We’re happy to announce the release of Cerbero Suite 7.3 and Cerbero Engine 4.3! This release brings a multitude of enhancements, and in this post, we will highlight the most significant additions.
Cerbero Suite 7.2 Release
We have released Cerbero Suite 7.2 and Cerbero Engine 4.2. This release introduces numerous minor improvements and bug fixes. In this post, we’ll detail the most significant additions.
OneNote Format 2.0 Package
We have released version 2 of the OneNote Format package. This latest version introduces numerous enhancements and expands the scope of information extraction capabilities.
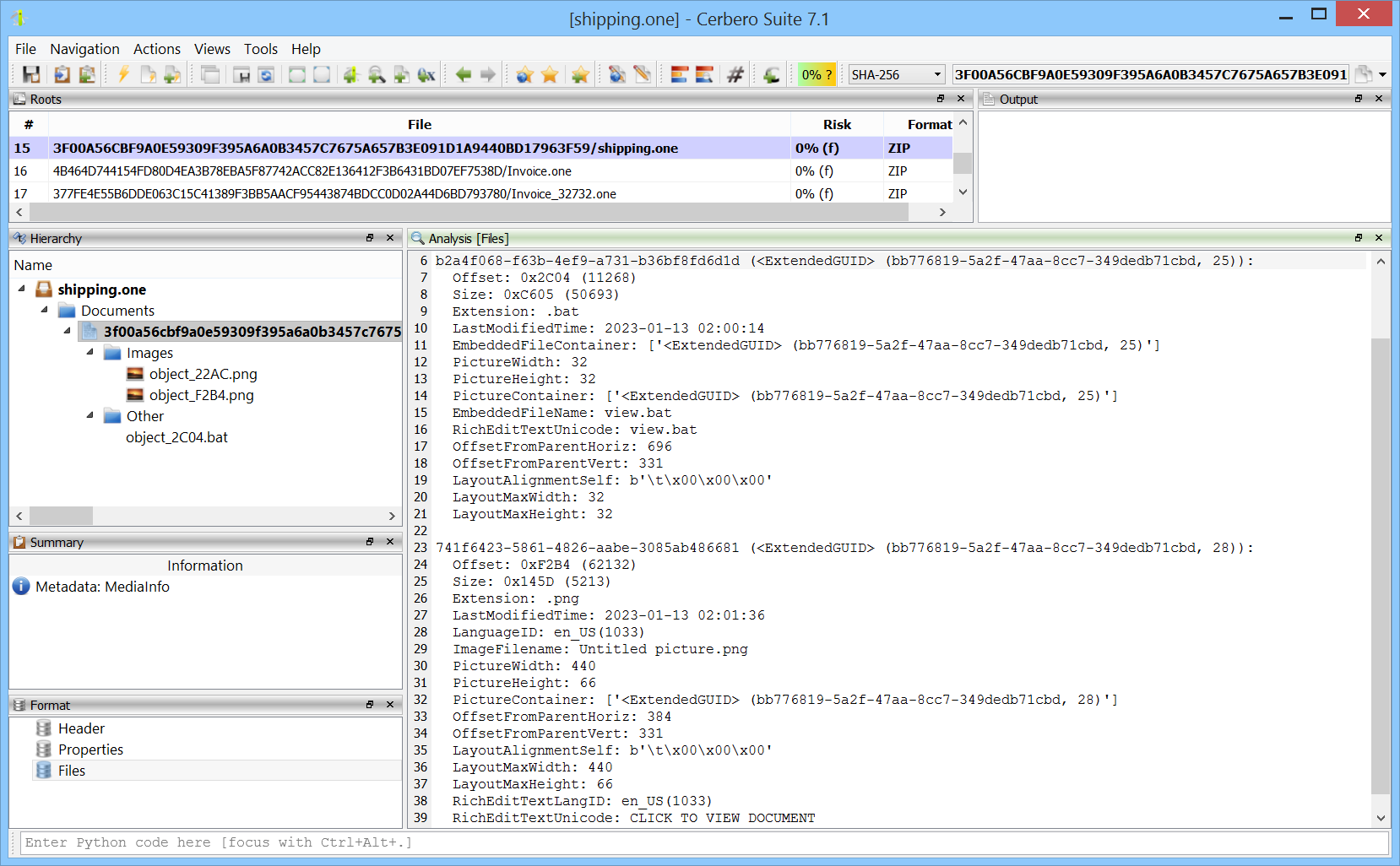
In this update, we’ve focused particularly on improving the utility for forensic analysis, ensuring that you can extract more detailed information from OneNote documents.
MediaInfo Package
We’re very happy to announce the release of the MediaInfo package for all licenses of Cerbero Suite!
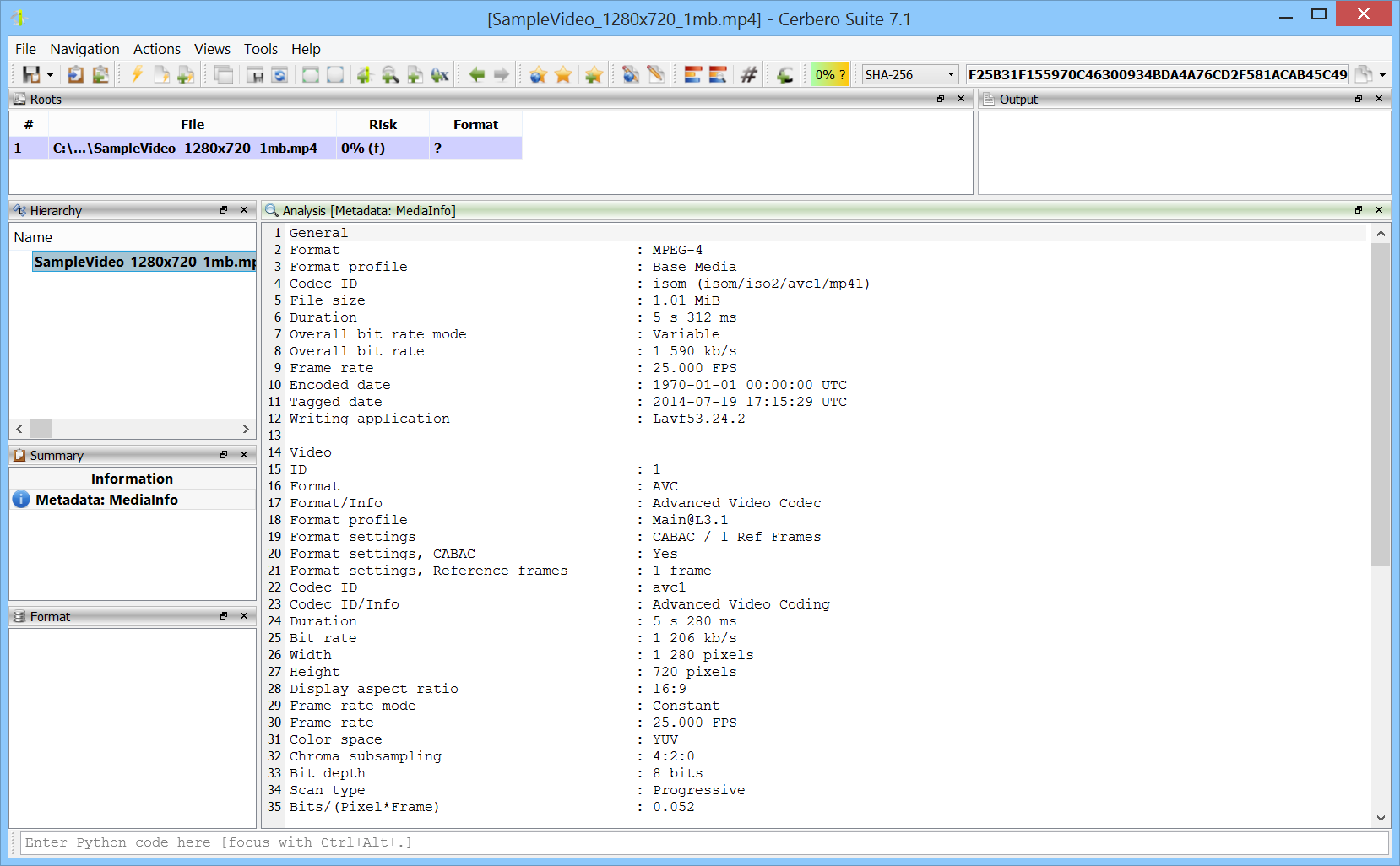
The MediaInfo package supports a vast array of media file types, providing essential metadata information. This is particularly important for covering file types that do not yet have official support.
Cerbero Journal Issue 4
The 4th issue of Cerbero Journal, our company e-zine, is out!

Since the last issue of our journal, there have been significant developments: the release of Cerbero Suite 7, accompanied by many new packages.
Py2Exe Extractor Package
We have released the Py2Exe Extractor package for all licenses of Cerbero Suite.
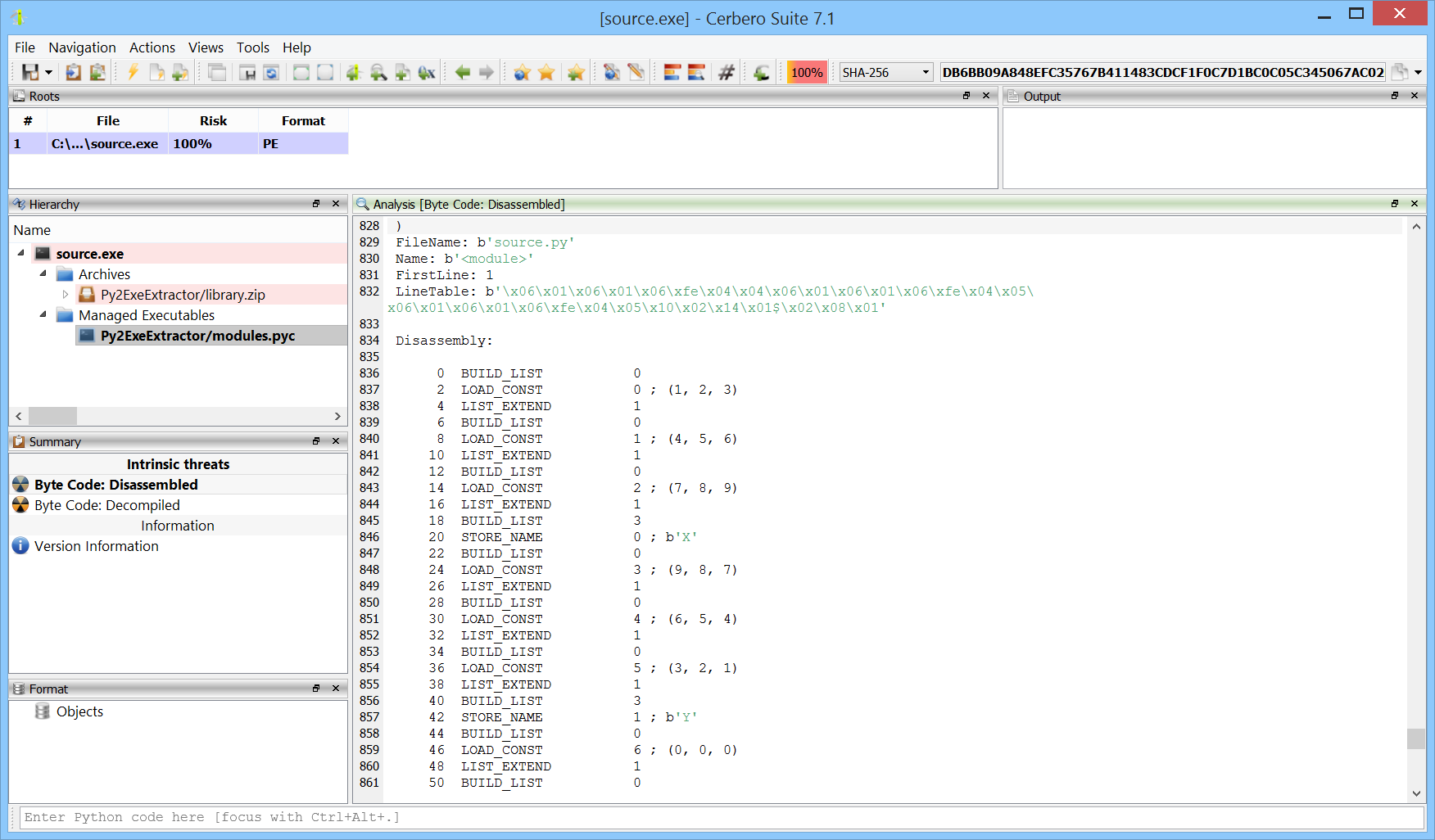
py2exe is a Python package that converts Python scripts into executable Windows programs. The tool packages Python bytecode and the necessary libraries into a single executable file, eliminating the need for a Python interpreter to be installed on the client machine. py2exe works by analyzing the imported modules in the Python script and includes them along with a Python interpreter as a part of the generated executable.
The extractor supports all versions of py2exe and automatically identifies py2exe generated executables.
PyInstaller Extractor Package
We have released the PyInstaller Extractor package for all licenses of Cerbero Suite.
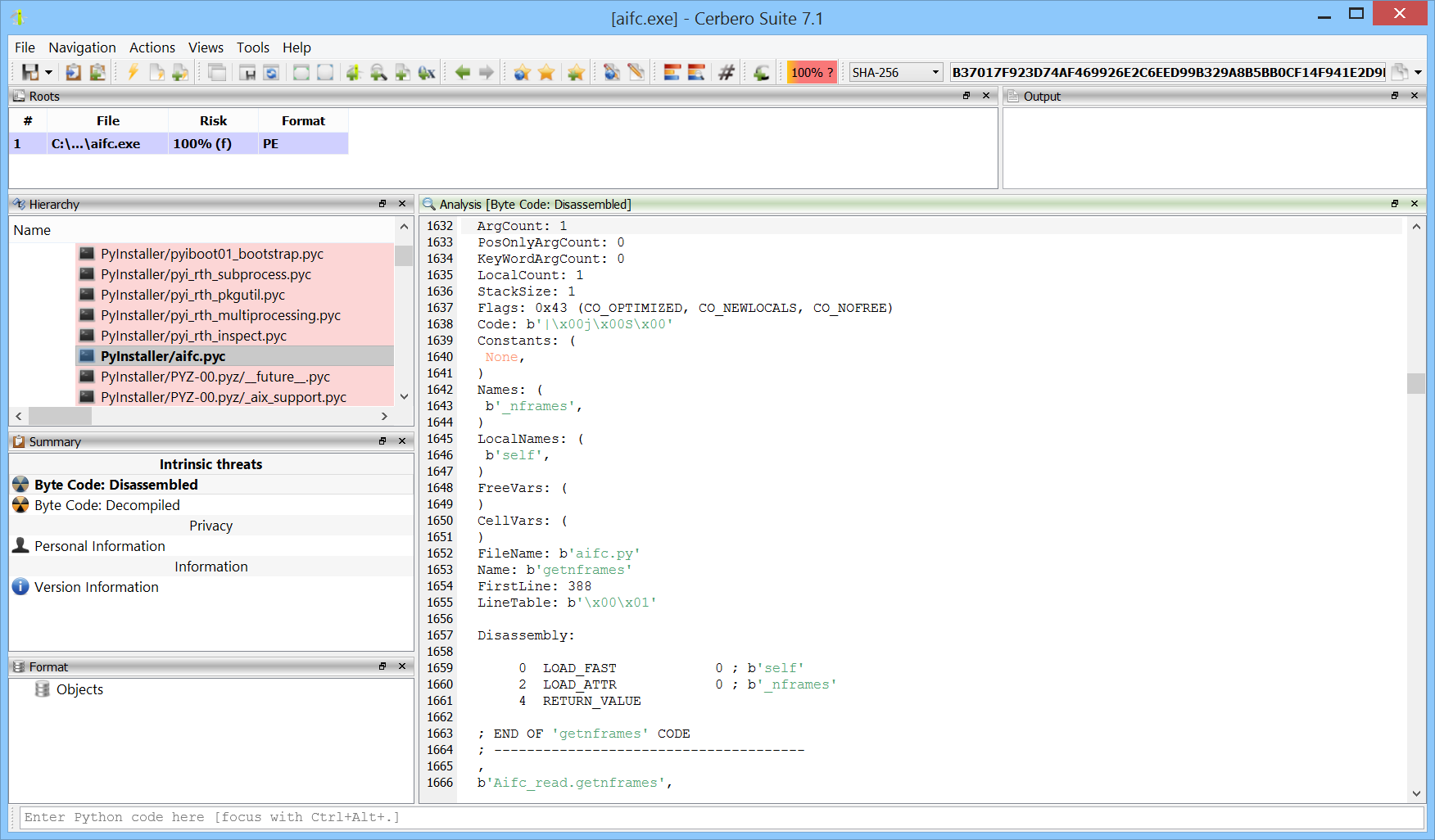
PyInstaller is a tool that packages Python applications into standalone executables, compatible with Windows, Linux, and macOS. It works by analyzing Python scripts to discover every import statement and include the appropriate Python files, binaries, and libraries in the executable. Additionally, PyInstaller converts all Python code into bytecode before packaging, enhancing performance and security.
The extractor supports all versions of PyInstaller, all supported file types and automatically identifies PyInstaller generated binaries. It also supports PyInstaller bytecode decryption.
PYC Format Package
We have released the PYC Format package for all licenses of Cerbero Suite.
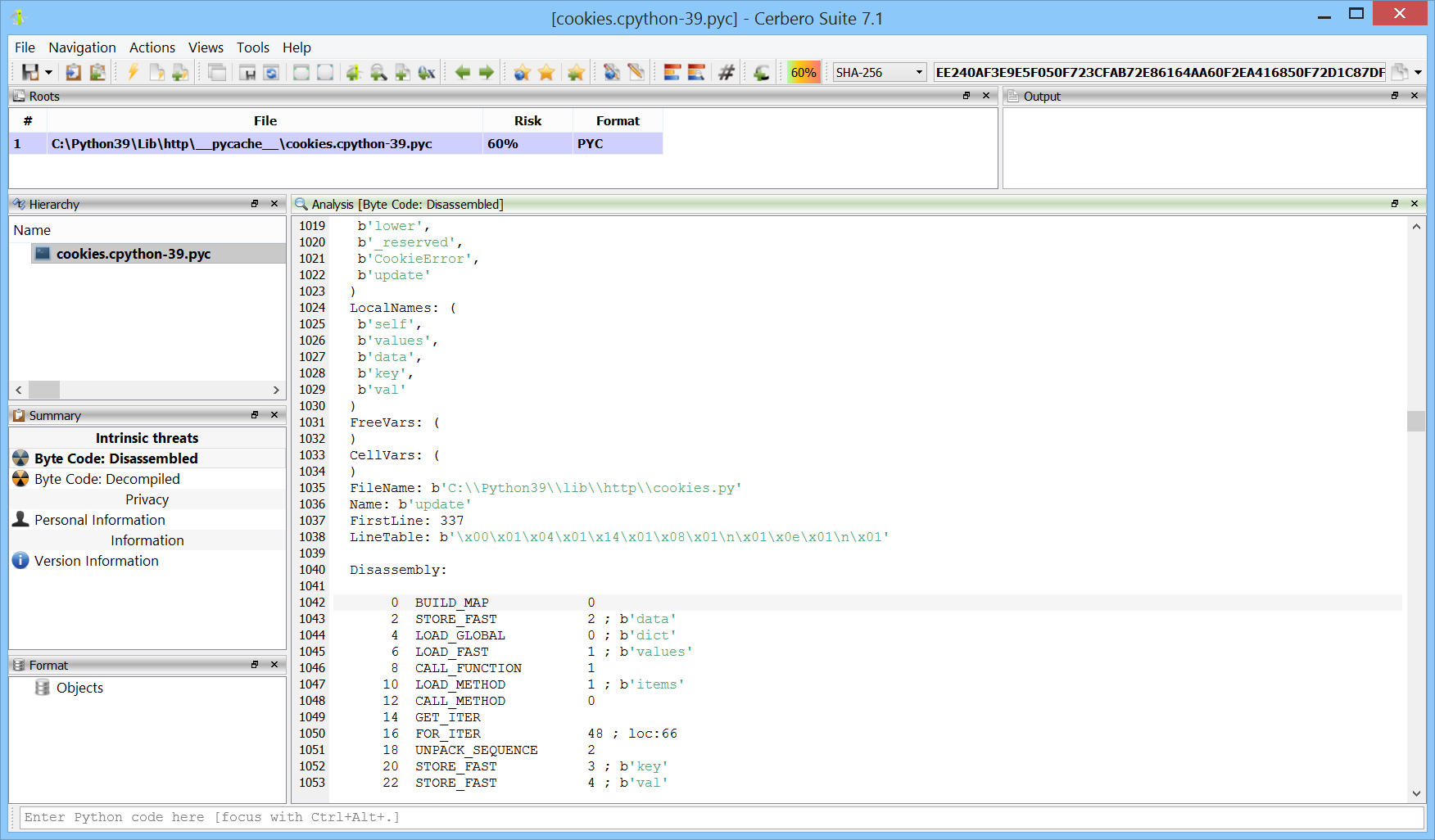
PYC files are compiled bytecode versions of Python source code. These compiled files can be deployed in place of the original source code, serving as a bytecode format for execution by the Python interpreter. PYC files are tied to the specific version of Python they were compiled with, necessitating recompilation when different Python versions are used.
RPM Format Package
We have released the RPM Format package for all licenses of Cerbero Suite.
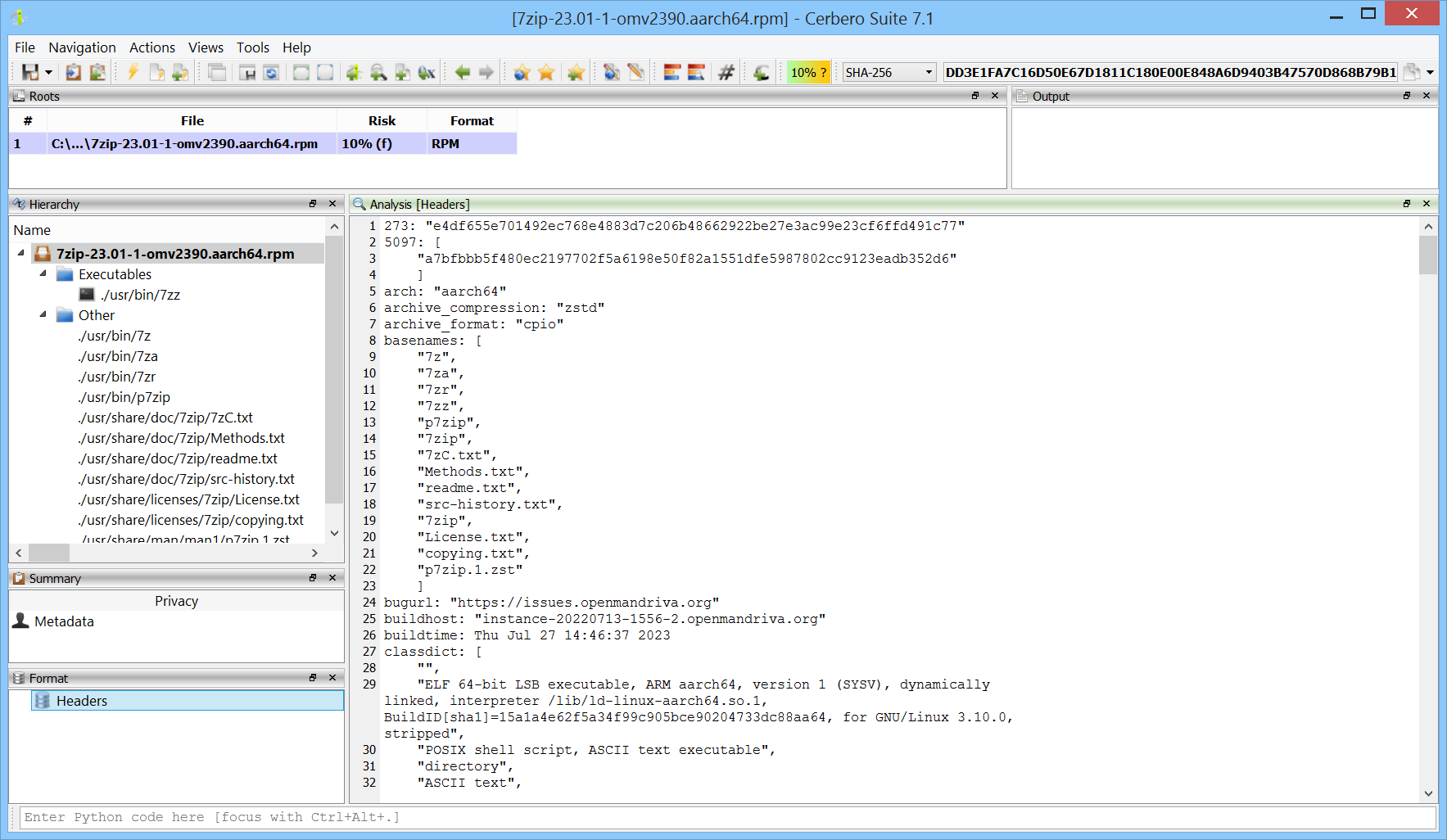
The RPM Package Manager (RPM) format is a package management system used primarily in Red Hat-based Linux distributions, including Fedora and CentOS. It is utilized for managing the installation, update, and removal of software on Linux systems. An RPM file contains the software itself, along with metadata about the software such as its version, dependencies, and instructions for installation. This format streamlines the process of software management, providing a standardized approach to handling packages on Linux platforms.
PCAP Format Package
We have released the PCAP Format package for all licenses of Cerbero Suite.
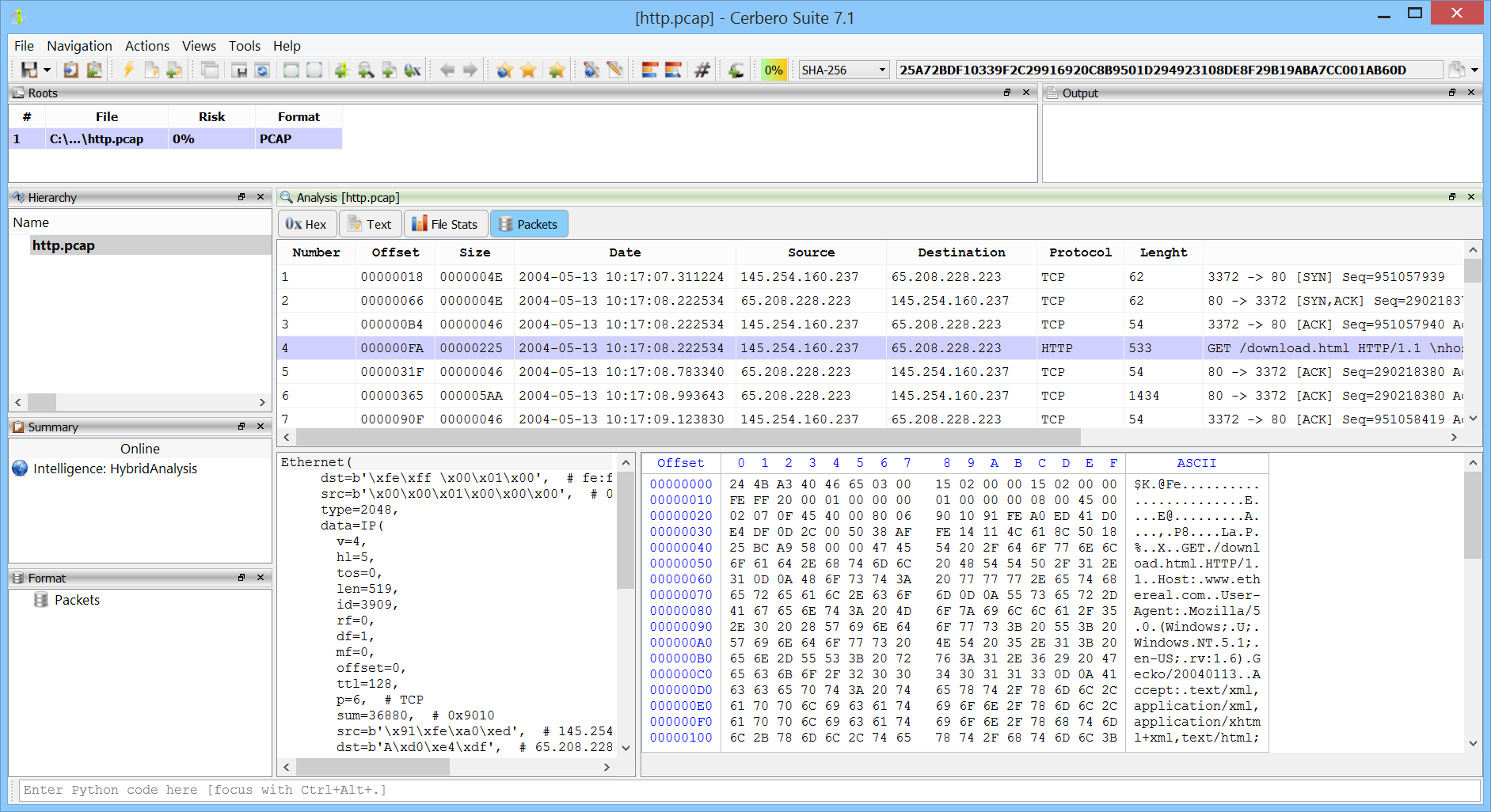
The PCAP format is the main capture file format used in TcpDump/WinDump, snort, and many other networking tools and is fully supported by Wireshark/TShark. Our support does not aim to compete against a specialized tool like WireShark, but it gives the capability to inspect PCAP files without leaving the Cerbero Suite interface. This is especially useful when analyzing malware reports.