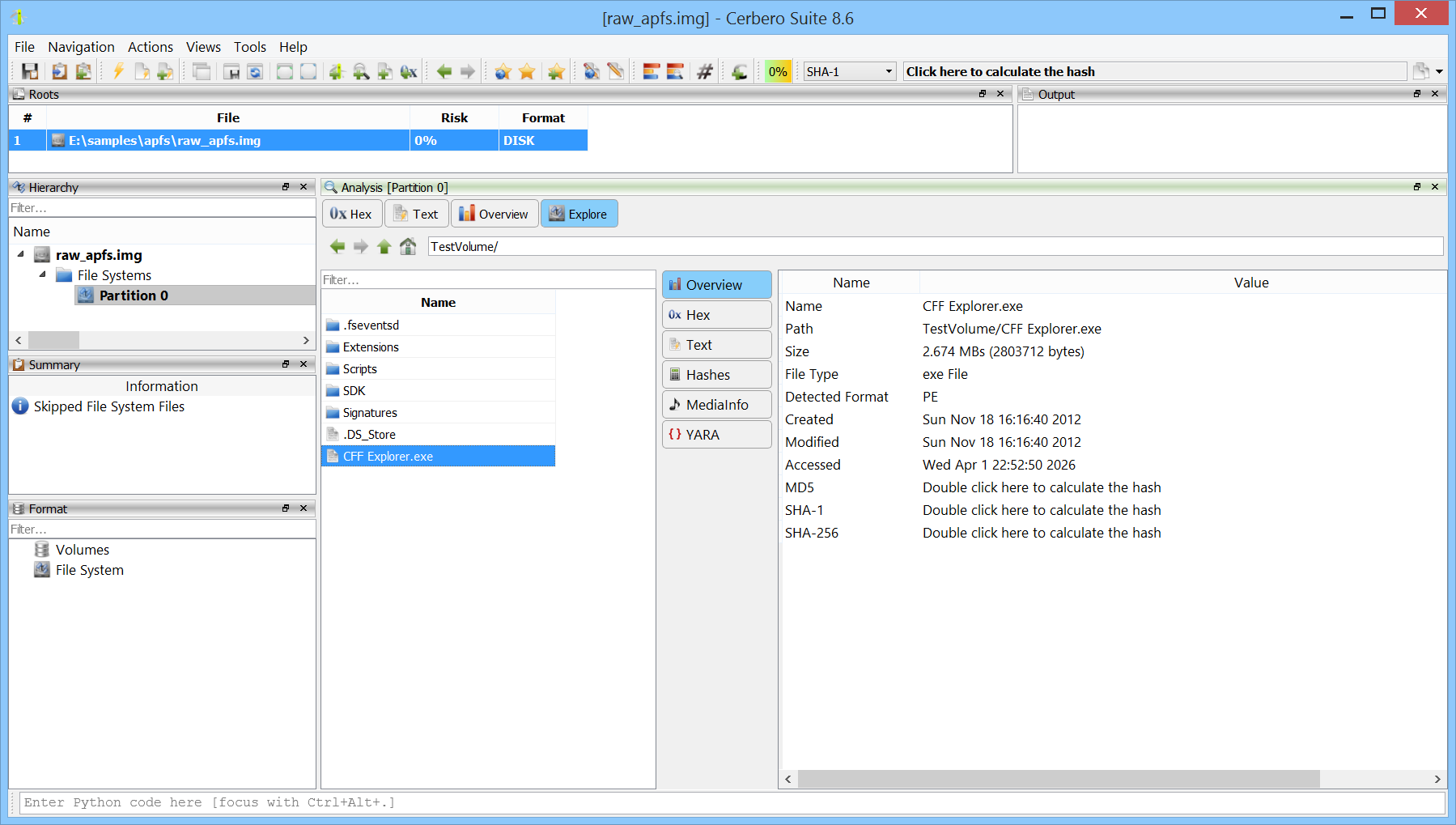
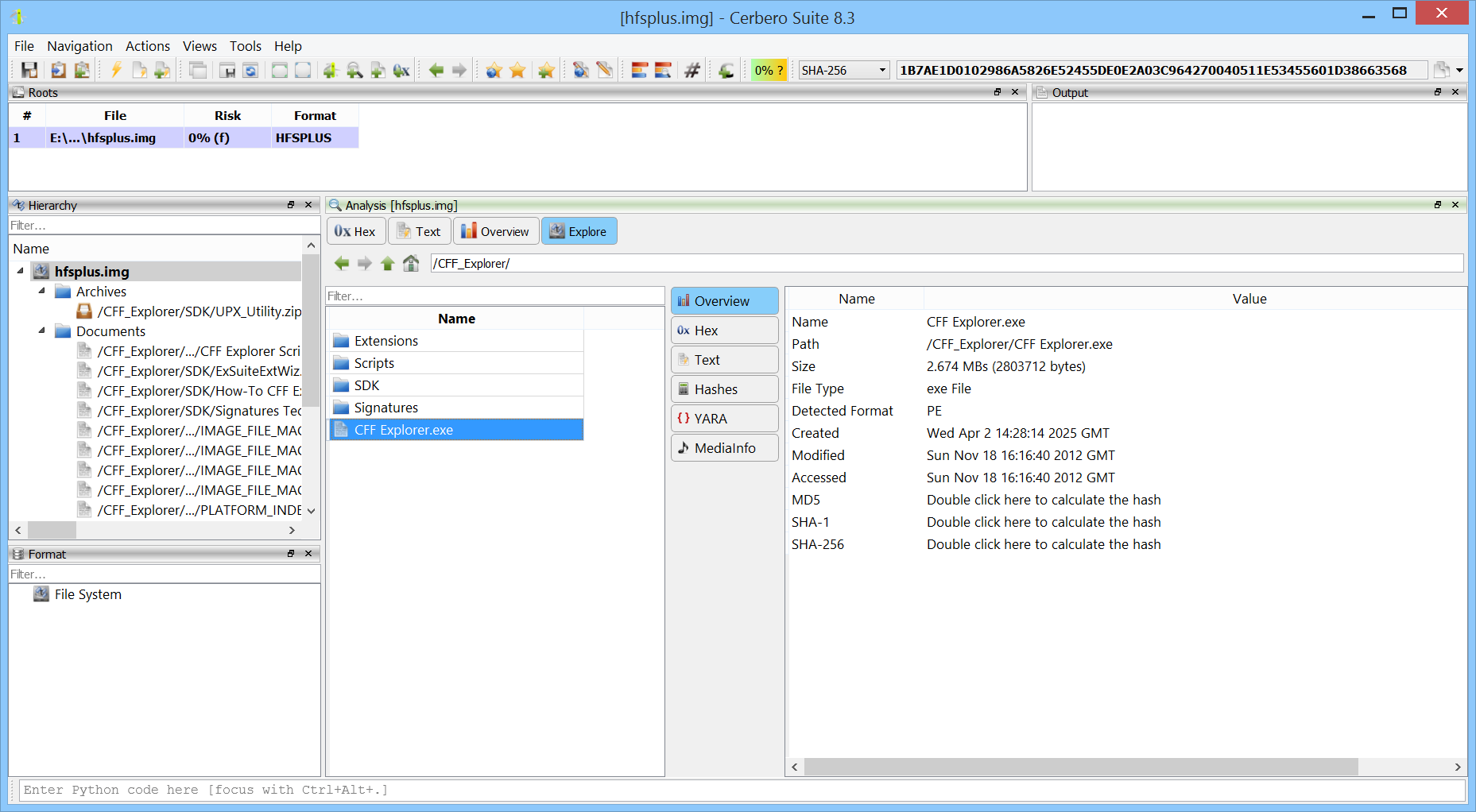
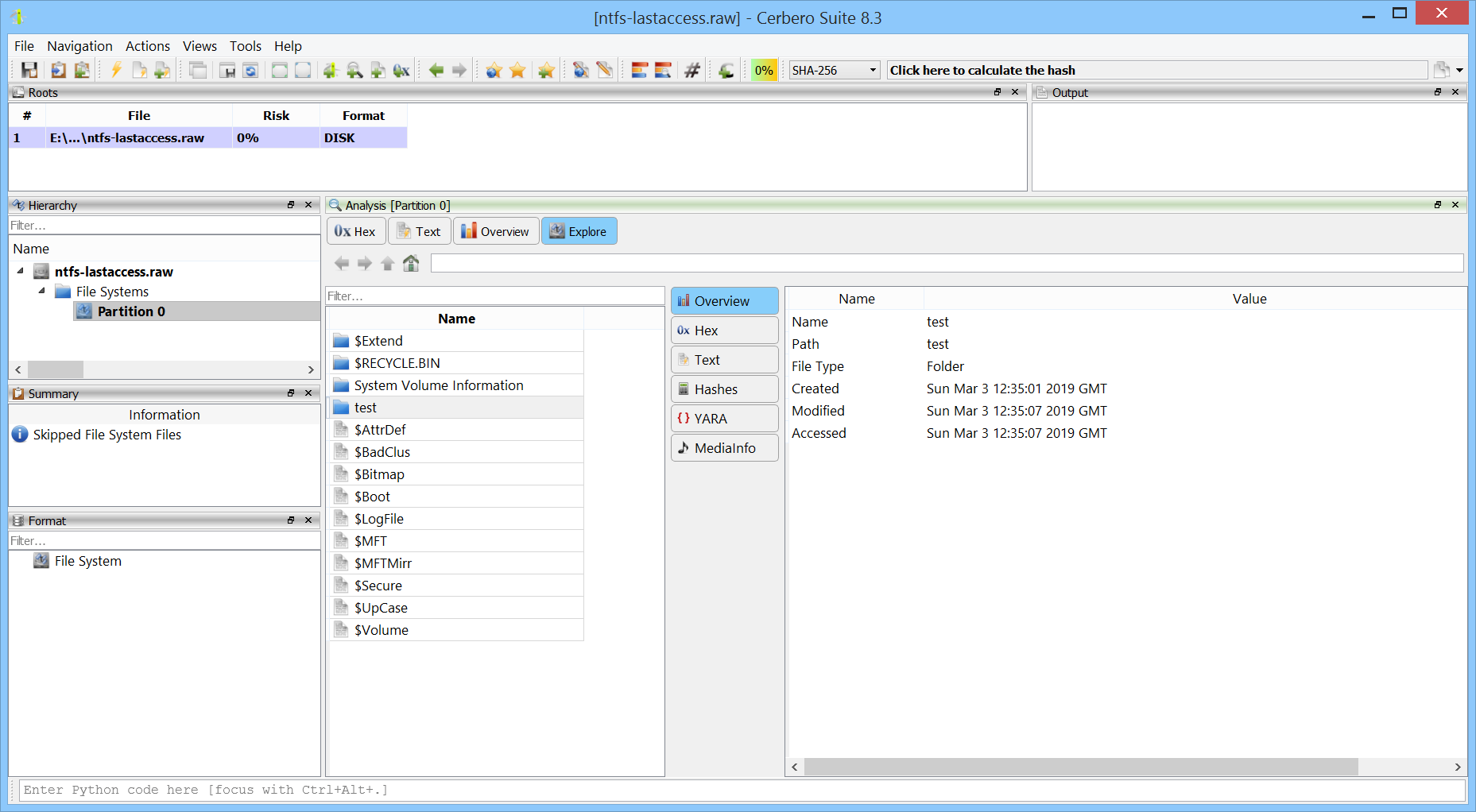
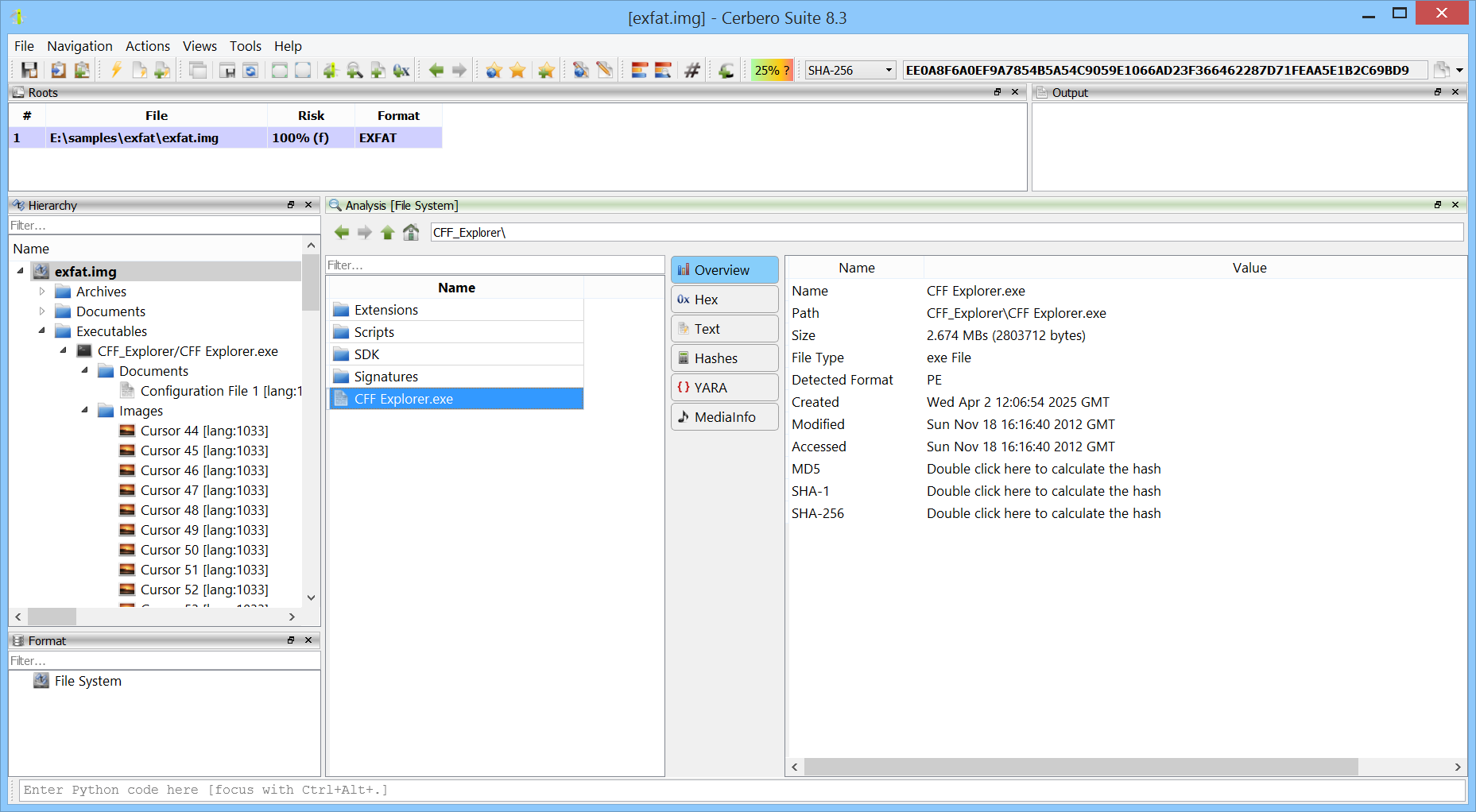
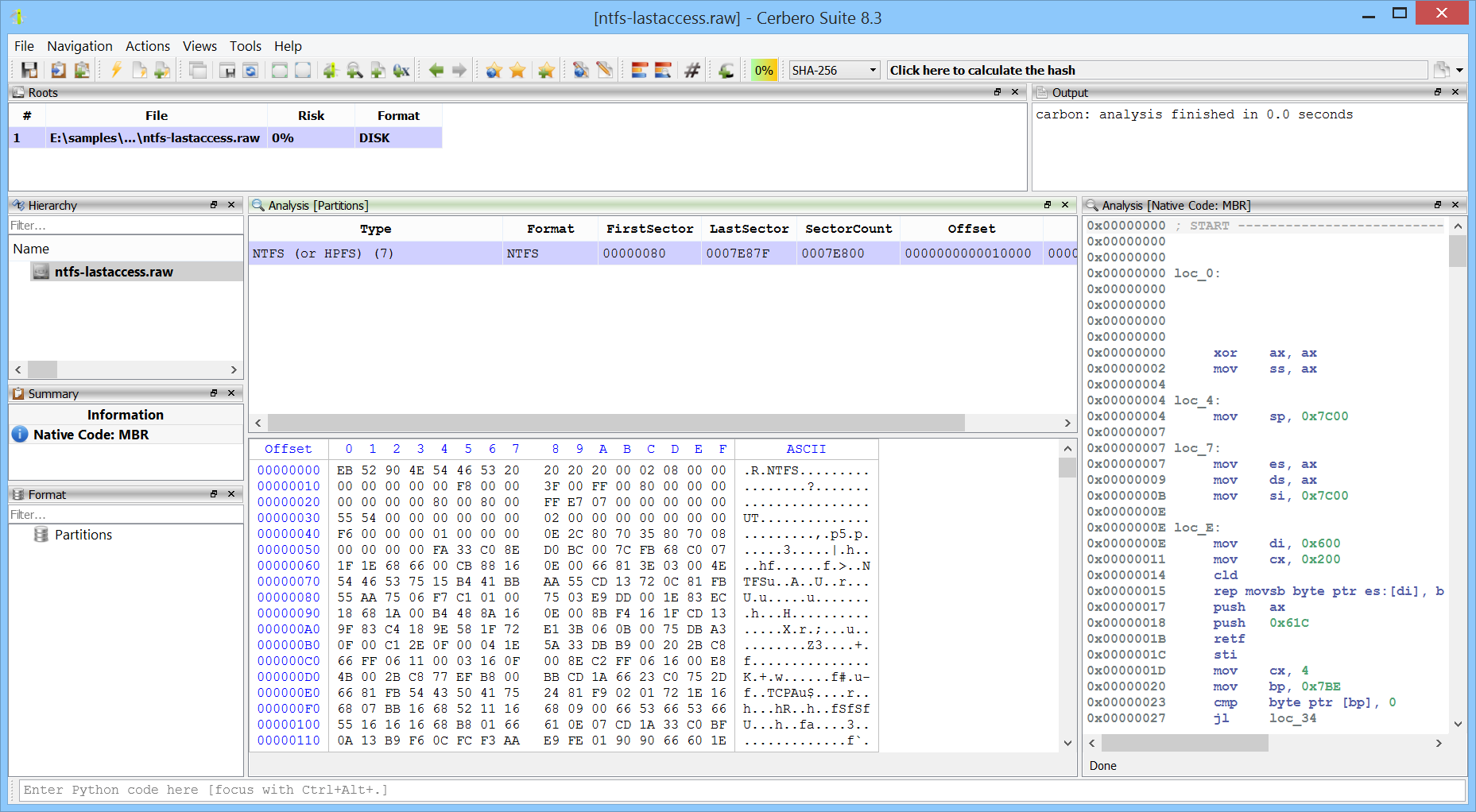
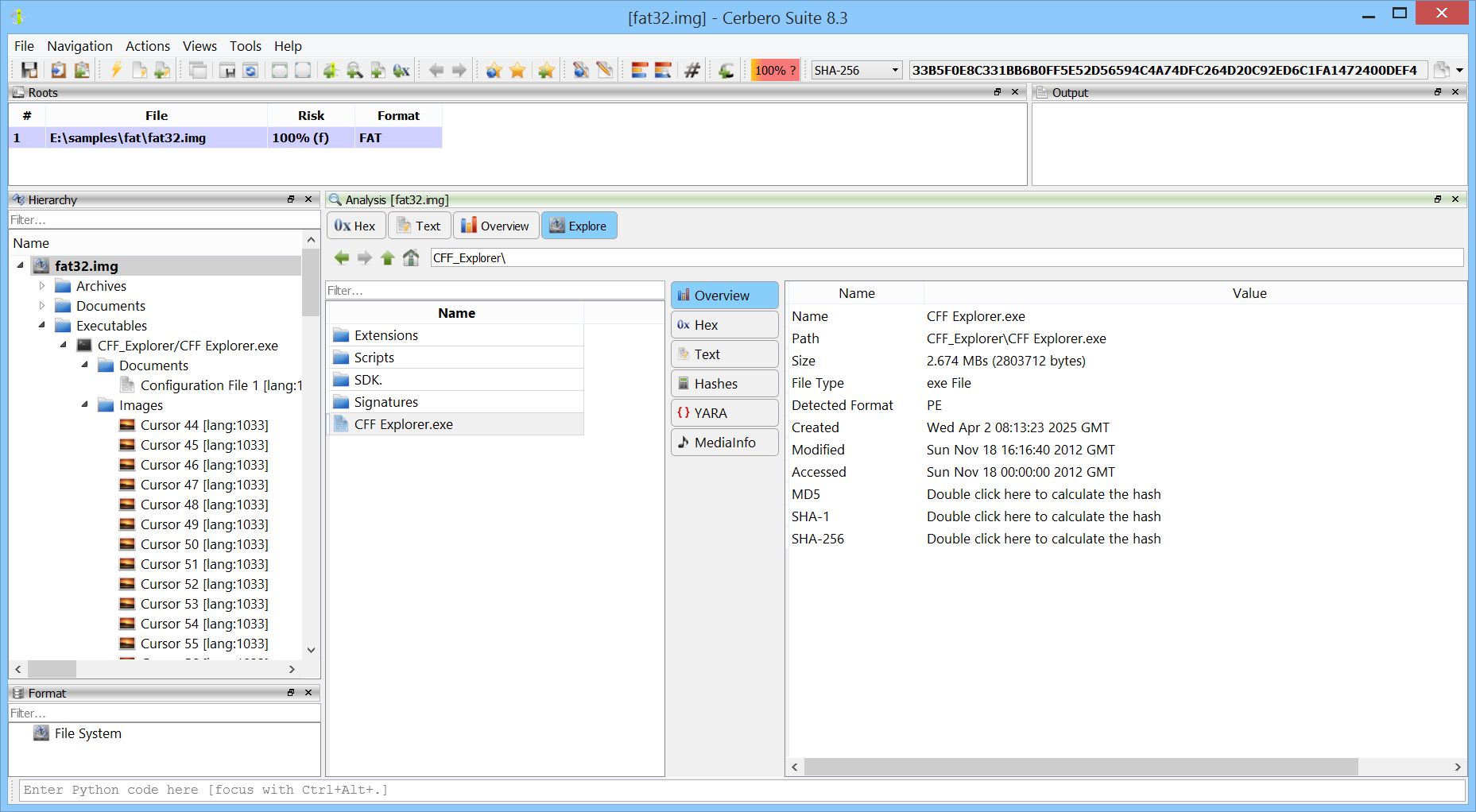
We are happy to announce support for Apple Disk Image (DMG) files. The new DMG Format package lets you inspect and extract the contents of DMG images directly within the application.
DMG is Apple’s native disk image format, widely used for distributing macOS software. A DMG file packages one or more partitions, each typically containing a file system such as APFS or HFS+. The data within these partitions is often compressed using algorithms like zlib, bzip2, LZFSE, LZMA, or ADC to reduce file size. Some DMG files are also encrypted with AES-128 or AES-256, requiring a password to access.
Having native DMG support in Cerbero Suite means analysts can examine macOS disk images encountered during forensic investigations, malware analysis, or software distribution review. Combined with our existing APFS and HFS+ support, this provides a complete pipeline for going from a DMG file all the way down to individual files within an APFS and HFS+ volumes.