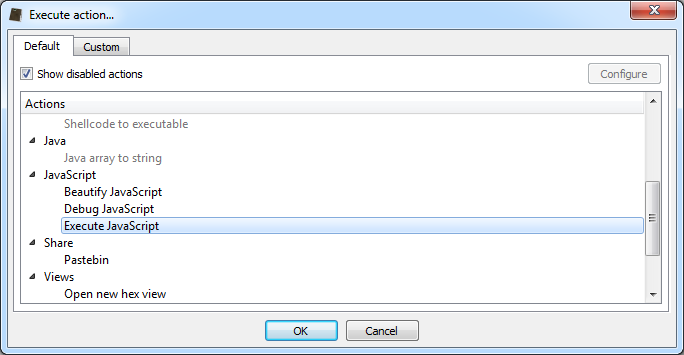
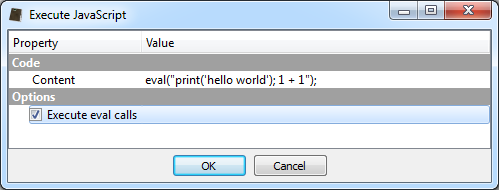
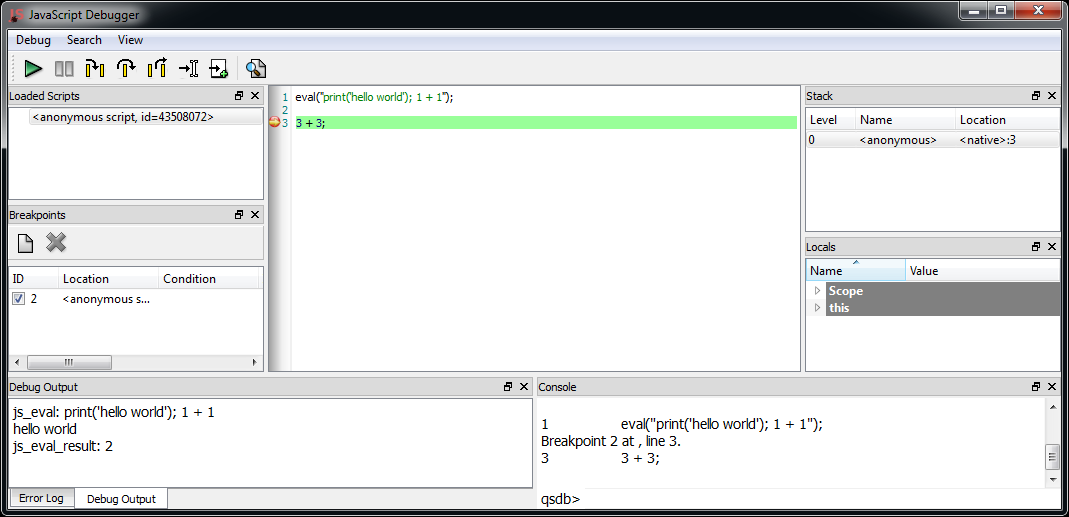
We have already shown in the past how simple it is to leverage the capabilities of Cerbero SDK to extract JavaScript from PDF documents using a simple hook.
In this post we’ll use a package to deploy the demo code.
The advantage of using an installable package is that it minimizes the effort on the part of the user to test the code and the deployment method is compatible with both Cerbero Suite and Cerbero Engine.
We explained how packages work in a previous post in case you missed that.
The demo code is the following:
from Pro.Core import *
def printJSEntry(sp, xml, tnode):
# data node
dnode = xml.findChild(tnode, "d")
if not dnode:
return
# we let Cerbero extract the JavaScript for us
params = NTStringVariantHash()
params.insert("op", "js")
idnode = xml.findChild(dnode, "id")
if idnode:
params.insert("id", int(xml.value(idnode), 16))
ridnode = xml.findChild(dnode, "rid")
if idnode:
params.insert("rid", int(xml.value(ridnode), 16))
js = sp.customOperation(params)
# print out the JavaScript
print("JS CODE")
print("-------")
print(js)
def pdfExtractJS(sp, ud):
xml = sp.getReportXML()
# object node
onode = xml.findChild(None, "o")
if onode:
# scan node
snode = xml.findChild(onode, "s")
if snode:
# enumerate scan entries
tchild = xml.firstChild(snode)
while tchild:
if xml.name(tchild) == "t":
# type attribute
tattr = xml.findAttribute(tchild, "t")
# check if it's a JavaScript entry
if tattr and int(xml.value(tattr)) == CT_JavaScript:
printJSEntry(sp, xml, tchild)
tchild = xml.nextSibling(tchild)
And the configuration for the hook extension is the following:
[PDF JavaScript Extraction Demo] file = pdf_js_extract_demo.py scanned = pdfExtractJS formats = PDF enable = yes
Out of this two parts we created a package with an automatic setup which you can download from here.
The package can be installed with a few clicks. In fact, on Windows it can be installed directly from the shell context menu.
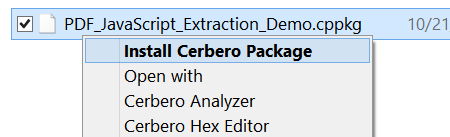
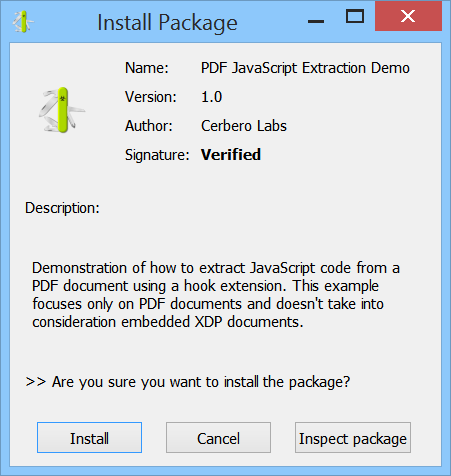
The setup dialog informs you that the package is verified as it was signed by Cerbero. Do not install the package if the signature couldn’t be verified!
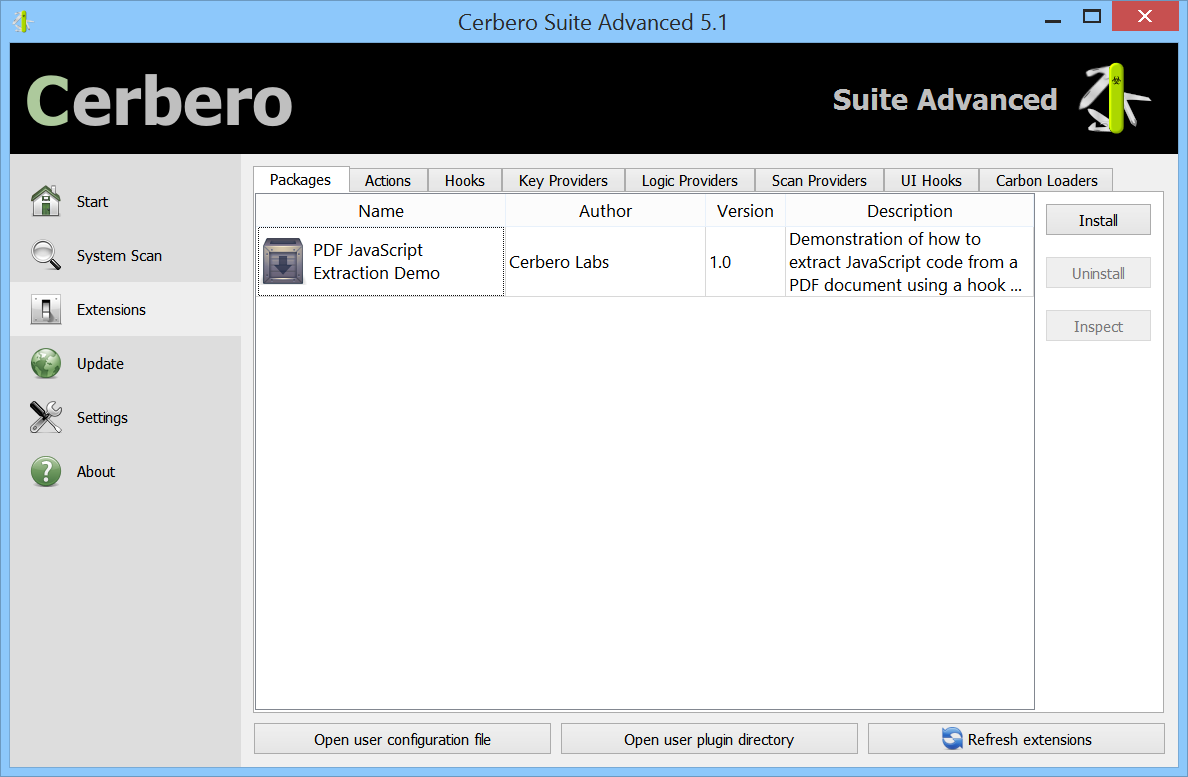
The package once installed is visible in the list of installed packages. From there it can be uninstalled.
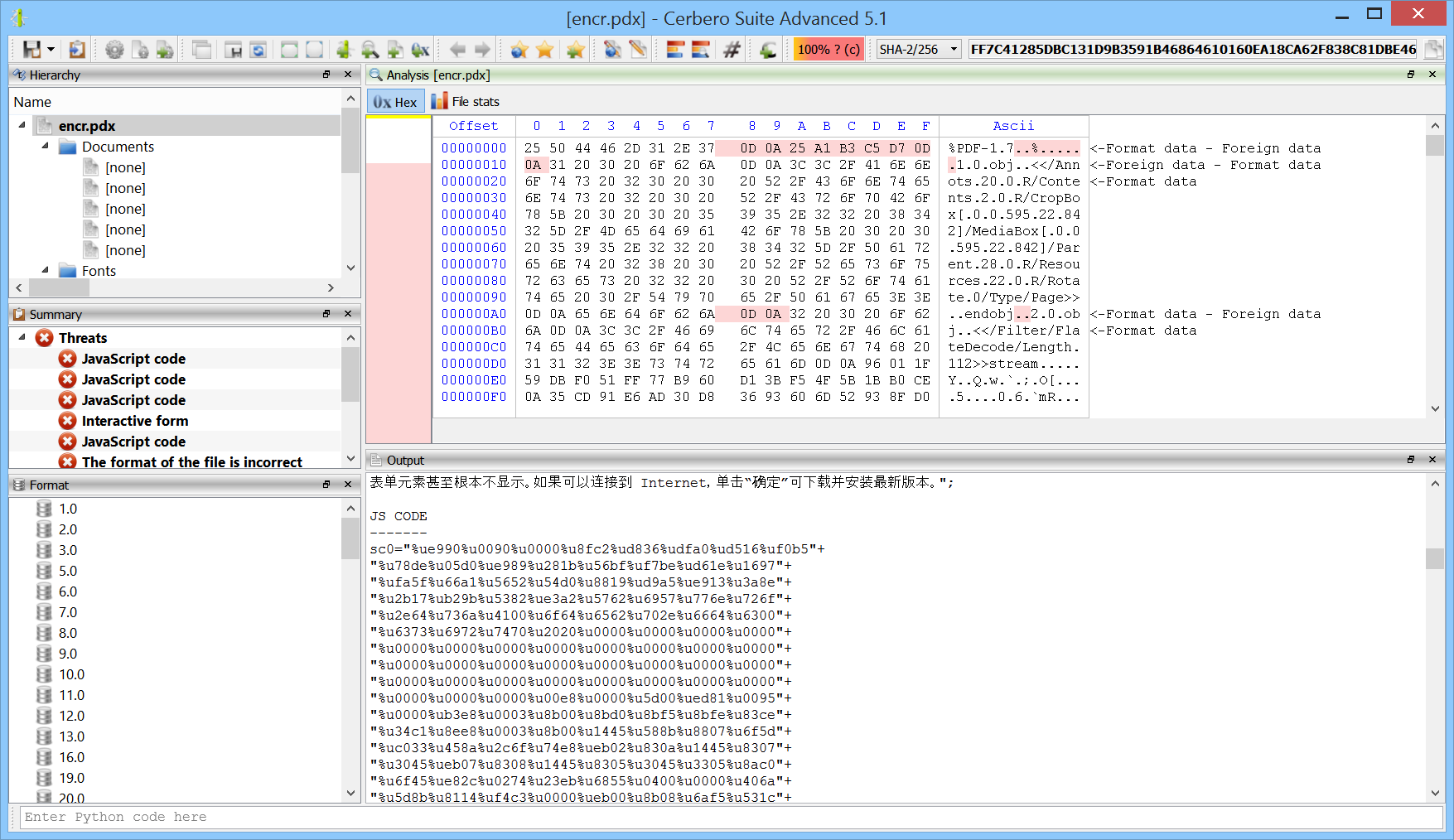
While the package is installed, it will print out the JavaScript code contained in PDF documents even if such documents are encrypted.
Packages are a not only a great way to deploy tools and plugins for Cerbero Suite and Cerbero Engine, but they also enable the secure deployment of demonstration snippets and other data.