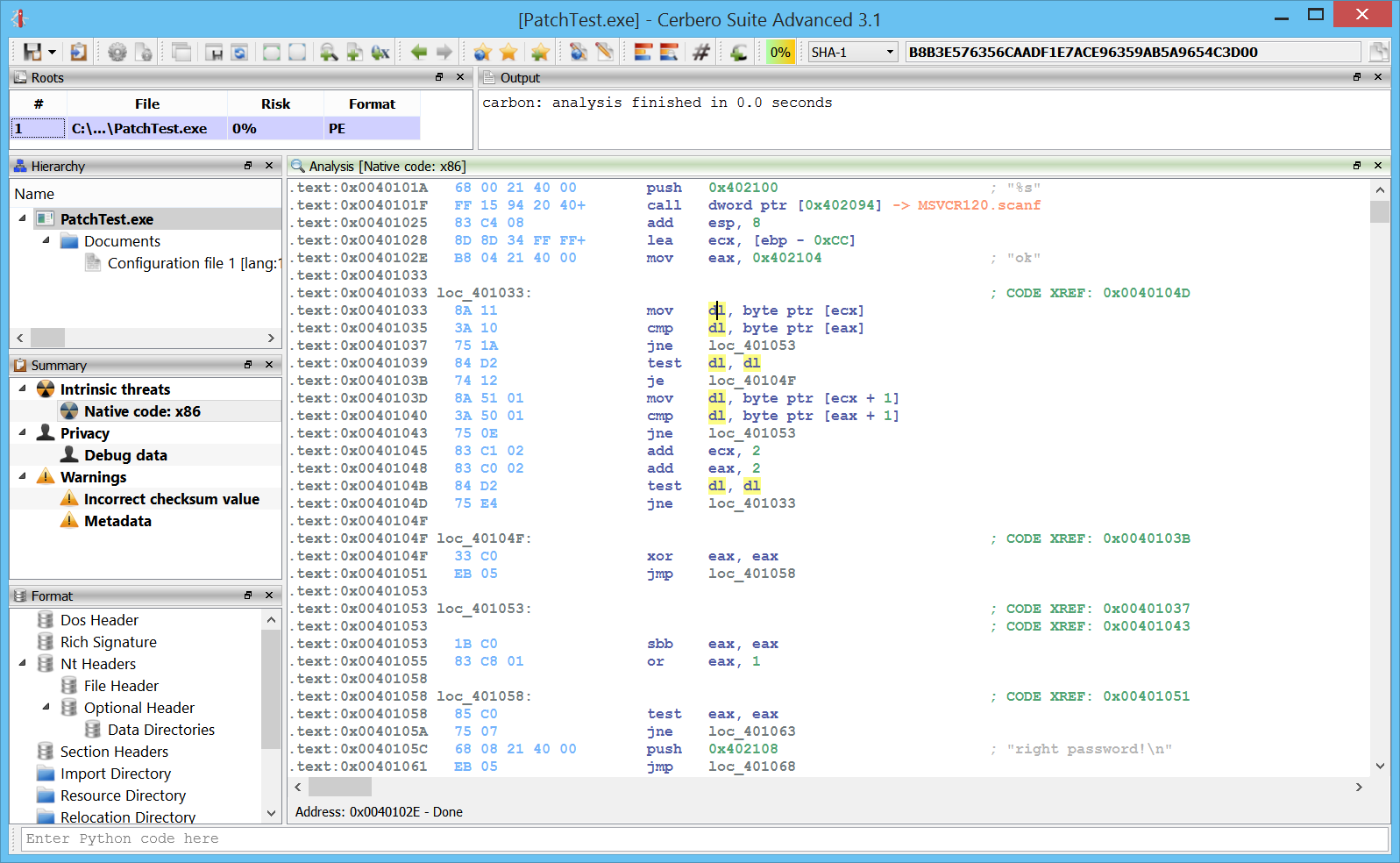
We go to the jne which evaluates the result of the strcmp and we open the hex editor from the contextual menu. It will ask us to open a file (it must be a copy of the file we’re analysing).
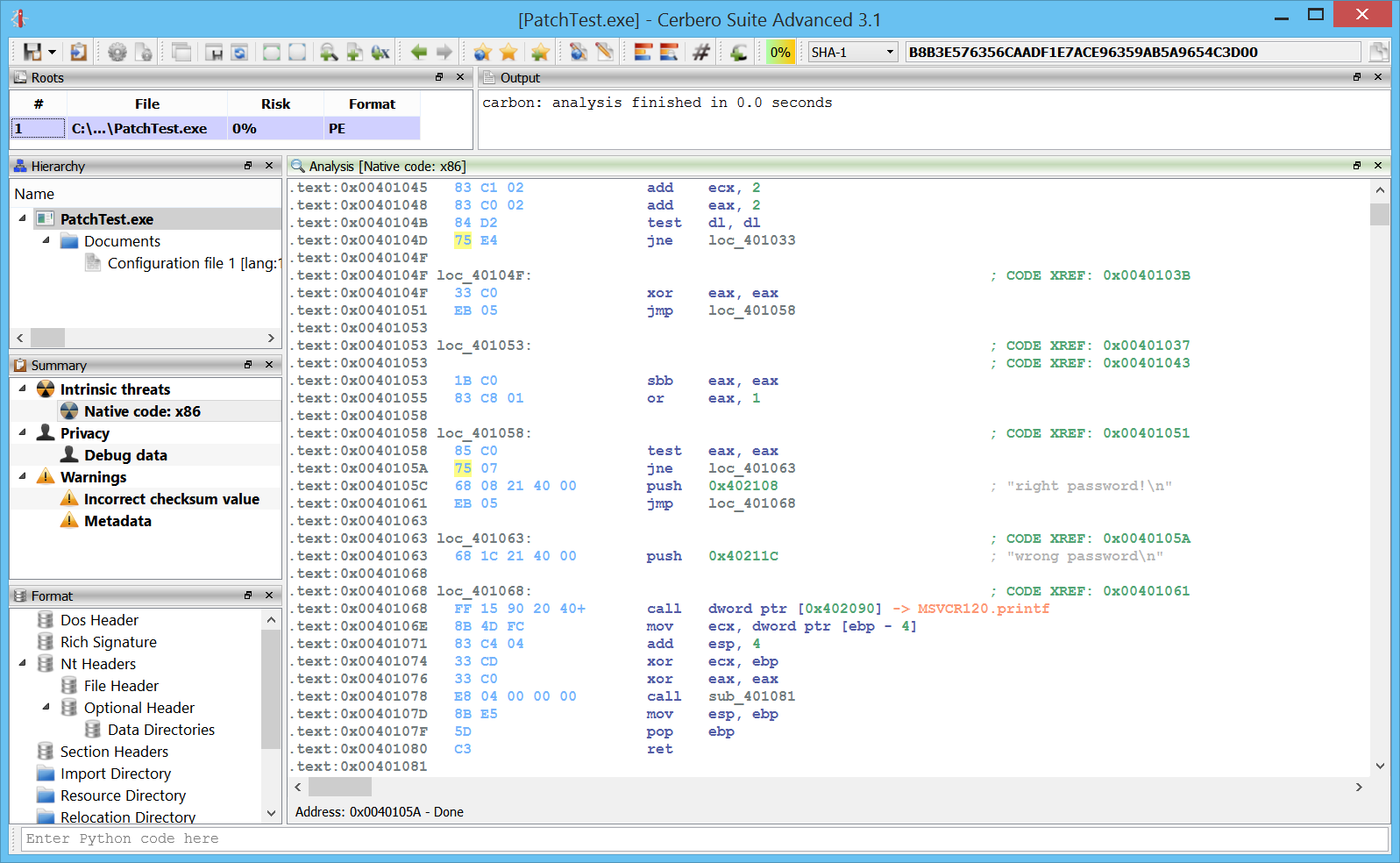
We can just nop the two bytes representing the jne and then we save the file.
Whatever password we insert now, it will be accepted.

Carbon: filters
While filters are already accessible from hex views, it is now possible to access them from Carbon as well.
Let’s take the same sample analyzed in the previous blog post with xored strings. We select on of those xored strings and we open the filters from the contextual menu or by pressing Ctrl+T.
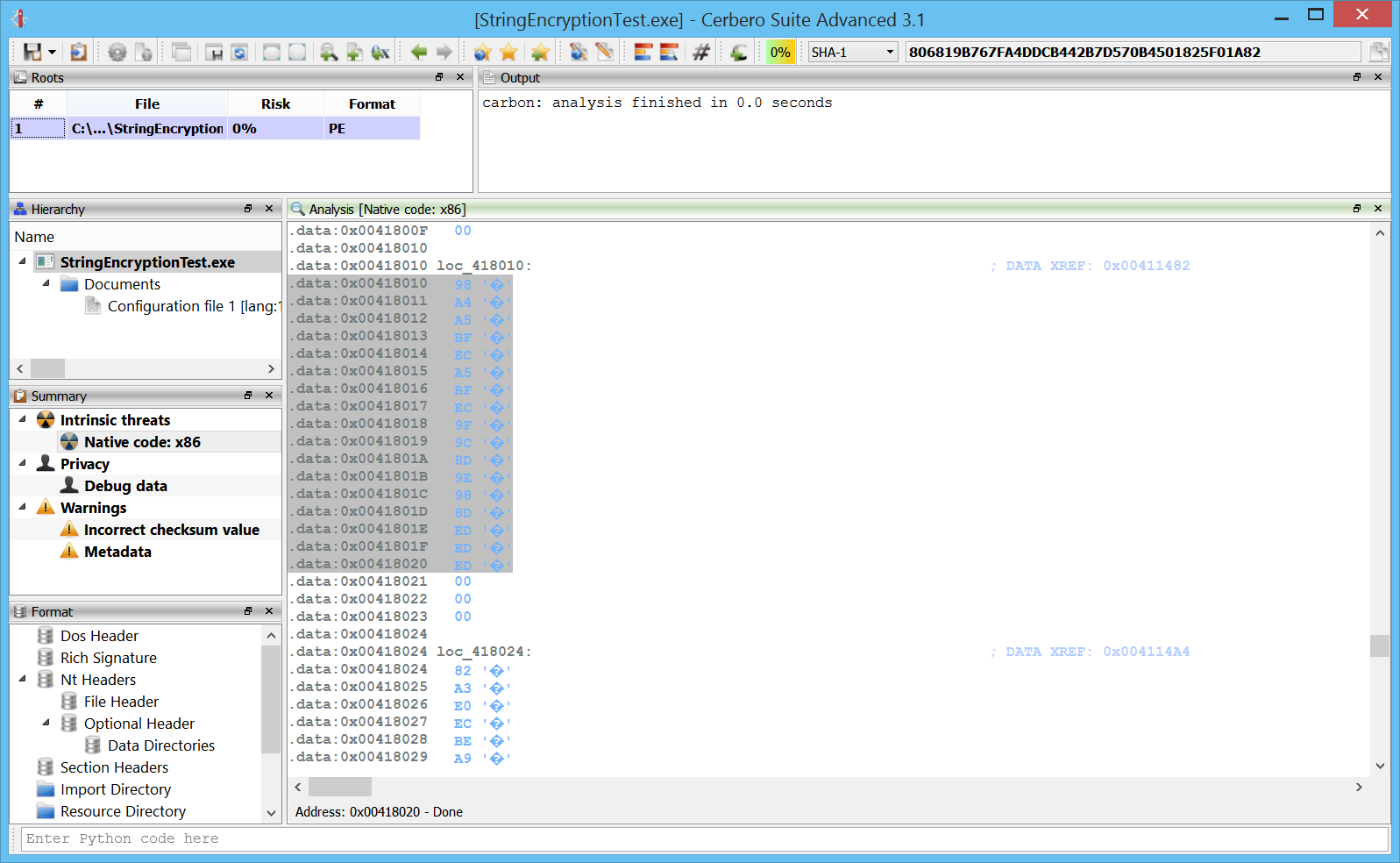
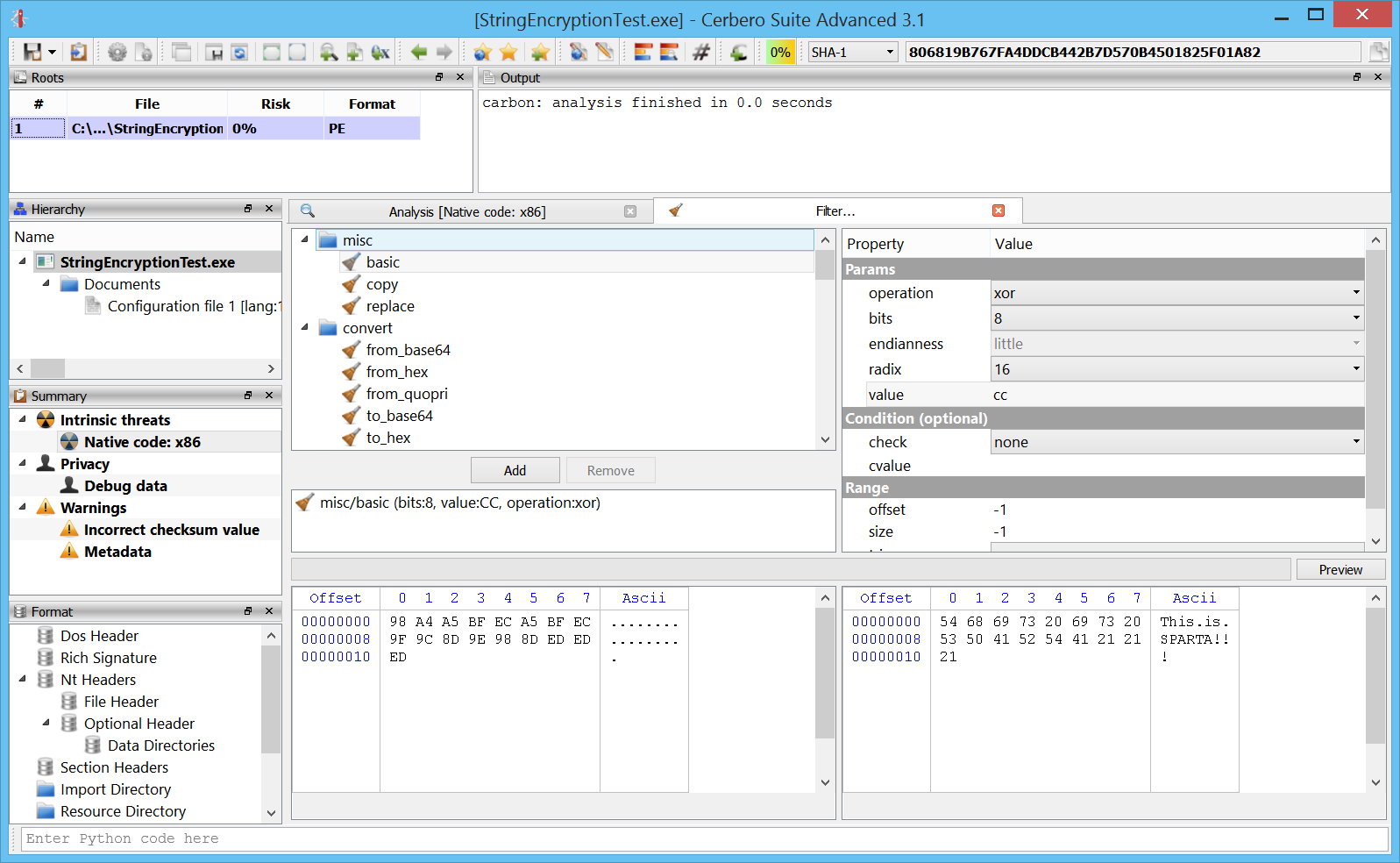
We can now test out a filter on the selected bytes. In this case we simply use a xor to see the string in plain.
Carbon: Monokai theme
The Monokai theme has been added to Carbon.
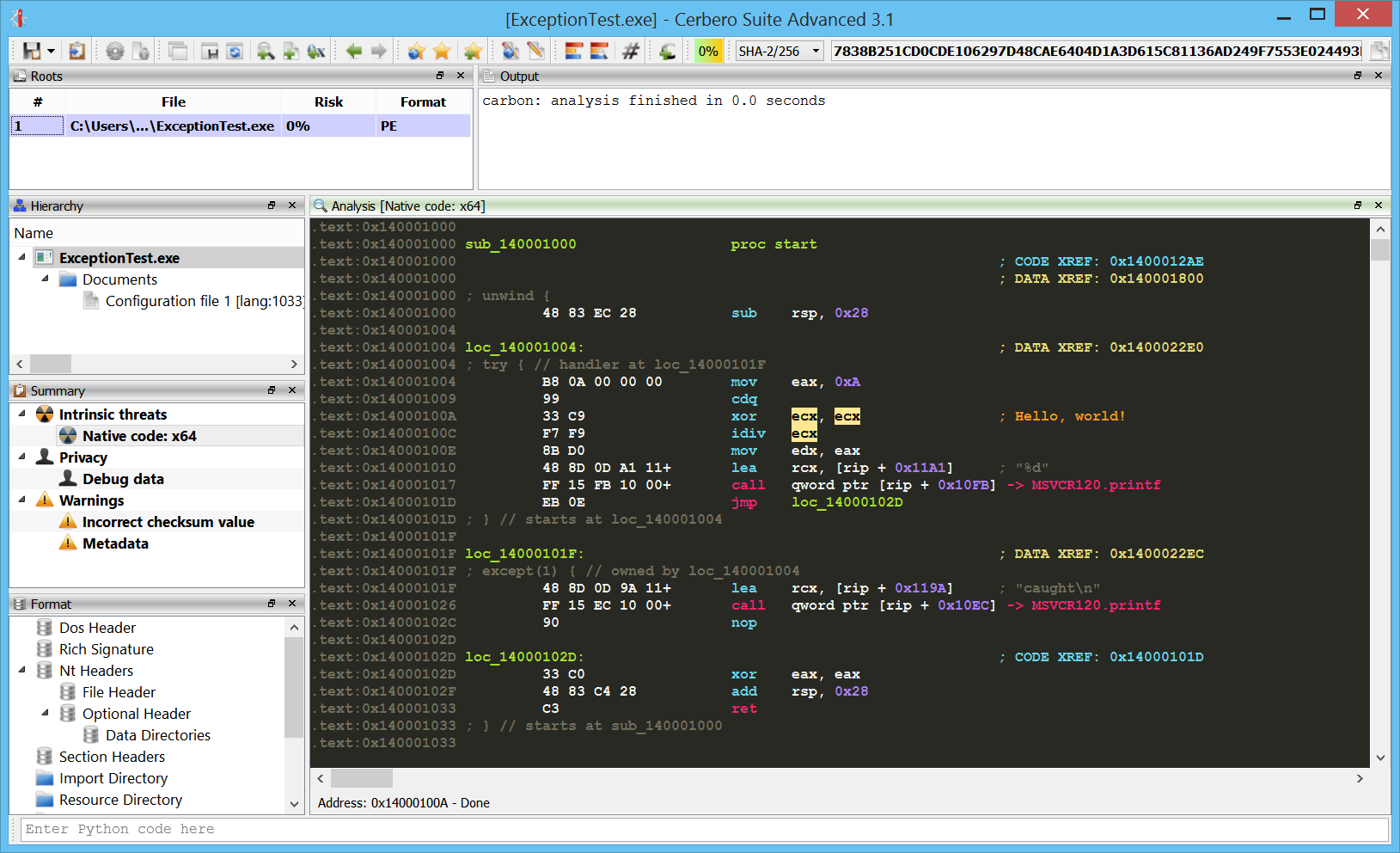
I have been using this theme for some development projects and wondered what it would look like in a disassembly. I don’t know about you, but I like it… 🙂
Single-view mode
While it has always been possible to trigger the full-screen mode via Ctrl+Alt+F, now there’s also single-view mode which can be triggered via Ctrl+Alt+S.
What it does is to hide all other views, leaving only the focused view open. Press the same shortcut to exit the mode and have all other views visible again.
Improved Linux deployment
The Linux edition has been drastically improved by simplifying its deployment. As a result it should now be compatible with many more versions of Linux, without having to adjust dependencies. It also comes with a built-in Python distribution, just like the Windows edition.
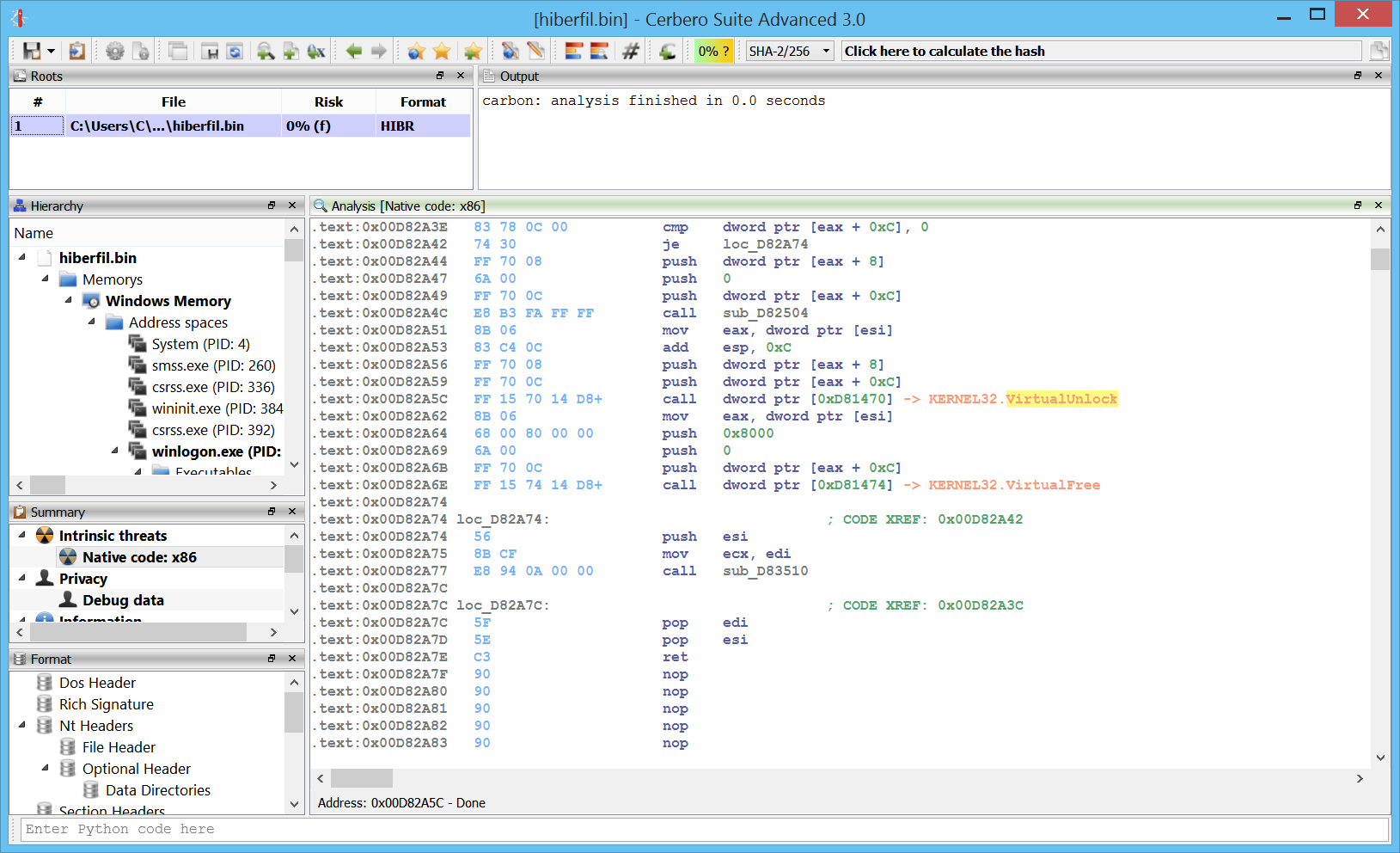
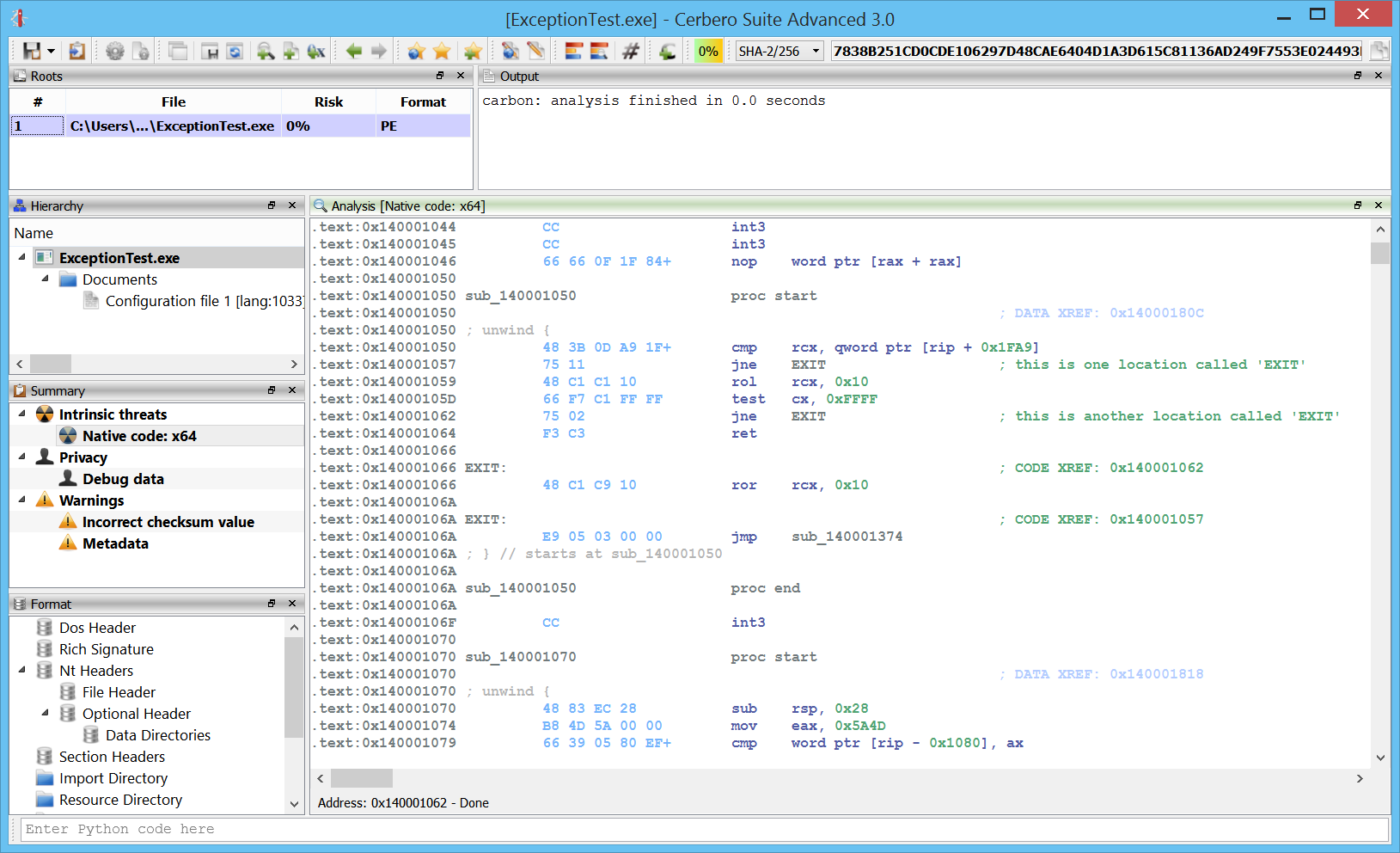
Carbon: improved x86/x64 disassembly
The disassembly in Carbon has been improved so that it now shows import forward calls. Let’s take this simple call to __crtTerminateProcess.
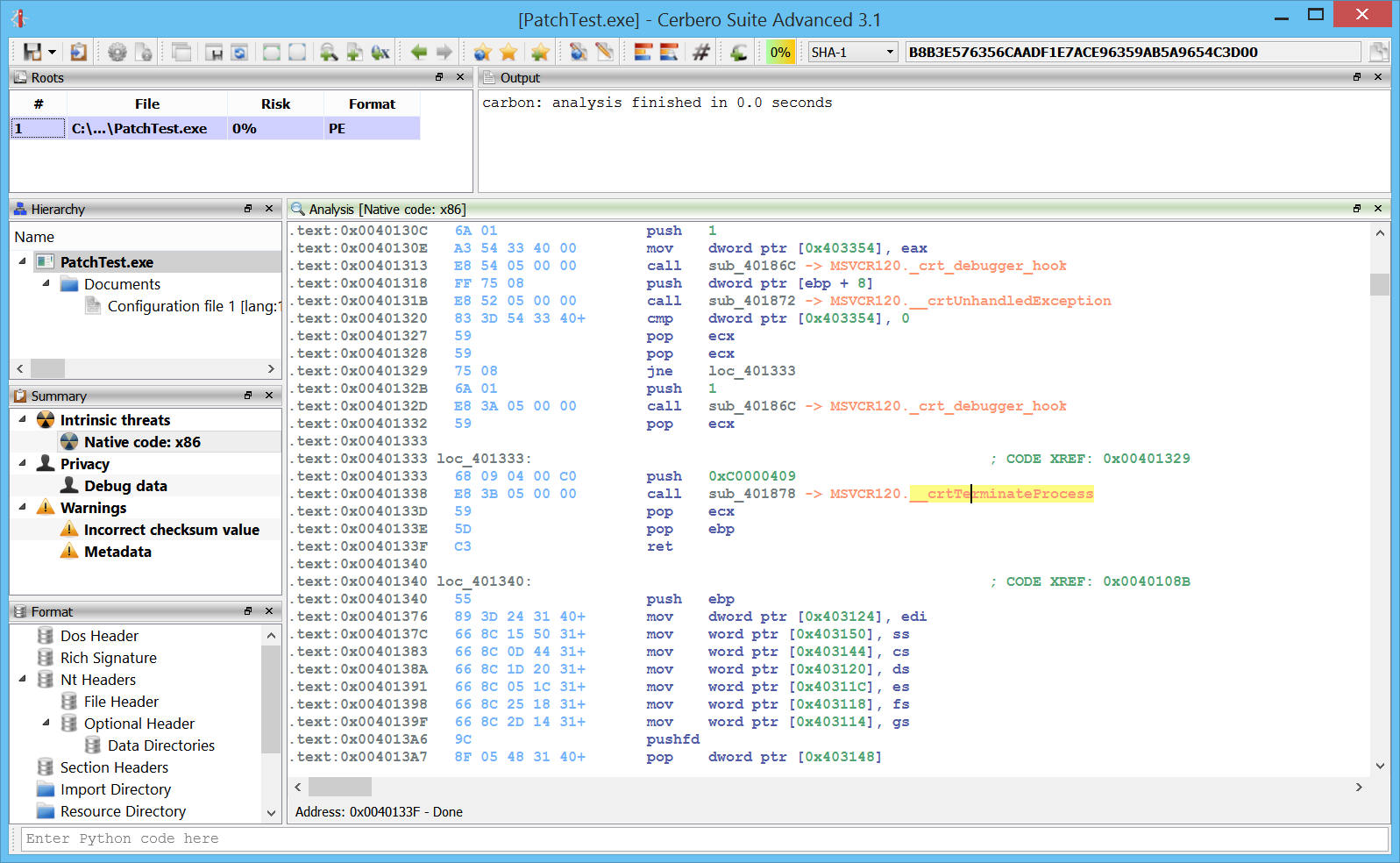
If we follow the call, we’ll see that it just calls a jumps which in turn jumps to the actual API.
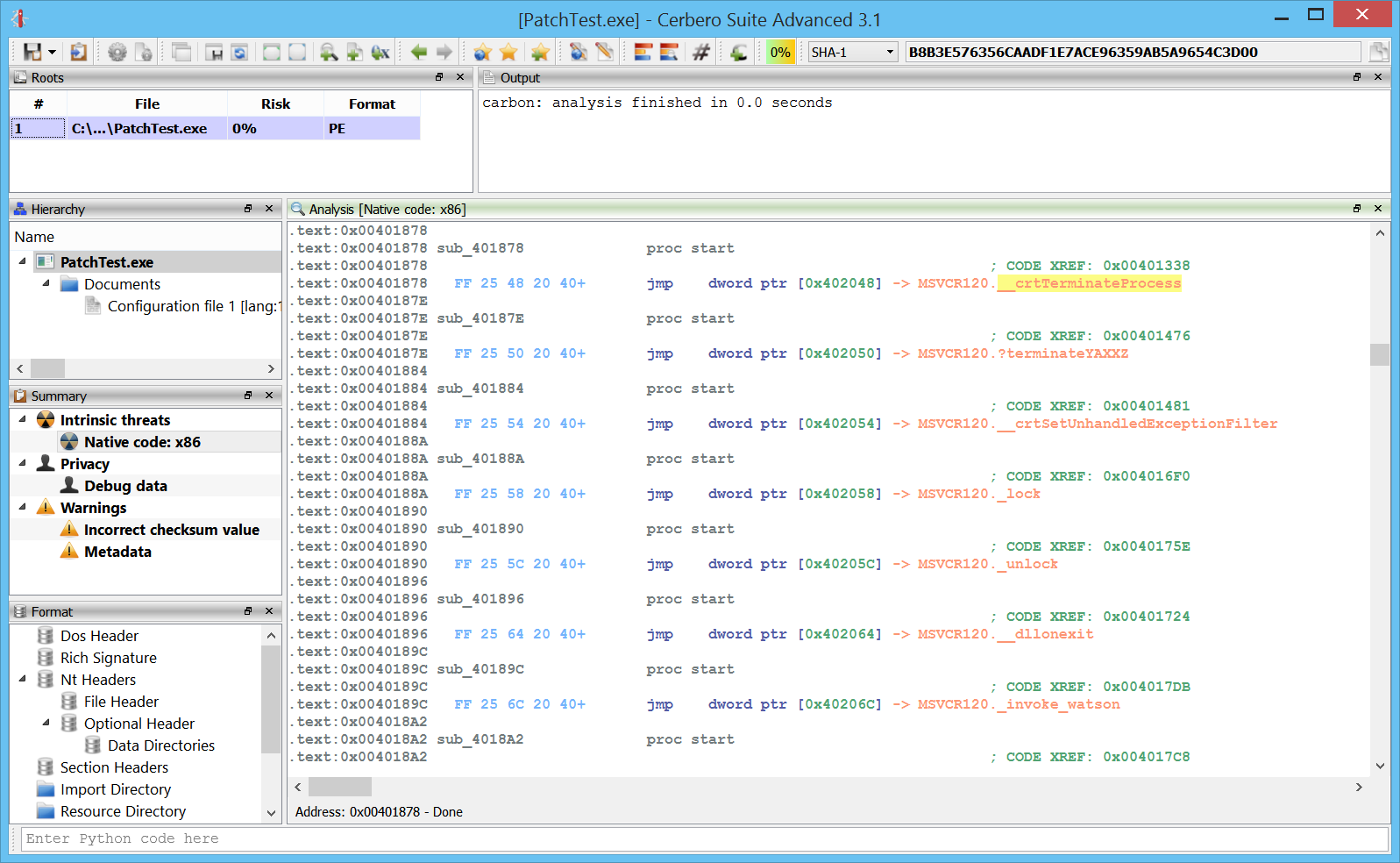
These sort of calls to jumps or jumps to jumps are now automatically resolved to improve the readability of the code.
Improved hex workspace
The hex workspace comes with a number of small improvements, but mainly the initial layout doesn’t show the output view by default.
We hope you enjoy this version as we’re already working on the next one and I can’t wait to show you some of the cool things we’re working on. 🙂
Happy hacking!