Version 2.5.0 is close to being released and comes with the last type of extension exposed to Python: scan providers. Scan providers extensions are not only the most complex type of extensions, but also the most powerful ones as they allow to add support for new file formats entirely from Python!
This feature required exposing a lot more of the SDK to Python and can’t be completely discussed in one post. This post is going to introduce the topic, while future posts will show real life examples.
Let’s start from the list of Python scan providers under Extensions -> Scan providers:
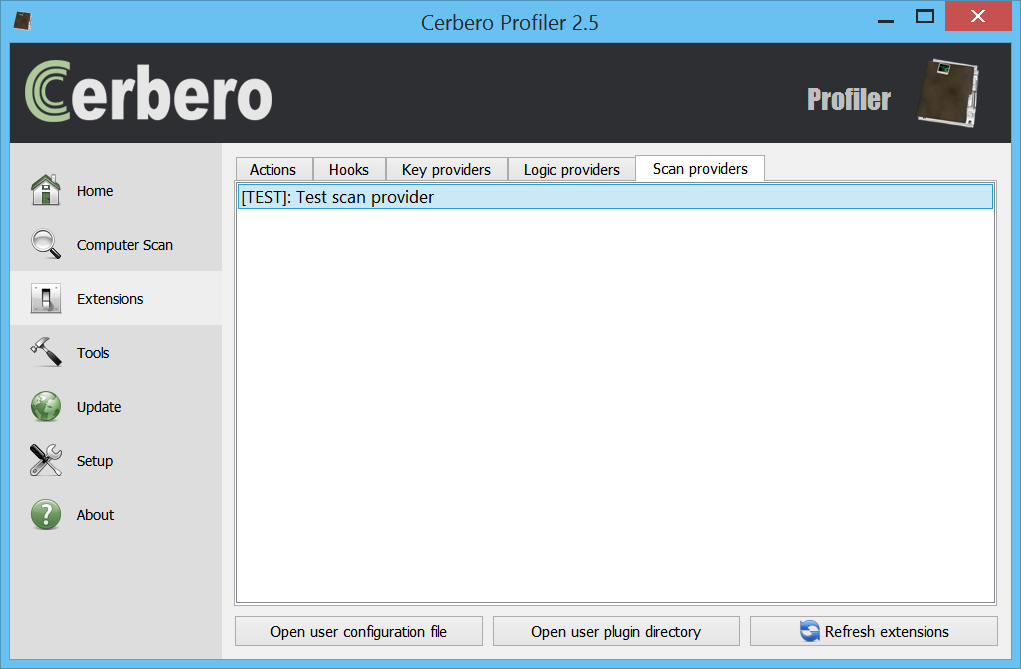
This list is retrieved from the configuration file ‘scanp.cfg’. Here’s an example entry:
[TEST]
label = Test scan provider
ext = test2,test3
group = db
file = Test.py
allocator = allocator The name of the section has two purposes: it specifies the name of the format being supported (in this case ‘TEST’) and also the name of the extension, which automatically is associated to that format (in this case ‘.test’, case insensitive). The hard limit for format names is 9 characters for now, this may change in the future if more are needed. The label is the description. The ext parameter is optional and specifies additional extensions to be associated to the format. group specifies the type of file which is being supported; available groups are: img, video, audio, doc, font, exe, manexe, arch, db, sys, cert, script. file specifies the Python source file and allocator the function which returns a new instance of the scan provider class.
Let’s start with the allocator:
def allocator():
return TestScanProvider() It just returns a new instance of TestScanProvider, which is a class dervided from ScanProvider:
class TestScanProvider(ScanProvider):
def __init__(self):
super(TestScanProvider, self).__init__()
self.obj = None Every scan provider has some mandatory methods it must override, let’s begin with the first ones:
def _clear(self):
self.obj = None
def _getObject(self):
return self.obj
def _initObject(self):
self.obj = TestObject()
self.obj.Load(self.getStream())
return self.SCAN_RESULT_OK _clear gives a chance to free internal resources when they’re no longer used. In Python this is not usually important as member objects will automatically be freed when their reference count reaches zero.
_getObject must return the internal instance of the object being parsed. This must return an instance of a CFFObject derived class.
_initObject creates the object instance and loads the data stream into it. In the sample above we assume it being successful. Otherwise, we would have to return SCAN_RESULT_ERROR. This method is not called by the main thread, so that it doesn’t block the UI during long parse operations.
Let’s take a look at the TestObject class:
class TestObject(CFFObject):
def __init__(self):
super(TestObject, self).__init__()
self.SetObjectFormatName("TEST")
self.SetDefaultEndianness(ENDIANNESS_LITTLE) This is a minimalistic implementation of a CFFObject derived class. Usually it should contain at least an override of the CustomLoad method, which gives the opportunity to fail when the data stream is first loaded through the Load method. SetDefaultEndianness wouldn’t even be necessary, as every object defaults to little endian by default. SetObjectFormatName, on the other hand, is very important, as it sets the internal format name of the object.
Let’s now take a look at how we scan a file:
def _startScan(self):
return self.SCAN_RESULT_OK
def _threadScan(self):
e = ScanEntryData()
e.category = SEC_Warn
e.type = CT_NativeCode
self.addEntry(e) The code above will issue a single warning concerning native code. When _startScan returns SCAN_RESULT_OK, _threadScan will be called from a thread other than the main UI one. The logic behind this is that _startScan is actually called from the main thread and if the scan of the file doesn’t require complex operations, like in the case above, then the method could return SCAN_RESULT_FINISHED and then _threadScan won’t be called at all. During a threaded scan, an abort by the user can be detected via the isAborted method.
From the UI side point of view, when a scan entry is clicked in summary, the scan provider is supposed to return UI information.
def _scanViewData(self, xml, dnode, sdata):
if sdata.type == CT_NativeCode:
sdata.setViews(SCANVIEW_TEXT)
sdata.data.setData("Hello, world!")
return True
return False This will display a text field with a predefined content when the user clicks the scan entry in the summary. This is fairly easy, but what happens when we have several entries of the same type and need to differentiate between them? There’s where the data member of ScanEntryData plays a role, this is a string which will be included in the report xml and passed again back to _scanViewData as an xml node.
For instance:
e.data = "1234 " Becomes this in the final XML report:
1234
The dnode argument of _scanViewData points to the ‘d’ node and its first child will be the ‘o’ node we passed. the xml argument represents an instance of the NTXml class, which can be used to retrieve the children of the dnode.
But this is only half of the story: some of the scan entries may represent embedded files (category SEC_File), in which case the _scanViewData method must return the data representing the file.
Apart from scan entries, we may also want the user to explore the format of the file. To do that we must return a tree representing the structure of our file:
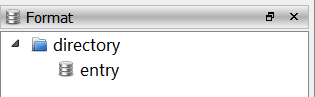
def _getFormat(self):
ft = FormatTree()
ft.enableIDs(True)
fi = ft.appendChild(None, 1)
ft.appendChild(fi, 2)
return ft The enableIDs method must be called right after creating a new FormatTree class. The code above creates a format item with id 1 with a child item with id 2, which results in the following:
But of course, we haven’t specified neither labels nor different icons in the function above. This information is retrieved for each item when required through the following method:
def _formatViewInfo(self, finfo):
if finfo.fid == 1:
finfo.text = "directory"
finfo.icon = PubIcon_Dir
return True
elif finfo.fid == 2:
finfo.text = "entry"
return True
return False The various items are identified by their id, which was specified during the creation of the tree.
The UI data for each item is retrieved through the _formatViewData method:
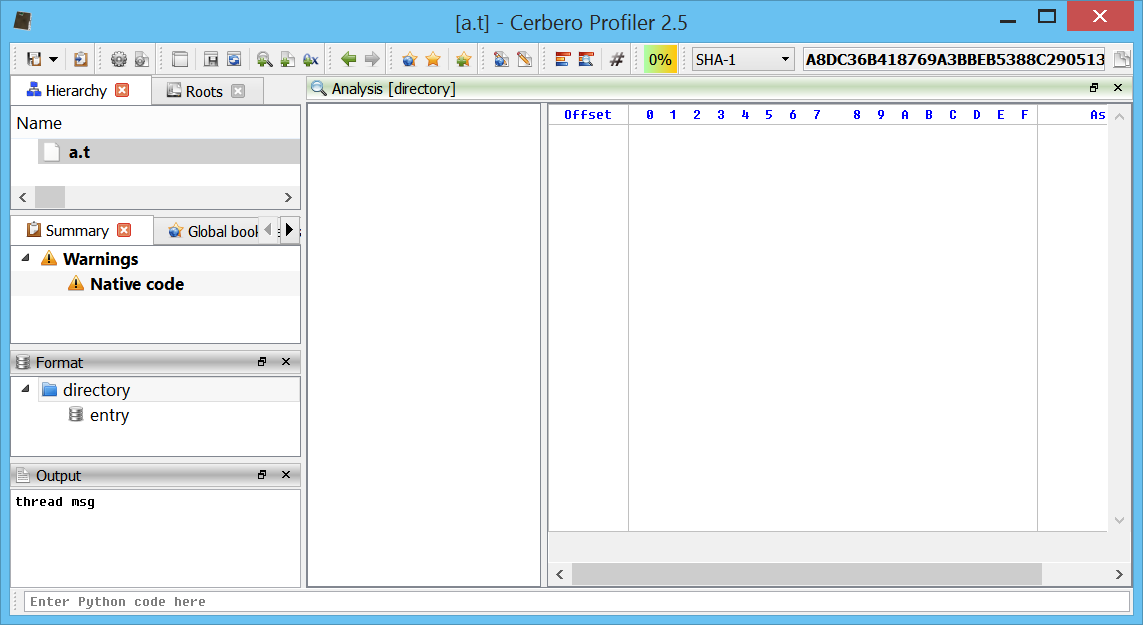
def _formatViewData(self, sdata):
if sdata.fid == 1:
sdata.setViews(SCANVIEW_CUSTOM)
sdata.data.setData("
This will display a custom view with a table and a hex view separated by a splitter:
Of course, also have specified the callback for our custom view:
def cb(cv, ud, code, view, data):
if code == pvnInit:
return 1
return 0 It is good to remember that format item IDs and IDs used in custom views are used to encode bookmark jumps. So if they change, saved bookmark jumps become invalid.
And here again the whole code for a better overview:
from Pro.Core import *
from Pro.UI import pvnInit, PubIcon_Dir
class TestObject(CFFObject):
def __init__(self):
super(TestObject, self).__init__()
self.SetObjectFormatName("TEST")
self.SetDefaultEndianness(ENDIANNESS_LITTLE)
def cb(cv, ud, code, view, data):
if code == pvnInit:
return 1
return 0
class TestScanProvider(ScanProvider):
def __init__(self):
super(TestScanProvider, self).__init__()
self.obj = None
def _clear(self):
self.obj = None
def _getObject(self):
return self.obj
def _initObject(self):
self.obj = TestObject()
self.obj.Load(self.getStream())
return self.SCAN_RESULT_OK
def _startScan(self):
return self.SCAN_RESULT_OK
def _threadScan(self):
print("thread msg")
e = ScanEntryData()
e.category = SEC_Warn
e.type = CT_NativeCode
self.addEntry(e)
def _scanViewData(self, xml, dnode, sdata):
if sdata.type == CT_NativeCode:
sdata.setViews(SCANVIEW_TEXT)
sdata.data.setData("Hello, world!")
return True
return False
def _getFormat(self):
ft = FormatTree()
ft.enableIDs(True)
fi = ft.appendChild(None, 1)
ft.appendChild(fi, 2)
return ft
def _formatViewInfo(self, finfo):
if finfo.fid == 1:
finfo.text = "directory"
finfo.icon = PubIcon_Dir
return True
elif finfo.fid == 2:
finfo.text = "entry"
return True
return False
def _formatViewData(self, sdata):
if sdata.fid == 1:
sdata.setViews(SCANVIEW_CUSTOM)
sdata.data.setData("
If you have noticed from the screen-shot above, the analysed file is called ‘a.t’ and as such doesn’t automatically associate to our ‘test’ format. So how does it associate anyway?
Clearly Profiler doesn’t rely on extensions alone to identify the format of a file. For external scan providers a signature mechanism based on YARA has been introduced. In the config directory of the user, you can create a file named ‘yara.plain’ and insert your identification rules in it, e.g.:
rule test
{
strings:
$sig = "test"
condition:
$sig at 0
} This rule will identify the format as ‘test’ if the first 4 bytes of the file match the string ‘test’: the name of the rule identifies the format.
The file ‘yara.plain’ will be compiled to the binary ‘yara.rules’ file at the first run. In order to refresh ‘yara.rules’, you must delete it.
One important thing to remember is that a rule isn’t matched against an entire file, but only against the first 512 bytes.
Of course, our provider behaves 100% like all other providers and can be used to load embedded files:
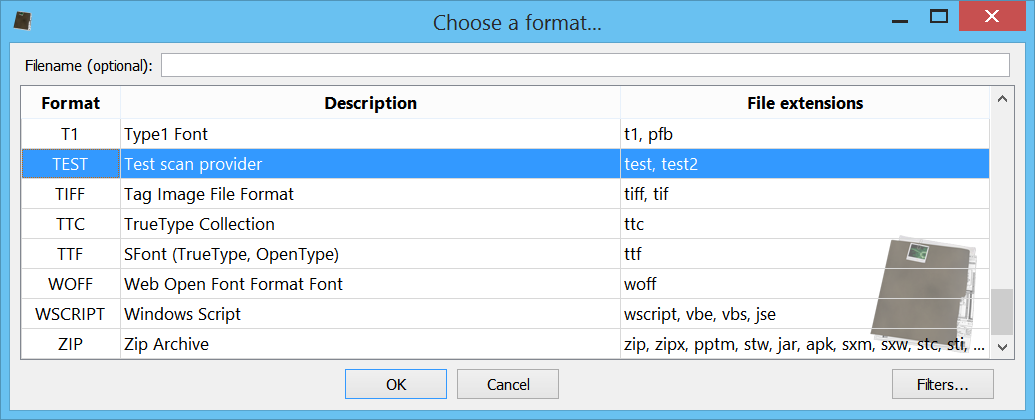
Our new provider is used automatically when an embedded file is identified as matching our format.