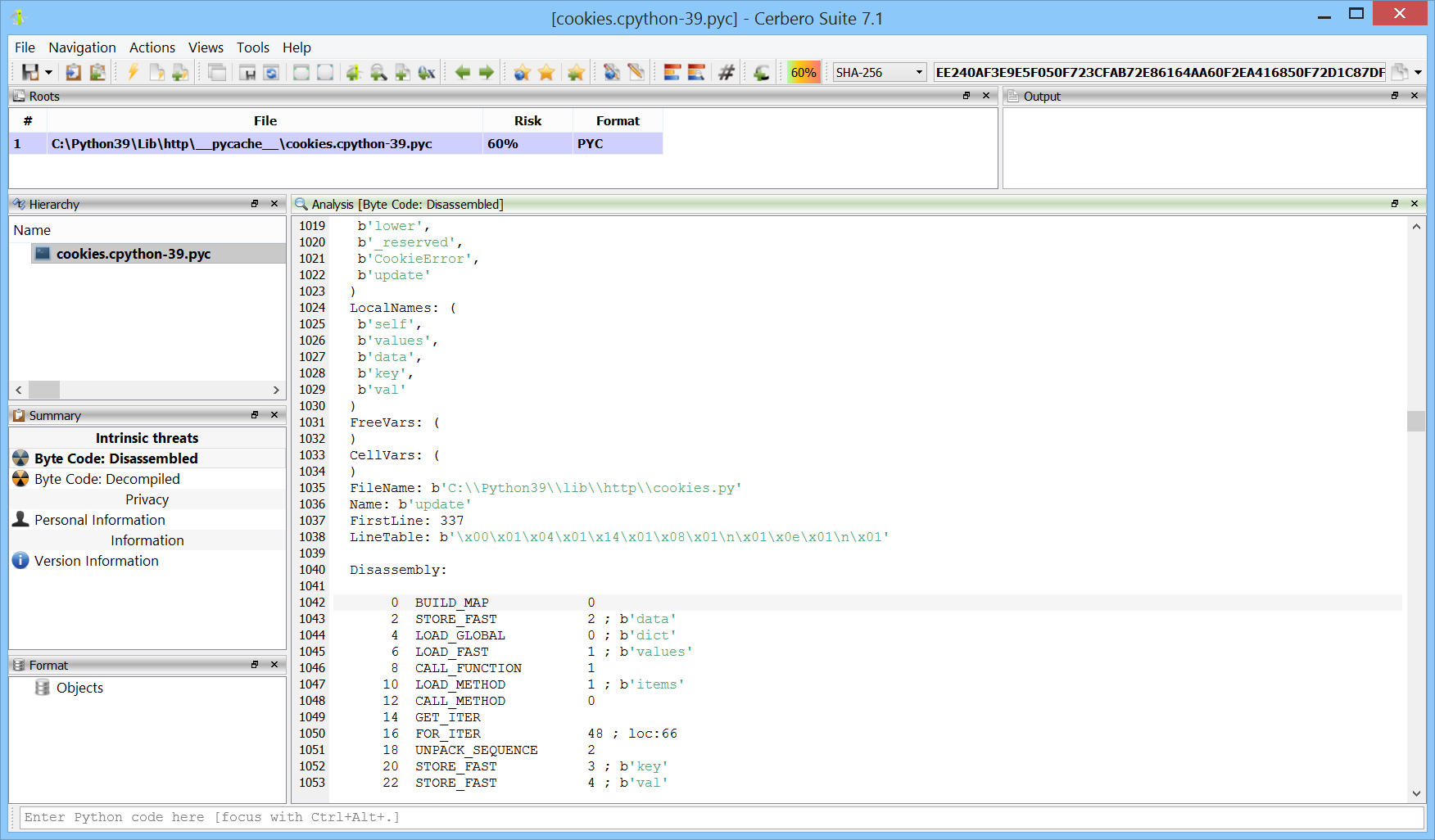
We have released the PyInstaller Extractor package for all licenses of Cerbero Suite.
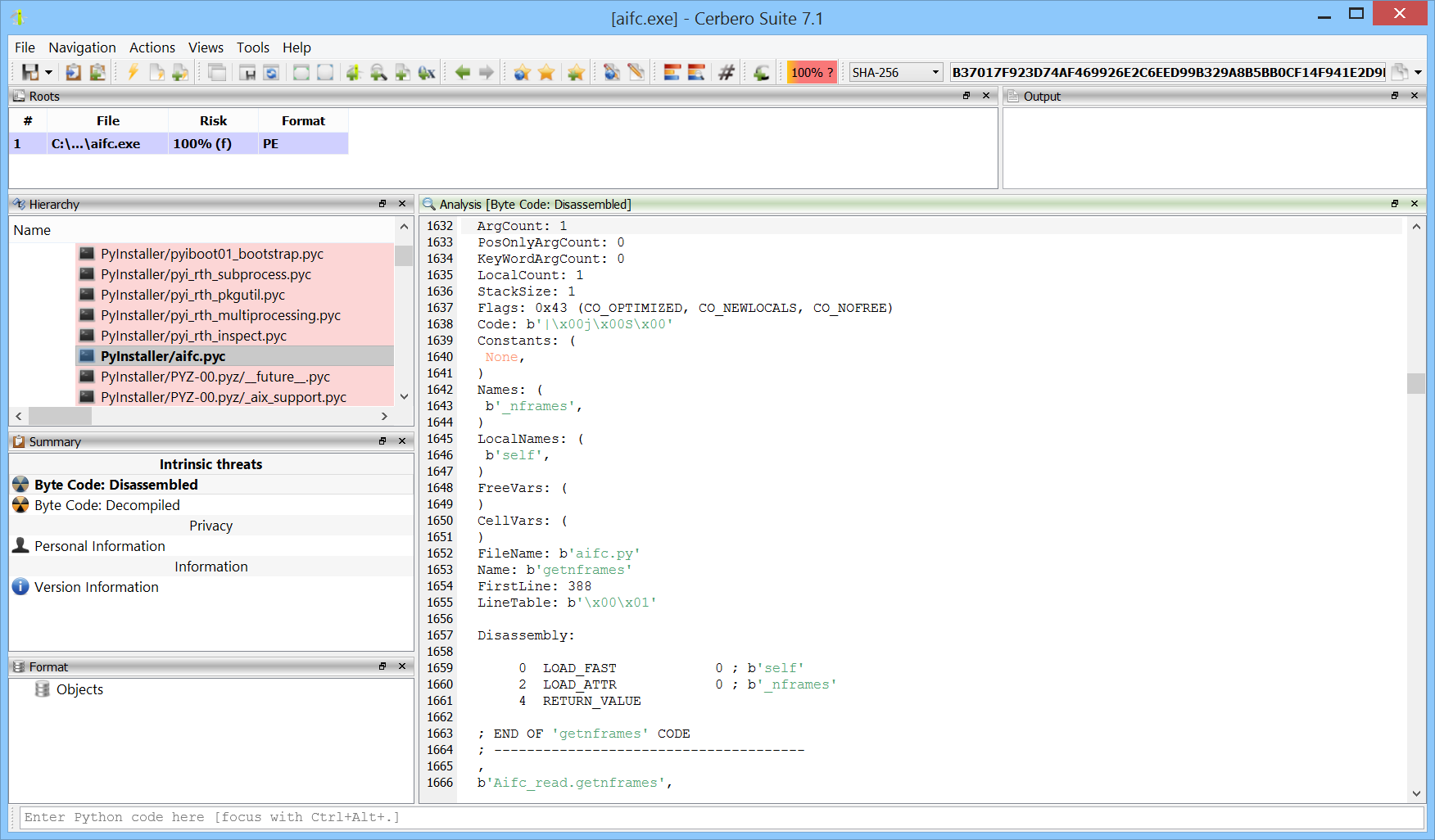
PyInstaller is a tool that packages Python applications into standalone executables, compatible with Windows, Linux, and macOS. It works by analyzing Python scripts to discover every import statement and include the appropriate Python files, binaries, and libraries in the executable. Additionally, PyInstaller converts all Python code into bytecode before packaging, enhancing performance and security.
The extractor supports all versions of PyInstaller, all supported file types and automatically identifies PyInstaller generated binaries. It also supports PyInstaller bytecode decryption.